
无题
1 | slug: 前端总结 |
开发规范
后端
1 | //message提示 |
参数类型:json对象,application/x-www-form-urlencoded
常用值定义:
- 状态(0开启,1关闭)
table表格传参格式定义,页数,页码
校验方式:后端校验,前端message展示。
错误码规范
增删改查code码,获取表格数据和操作成功的数据返回的code码需要不一致,这样就可以统一的在axios中去message了
查询条件清空变为空字符串如何查询
前端
分支
- 开发同一个组件,需要协调同步,防止代码冲突
开发
开发规范
- 每个页面需要注释这个页面的作用,方法的作用
- api接口方法用/**/注释,才有提示
- 注意后期的维护
代码规范
- 生命周期,布尔值放在开头
- 循环数据过多,不要用框架带的组件,用原生的标签。
接口规范
- 提前和后端定义好数据格式,不然前端写好再去联调,参数不一致加大开发成本
- 重复请求:加节流
- 定义好一些下拉框数据是前端保存还是后端数据库保存
表单
- 表单校验,哪些是必填,提示信息是什么
- 提交成功后需要清空表单数据
- 弹框中表单提交成功后,需要关闭弹框
table
- 查询时页码要置为1
- 修改条数时页码要置为1
- 如果没有分页查询条件,能查询全部数据
逻辑
- 增删改要加提示信息
- 条件联动
- tab切换,查询条件需要重置
- 按钮请求loading(写个公共模块)
- 某些按钮需要根据状态启用和禁用
- 操作成功后,是否需要刷新table
- 注意修改某个地方之后,其他地方是否需要同步修改,最好是能去再走一遍流程
- 添加需求或者某个逻辑的时候要思考一下是否合理。
- 为空时的展示情况
回显
- 树的回显
组件
- 可维护性,可扩展性
- 写代码的时候需要注意,多个页面会有公共的模块可以提出来
- 拒绝同一个业务写多个组件,统一用一个语法,一个组件,同一个图片。防止后期维护他人代码时,影响效率
注意判断条件,前因后果是否符合逻辑
操作表格,是否能分页操作。eg: 表格选择框能选择第二页的数据
当后端没有返回值或者返回是空的话,页面展示什么
规定表单默认值
所有的时间的展示需要判断是否为空
重名导致显示或者逻辑的错误
cookie
iframe嵌入子页面,未登录时子页面会返回一个cookie,登录时会把这个cookie返回给后端校验通过登录成功。
跨域,samesite设置为none
嵌入的页面和窗口下的页面是否共用一个cookie
iframe修改子页面样式,父页面通知子页面,但是子页面还没有加载,需要load。但是就会有延迟,因为必须等子页面加载出来
1
2
3
4
5f.onload = function() {
console.log('iframe loaded');
f.setAttribute('style','display:block')
this.visible=true
};路由导航,涉及二级导航三级导航。浏览器前进后退父子页面路由处理
- 子页面,纯html,前进后退浏览器会有感应
- 如果是单一页面vue/react,浏览器是不会感应到路由的变化,所以需要做优化
登录校验,过期校验
一些技术插件,要评估是否基于插件的功能做,还是扩展插件的功能,不然会导致估计时间问题
技术选型
- 业务上需要哪些功能,插件具有哪些功能
- 要评估是否基于插件的功能做,还是扩展插件的功能,不然会导致估计时间问题
- 扩展性
- 工具是否提供可扩展API
- 包的容量
- 自适应,PC/移动端
- 主题,国际化/语言化
- 使用量,维护更新速度
- 兼容性
- 兼容框架
- 兼容浏览器版本
tip
后端数据不返回,可能是前端的逻辑有问题。比如订单未完成就不能获取到评价内容
注意需要根据用户账号去保持状态
前期调研,是否需要根据需求做公共组件
容器超过高度滚动展示
网络,接口中断,应该展示什么
代码报错是否用try,catch去message出来。防止操作不报错也不反应
是否保持刷新前的状态
- 树形结构,路由是否直接跳转到指定树形id下的页面(配置路由hash)
面试


你在公司做啥
data
阿里云上传图片组件的研发,一个是插件,一个是阿里云链接
下拉框搜索变成输入自定义邮箱后缀。他有搜索事件,和选择事件,通过输入字段不断触发搜索事件,失去焦点之后,执行blur事件,通过循环遍历默认的邮箱后缀来判断是否是自定义的邮箱后缀。最后将自定义的邮箱后缀加到邮箱后缀列表中。
指向问题。react-xarrows,react-draggable。开始的需求是textarea和笑脸图标用箭头符号相连。制作的话可以用svg或者xarrows来制作箭头符号。但是根据上手时间的情况,以及能完美呈现效果还是使用xarrows。根据GitHubxarrows文档,因为需求textarea图标能被拖拽,看到xarrows文档使用draggable配合xarrows拖拽,箭头能保持指向。所以将原来的拖拽功能注释了。遇到箭头指向错误,codesandbox测试是没找到指向对象。应该把Xarrow放在const创建的jsx对象里面。应该就是渲染时候,没找到对象就执行箭头事件了。在文本框拖拽区域的盒子上使用mousemove,事件对象的offsetX/Y是以文本框定位的
在mousedown中修改文本框层级之后,文本框没有触发焦点。mousedown,focus,mouseup,click事件的执行顺序。
g2,label,分行
cisdi
防抖
监听数据没有更新
行车终端,行车系统发送给服务器,后端通过Websocket给到前端。初始化时发送uid,后端存入这个ws对象并绑定这个uid(后端做了检验,判断只会对最早的那一个对应的uid的ws对象发送消息,所以新建立的对象收不到消息)。所以刷新页面的时候需要删除这个通道,还需要传给后端关闭通道的消息。不然,后端发送消息还是会发给旧的ws对象。这里我会在beforeunload把所有绑定的id去做注销,然后在mounted去初始化ws,并发送绑定的行车id
因为只能给唯一一个id绑定,不太符合现实,可以设置uuid设置唯一标识,服务器可以为每个标识绑定的uid发送信息
tag导航栏,路由导航
指令:vue本身是不推荐我们直接操作DOM的,既然你选择了使用vue,尽量考虑可以从数据层面去驱动,另外,DOM的操作是很昂贵的,每次操作DOM都会引起浏览器的重绘,虽然说现在的电脑或者手机的性能已经很好,但是,我猜测没有一个人会建议你大量操作DOM的。你可以看到现在流行的框架VUE、react,都是操作数据而不是直接操作DOM的
tablepane,onresize,height
大地图
- 如何循环渲染库位
- for循环渲染行列(这是因为要定位),再根据后端给的数据循环判断,一个格子就要循环所有的数据。
100*100*100 - 后端返回所有位置,再根据给的数据循环渲染(根据行列定位)
- 偶数列放在线交叉的位置,盒子大小的一半就可以
- for循环渲染行列(这是因为要定位),再根据后端给的数据循环判断,一个格子就要循环所有的数据。
- 组件
- 根据区域封装
- 特殊结构封装
- 库位做一个封装
- 公用模块封装。比如,所有的位置都有钢卷可以做一个封装。运输连的托盘做一个封装
- 性能渲染
- v-show,v-if
- 分片渲染
- 图片
- 如何循环渲染库位
小地图,渲染绿色钢卷。储位和绿色钢卷的接口执行顺序同步。所以有时候显示有时候不显示
bufferarray 和 blob
数字平台
- 审批流程
- 树状
技术点
自定义修饰:vue的stroe,每次拿值都要在get/compute用this.store.xx。可以用自定义修饰去做处理
vue数据嵌套层数未知情况下,我们怎样渲染,
技术
闭包
异步
一些优化的方案
构造函数
react this指向
面向对象
作用域链
设计模式
原理
vue,install
this.$set的原理,https://jishuin.proginn.com/p/763bfbd75fd7
Object.assign方法有很多用处。
(1)为对象添加属性
class Point { constructor(x, y) { Object.assign(this, {x, y}); } } 上面方法通过Object.assign方法,将x属性和y属性添加到Point类的对象实
get获取多层对象,store修改多层对象下的子对象,监听不到变化
Vue.set(state.globalInfo, data.name, data.data);//解决
前端初中高评级
javascript
初级:
- 知道组合寄生继承,知道class继承。
- 知道怎么创建类function + class。
- 知道闭包在实际场景中怎么用,常见的坑。
- 知道模块、组件是什么,怎么用。
- 知道event loop是什么,能举例说明event loop怎么影响平时的编码。
- 掌握基础数据结构,比如堆、栈、树,并了解这些数据结构计算机基础中的作用。
- 知道ES6数组相关方法,比如forEach,map,reduce。
中级:
- 知道class继承与组合寄生继承的差别,并能举例说明。
- 知道event loop原理,知道宏微任务,并且能从个人理解层面说出为什么要区分。知道node和浏览器在实现loop时候的差别。
- 能将继承、作用域、闭包、模块这些概念融汇贯通,并且结合实际例子说明这几个概念怎样结合在一起。
- 能脱口而出2种以上设计模式的核心思想,并结合js语言特性举例或口喷基础实现。
- 掌握一些基础算法核心思想或简单算法问题,比如排序,大数相加。
工程化工具
初级:
- 知道webpack,rollup以及他们适用的场景。
- 知道webpack v3、v4和v5的区别。
- webpack基础配置。
- 知道webpack打包结果的代码结构和执行流程,知道index.js,runtime.js是干嘛的。
- 知道amd,cmd,commonjs,es module分别是什么。
- 知道所有模块化标准定义一个模块怎么写。给出2个文件,能口喷一段代码完成模块打包和执行的核心逻辑
中级:
- 知道webpack打包链路,知道plugin生命周期,知道怎么写一个plugin和loader。
- 知道常见loader做了什么事情,能几句话说明白,比如babel-loader,vue-loader。
- 能结合性能优化聊webpack配置怎么做,能清楚说明白核心要点有哪些,并说明解决什么问题,需要哪些外部依赖,比如cdn,接入层等。
- 了解异步模块加载的实现原理,能口喷代码实现核心逻辑。
高级:
- 项目脚手架搭建,及如何以工具形态共享。
- 工具化打包发布流程,包括本地调试、云构建、线上发布体系、一键部署能力。同时,方案不仅限于前端工程部分,包含相关服务端基础设施,比如cdn服务搭建,接入层缓存方案设计,域名管控等。
React(ng/vue)
react替换为vue或angular同样适用
初级:
- 知道react常见优化方案,脱口而出常用生命周期,知道他们是干什么的。
- 知道react大致实现思路,能对比react和js控制原生dom的差异,能口喷一个简化版的react。
- 知道diff算法大致实现思路。
- 对state和props有自己的使用心得,结合受控组件、hoc等特性描述,需要说明各种方案的适用场景。
中级:
- 能说明白为什么要实现fiber,以及可能带来的坑。
- 能说明白为什么要实现hook。
- 能说明白为什么要用immutable,以及用或者不用的考虑。
- 知道react不常用的特性,比如context,portal。
- 能用自己的理解说明白react like框架的本质,能说明白如何让这些框架共存。
高级:
- 能设计出框架无关的技术架构。包括但不限于:
- 说明如何解决可能存在的冲突问题,需要结合实际案例。
- 能说明架构分层逻辑、各层的核心模块,以及核心模块要解决的问题。能结合实际场景例举一些坑或者优雅的处理方案则更佳。
react生态工具(ng/vue同理)
初级:
- 知道react-router,redux,redux-thunk,react-redux,immutable,antd或同级别社区组件库。(全家桶)
- 知道浏览器react相关插件有什么,怎么用。
- 知道react-router 各个版本的差异。
- 知道antd组件化设计思路。
- 知道thunk干嘛用的,怎么实现的。
中级:
- 看过全家桶源码,不要求每行都看,但是知道核心实现原理和底层依赖。能口喷几行关键代码把对应类库实现即达标。
- 能从数据驱动角度透彻的说明白redux,能够口喷原生js和redux结合要怎么做。
- 能结合redux,vuex,mobx等数据流谈谈自己对vue和react的异同。
高级:
- 有基于全家桶构建复杂应用的经验,比如微前端和这些类库结合的时候要注意什么,会有什么坑,怎么解决
各种Web前端技术
初级:
- HTML方面包括但不限于:语义化标签,history api,storage,ajax2.0等。
- CSS方面包括但不限于:文档流,重绘重排,flex,BFC,IFC,before/after,动画,keyframe,画三角,优先级矩阵等。
- 知道axios或同级别网络请求库,知道axios的核心功能。
- 能口喷xhr用法,知道网络请求相关技术和技术底层,包括但不限于:content-type,不同type的作用;restful设计理念;cors处理方案,以及浏览器和服务端执行流程;口喷文件上传实现;
- 知道如何完成登陆模块,包括但不限于:登陆表单如何实现;cookie登录态维护方案;token base登录态方案;session概念;
中级:
- HTML方面能够结合各个浏览器api描述常用类库的实现。
- css方面能够结合各个概念,说明白网上那些hack方案或优化方案的原理。
- 能说明白接口请求的前后端整体架构和流程,包括:业务代码,浏览器原理,http协议,服务端接入层,rpc服务调用,负载均衡。
- 知道websocket用法,包括但不限于:鉴权,房间分配,心跳机制,重连方案等。
- 知道pc端与移动端登录态维护方案,知道token base登录态实现细节,知道服务端session控制实现,关键字:refresh token。
- 知道oauth2.0轻量与完整实现原理。
- 知道移动端api请求与socket如何通过native发送,知道如何与native进行数据交互,知道ios与安卓jsbridge实现原理。
eslint的使用
ts的使用
浏览器的一些使用和原理
学习资源和路径
浏览器
浏览器渲染机制
https://mp.weixin.qq.com/s/fUduX-AA618rsE3HHWySgA
https://mp.weixin.qq.com/s/cqlhO6N8pGCjNkdHNSio4g
进程
进程和线程的概念可以这样理解:
- 进程是一个工厂,工厂有它的独立资源
- 工厂之间相互独立
- 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人
- 工人之间共享空间
- 工厂的资源 -> 系统分配的内存(独立的一块内存)
- 工厂之间的相互独立 -> 进程之间相互独立
- 多个工人协作完成任务 -> 多个线程在进程中协作完成任务
- 工厂内有一个或多个工人 -> 一个进程由一个或多个线程组成
- 工人之间共享空间 -> 同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)
进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位,系统会给它分配内存)
线程是cpu调试的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程。核心还是属于一个进程。)
浏览器是多进程的
浏览器是多进程的,每打开一个tab页,就相当于创建了一个独立的浏览器进程。
浏览器包含的进程
Browser进程:浏览器的主进程(负责协调,主控),只有一个,作用有:- 负责浏览器的界面显示,与用户交互,如前进,后退等
- 负责各个页面的管理,创建和销毁其它进程
- 将
Rendered进程得到的内存中的Bitmap,绘制到用户界面上 - 网络资源的管理,下载
- 第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建。
GPU进程:最多一个,用于3D绘制等。- 浏览器渲染进程(浏览器内核)(
Render进程,内部是多线程的):默认每个Tab页面一个进程,互不影响。主要作用为:页面渲染,脚本执行,事件处理等
在浏览器中打开一个网页相当于新起了一个进程(进程内有自己的多线程)
浏览器有时会将多个进程合并(譬如打开多个空白标签页后,会发现多个空白标签页被合并成了一个进程),如图
浏览器多进程的优势
- 避免单个
page crash影响整个浏览器 - 避免第三方插件
crash影响整个浏览器 - 多进程充分利用多核优势
- 方便使用沙盒模型隔离插件等进程,提高浏览器稳定性
简单理解就是:如果浏览器是单进程的,某个Tab页崩溃了,就影响了整个浏览器,体验就会很差。同理如果是单进程的,插件崩溃了也会影响整个浏览器; 当然,内存等资源消耗也会更大,像空间换时间一样。
浏览器内核(渲染进程)
浏览器内核:浏览器所采用的渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。
Trident内核:IE,MaxThon,TT,The World,360,搜狗浏览器等。Gecko内核:Netscape6及以 上版本,FF,MozillaSuite/SeaMonkey等Presto内核:Opera7及以上。 [Opera内核原为:Presto,现为:Blink;]Webkit内核:Safari,Chrome等。 [Chrome的Blink(WebKit的分支)]
浏览器是多进程的,浏览器的渲染进程是多线程的(浏览器的内核是多线程的);
渲染进程如下:
虽然JavaScript是单线程的,可是浏览器内部不是单线程的。一些I/O操作、定时器的计时和事件监听(click, keydown…)等都是由浏览器提供的其他线程来完成的。
GUI渲染线程
- 负责渲染浏览器界面,解析
HTML,CSS,构建DOM树和RenderObject树,布局和绘制等。 - 当界面需要重绘或由于某种操作引发回流时,该线程就会执行。
- 注意,**
GUI渲染线程与JS引擎线程是互斥的**,当JS引擎执行时GUI线程会被挂起(相当于冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。
由于JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JS线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JS引擎为互斥的关系,当JS引擎执行时GUI线程会被挂起, GUI更新则会被保存在一个队列中等到JS引擎线程空闲时立即被执行。
JS引擎线程
javascript是单线程的, 假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点。所以javascript是单线程的。
- 也称为
JS内核,负责处理JavaScript脚本程序。(例如V8引擎)。 JS引擎线程负责解析JavaScript脚本,运行代码。JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(render进程)中无论什么时候都只有一个JS线程在运行JS程序。- GUI渲染线程与JS引擎线程是互斥的,所以如果
JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
事件触发线程
- 归属于浏览器而不是
JS引擎,用来控制事件循环(可以理解成JS引擎自己都忙不过来,需要浏览器另开线程协助)。 - 当
JS引擎执行代码块如setTimeout时(也可来自浏览器内核的其它线程,如鼠标点击,AJAX异步请求等),会将对应任务添加到事件线程中。 - 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待
JS引擎的处理。 - 注意,由于
JS的单线程关系,所以这些待处理队列中的事件都得排队等待JS引擎处理(当JS引擎空闲时才会去执行)。
定时触发器线程
- 传说中的
setTimeout和setInterval所在的线程 - 浏览器定时计数器并不是由
JavaScript引擎计数的,(因为JavaScript引擎是单线程的,如果处于阻塞线程状态就会影响计时的准确) - 因此通过单独线程来计时并触发定时(计时完毕后,添加到事件队列中,等待
JS引擎空闲后执行) - 注意,
W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms。
异步http请求线程
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中。再由JavaScript引擎执行
渲染流程
浏览器主进程
浏览器输入url,浏览器主进程接管,开一个下载线程,然后进行 http请求(略去DNS查询,IP寻址等等操作),然后等待响应,获取内容,随后将内容通过RendererHost接口转交给Renderer进程
浏览器渲染进程
基础版本
浏览器内核拿到响应报文之后,渲染大概分为以下步骤
- 解析html生产DOM树。
- 解析CSS规则。
- 根据DOM Tree和CSS Tree生成Render Tree。
- 根据Render树进行layout,负责各个元素节点的尺寸、位置计算。
- 绘制Render树(painting),绘制页面像素信息。
- 浏览器会将各层的信息发送给GPU,GPU会将各层合成(composite),显示在屏幕上。
详细版
在浏览器地址栏输入URL
浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
如果资源未缓存,发起新请求
如果已缓存,检验是否足够新鲜,足够新鲜直接提供给客户端,否则与服务器进行验证。
检验新鲜通常有两个HTTP头进行控制
Expires和Cache-Control:
- HTTP1.0提供Expires,值为一个绝对时间表示缓存新鲜日期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大新鲜时间
浏览器解析URL获取协议,主机,端口,path
浏览器获取主机ip地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
浏览器组装一个HTTP(GET)请求报文
打开一个socket与目标IP地址,端口建立TCP链接
三次握手如下:
- 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
TCP链接建立后发送HTTP请求
服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
服务器将响应报文通过TCP连接发送回浏览器
浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次握手如下
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y, Seq=X报文
浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
如果资源可缓存,进行缓存
对响应进行解码(例如gzip压缩)
根据资源类型决定如何处理(假设资源为HTML文档)
解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
解析过程中遇到图片、样式表、js文件,启动下载
构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
-
从DOM树的根节点遍历所有可见节点,不可见节点包括:
1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如
display: none对每一个可见节点,找到恰当的CSSOM规则并应用
发布可视节点的内容和计算样式
名词解释
- DOM Tree: 浏览器将HTML解析成树形的数据结构。
- CSS Rule Tree:浏览器将CSS解析成树形的数据结构。
- Render Tree:DOM树和CSS规则树合并后生产Render树。
- layout:有了Render Tree,浏览器已经能知道网页中有哪些节点、各个节点的CSS定义以及他们的从属关系,从而去计算出每个节点在屏幕中的位置。
- painting: 按照算出来的规则,通过显卡,把内容画到屏幕上。
- 重排(重构/回流/reflow):当浏览器发现某个部分发生了点变化影响了布局,需要倒回去重新渲染,内行称这个回退的过程叫
reflow。reflow 会从 这个 root frame 开始递归往下,依次计算所有的结点几何尺寸和位置。reflow 几乎是无法避免的。现在界面上流行的一些效果,比如树状目录的折叠、展开(实质上是元素的显 示与隐藏)等,都将引起浏览器的 reflow。鼠标滑过、点击……只要这些行为引起了页面上某些元素的占位面积、定位方式、边距等属性的变化,都会引起它内部、周围甚至整个页面的重新渲 染。通常我们都无法预估浏览器到底会 reflow 哪一部分的代码,它们都彼此相互影响着。 - 重绘(repaint或redraw):改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性时,屏幕的一部分要重画,但是元素的几何尺寸没有变。重排必定会引发重绘,但重绘不一定会引发重排。
普通图层和复合图层
浏览器渲染的图层一般包含两大类:渲染图层(普通图层)以及复合图层
渲染图层:是页面普通的文档流。无论添加多少元素,还在在同一个默认复合层。 虽然绝对定位(absolute),相对定位(fixed),浮动定位(float)会让元素成为脱离文档流,但它仍然属于默认复合层,共用同一个绘图上下文对象(GraphicsContext)。
复合图层,又称图形层。它会单独分配系统资源,每个复合图层都有一个独立的GraphicsContext。(当然也会脱离普通文档流,这样一来,不管这个复合图层中怎么变化,也不会影响默认复合层里的回流Reflow重绘Repaint)
通过硬件加速就可以使渲染图层提升为复合图层,GPU中,各个复合图层是单独绘制的,所以互不影响
将元素变成一个复合图层,就是传说中的硬件加速技术
最常用的方式:
translate3d,translatezopacity属性/过渡动画(需要动画执行的过程中才会创建合成层,动画没有开始或结束后元素还会回到之前的状态)will-chang属性(这个比较偏僻),一般配合opacity与translate使用(而且经测试,除了上述可以引发硬件加速的属性外,其它属性并不会变成复合层),作用是提前告诉浏览器要变化,这样浏览器会开始做一些优化工作(这个最好用完后就释放)```
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
- 其它,譬如以前的`flash`插件
**复合图层的作用**
一般一个元素开启硬件加速后会变成复合图层,可以独立于普通文档流中,改动后可以避免整个页面重绘,提升性能。但是尽量不要大量使用复合图层,否则由于资源消耗过度,页面反而会变的更卡。
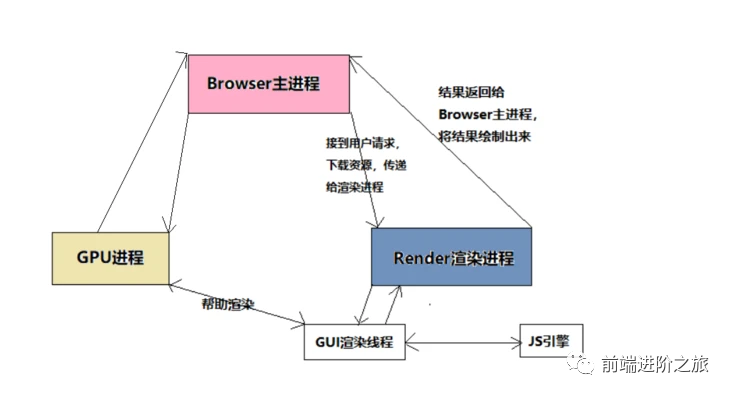
### Browser主进程和渲染进程的通信
打开一个浏览器,可以看到:任务管理器出现了2个进程(一个主进程,一个是打开`Tab`页的渲染进程)
- `Browser`主进程收到用户请求,首先需要获取页面内容(如通过网络下载资源),随后将该任务通过`RendererHost`接口传递给`Render`渲染进程
- `Render`渲染进程的`Renderer`接口收到消息,简单解释后,交给渲染线程`GUI`,然后开始渲染
- `GUI`渲染线程接收请求,加载网页并渲染网页,这其中可能需要`Browser`主进程获取资源和需要`GPU`进程来帮助渲染
- 当然可能会有`JS`线程操作`DOM`(这可能会造成回流并重绘)
- 最后`Render`渲染进程将结果传递给`Browser`主进程
- `Browser`主进程接收到结果并将结果绘制出来
### JS的多线程WebWorker
`JS`引擎是单线程的,而且`JS`执行时间过长会阻塞页面,那么`JS`就真的对`cpu`密集型计算无能为力么?
所以,后来`HTML5`中支持了`WebWorker`。
来自MDN的官方解释
> Web Worker为Web内容在后台线程中运行脚本提供了一种简单的方法。线程可以执行任务而不干扰用户界面
>
> 一个worker是使用一个构造函数创建的一个对象(e.g. Worker()) 运行一个命名的JavaScript文件
>
> 这个文件包含将在工作线程中运行的代码; workers 运行在另一个全局上下文中,不同于当前的window
>
> 因此,使用 window快捷方式获取当前全局的范围 (而不是self) 在一个 Worker 内将返回错误
这样理解下:
- 创建Worker时,JS引擎向浏览器申请开一个子线程**(子线程是浏览器开的,完全受主线程控制,而且不能操作DOM)**
- JS引擎线程与worker线程间通过特定的方式通信(postMessage API,需要通过序列化对象来与线程交互特定的数据)
所以,如果需要进行一些高耗时的计算时,可以单独开启一个WebWorker线程,这样不管这个WebWorker子线程怎么密集计算、怎么阻塞,都不会影响JS引擎主线程,只需要等计算结束,将结果通过postMessage传输给主线程就可以了。
而且注意下,JS引擎是单线程的,这一点的本质仍然未改变,Worker可以理解是浏览器给JS引擎开的外挂,专门用来解决那些大量计算问题。
**`WebWorker`与`SharedWorker`**
既然都到了这里,就再提一下`SharedWorker`(避免后续将这两个概念搞混)
- WebWorker只属于某个页面,不会和其他页面的Render进程(浏览器内核进程)共享
- - 所以Chrome在Render进程中(每一个Tab页就是一个render进程)创建一个新的线程来运行Worker中的JavaScript程序。
- SharedWorker是浏览器所有页面共享的,不能采用与Worker同样的方式实现,因为它不隶属于某个Render进程,可以为多个Render进程共享使用
- 所以Chrome浏览器为SharedWorker单独创建一个进程来运行JavaScript程序,在浏览器中每个相同的JavaScript只存在一个SharedWorker进程,不管它被创建多少次。
看到这里,应该就很容易明白了,本质上就是进程和线程的区别。SharedWorker由独立的进程管理,WebWorker只是属于render进程下的一个线程
### Event Loop事件循环机制
事件触发线程去执行事件循环机制
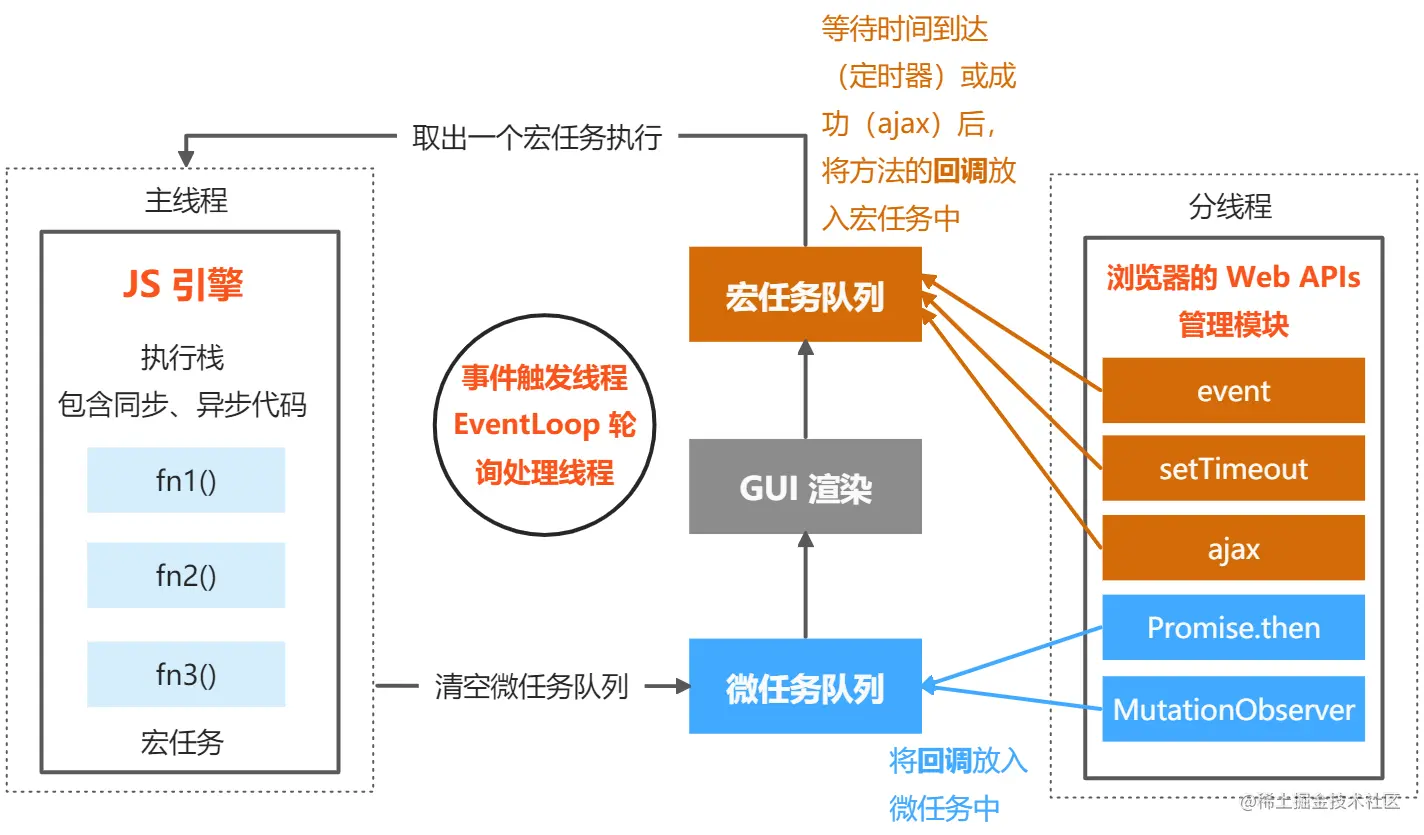
#### Event Loop目的
`Event Loop`即事件循环,是指浏览器或`Node`的一种**解决`javaScript`单线程运行时不会阻塞的**一种机制,也就是我们经常使用**异步**的原理。
单线程是必要的,如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
#### macrotask与microtask
在ECMAScript中,macrotask可称为`task`,microtask称为`jobs`
**MacroTask(宏任务)**:script(整体代码)
setTimeout
setInterval
nodejs的setImmediate
网络I/O、文件I/O
UI渲染事件(DOM解析、布局计算、绘制)
MessageChannel(react的fiber用到)
postMessage
requestAnimationFrame
宿主环境:node、浏览器
1 |
|
process.nextTick
Promise
Async/Await(实际就是promise)
MutationObserver(html5新特性
1 |
|
function add(x, y) {
var z = x+y
return z
}
console.log(add(1, 2))
1 |
|
Program = All SourceFile + CompilerOptions
1 |
|
main.js 创建了一个按钮,并绑定了点击事件
1 | let button = document.createElement('button'); |
script.js 只是简单的打印了一下
1 | console.log('script run'); |
预取资源

script.js被 fetch 下来,size 列的两个数字,275 B 表示下载的字节大小,0 B 表示解析的字节大小(即目前并没有解析)- 控制台是空的,即脚本没有运行
点击页面上的 Add Script,会在页面增加地址为 script.js 的 <script> 标签,此时网络选项卡会增加以下内容

- 下载字节量为
(prefetch cache),即直接从预取缓存获取资源,下面的解析后的字节不再为 0 - 控制台打印出脚本中的调试内容,即这时脚本才被解析并运
预加载资源
将 prefetch.html 的 link 标签的 prefetch 改为 preload,并增加资源类型 as 为 script,即得 preload.html
1 | <link rel="preload" href="script.js" as="script"> |

script.js被优先下载, size 列的解压字节不再为 0,即preload除了把脚本下载了下来,还进行了解析- 控制台目前仍为空,即脚本虽然被解析,但并没有运行。
点击 Add Script,网络选项卡并没有增加任何记录,但是控制台输出了脚本的打印内容
- 因为脚本已经解析完成,所以连从缓存获取都不需要了,直接运行即可
- 如果没有在 3 秒内点击
Add Script,控制台会进行警告,因为没有及时使用应该优先加载的资源
The resource https://chanvinxiao.com/demo/html/script.js was preloaded using link preload but not used within a few seconds from the window’s load event. Please make sure it has an appropriate
asvalue and it is preloaded intentionally.
网络与安全
URI和URL
URL
统一资源定位符(Uniform Resource Locator,缩写:URL),是对资源(web上每一种可用的资源,如 HTML文档、图像、视频片段、程序)的引用和访问该资源的方法。俗称网址。
一个 URL 由以下不同的部分组成:
协议:通常是 https 或 http,一种告诉浏览器或者设备如何访问资源的方法,当然还有其他的协议,如 ftp 、mailto 或者 file。接下来是 :// 。主机名:表示 IP 地址的注册名称(域名) 或 IP 地址,用于识别连接到网络的设备的数字标识符。后面是可选的端口好,前面是冒号 : 。路径:可以引用文件系统路径,通常作为一个代码段使用。参数:以问号开头的可选查询参数,其中多个参数用 & 连接hash:用于为页面上的标题提供快速链接,如锚点链接。上面是 URL 组成部份的简介,为了更加直观,如下图所示:

URI
统一资源标志符(Uniform Resource Identifier, URI),表示能把一个资源独一无二地标识出来。
URI通常由三部分组成:
①资源的命名机制;
②存放资源的主机名;
③资源自身的名称。
注意:这只是一般URI资源的命名方式,只要是可以唯一标识资源的都被称为URI,上面三条合在一起是URI的充分不必要条件
其实URL和URI的差异就是一个子集的关系,如下图:

HTTP
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。 HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
HTTP三点注意事项:
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。无状态协议,即:服务器不需要知道客户端是谁,只认请求(一次请求request,一次相应response)

请求协议的格式如下:
- 请求首行
- 请求方式
- 请求路径
- 协议和版本,
- 例如:GET/index.html HTTP/1.1
- 请求头信息
- 键值对格式 =》请求头名称:请求头内容,
- 即,例如:Host:localhost
- 空行;用来与请求体分隔开
- 请求体。GET没有请求体,只有POST有请求体。
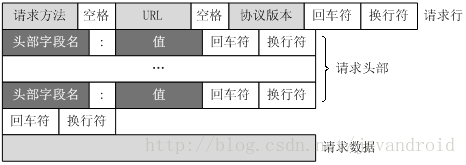
HTTP请求响应报文
HTTP协议使用TCP协议进行传输,在应用层协议发起交互之前,首先是TCP的三次握手。完成了TCP三次握手后,客户端会向服务器发出一个请求报文
请求报文
HTTP 请求报文由3部分组成(请求行+请求头+请求体)

Query Params:常用是get方式请求,query是指请求行中请求的参数,一般是指URL中?后面的参数
Body Params:常用是post方式请求,body是指请求体中的数据
响应报文
响应报文与请求报文一样,由三个部分组成(响应行,响应头,响应体)

请求头和响应头
请求头
keep-alive
由于TCP的可靠性,每条独立的TCP连接都会进行一次三次握手,从上面的Network的分析中可以得到握手往往会消耗大部分时间,真正的数据传输反而会少一些(当然取决于内容多少)。HTTP1.0和HTTP1.1为了解决这个问题在header中加入了Connection: Keep-Alive,keep-alive的连接会保持一段时间不断开,后续的请求都会复用这一条TCP,不过由于管道化的原因也会发生队头阻塞的问题。HTTP1.1默认开启Keep-Alive,HTTP1.0可能现在不多见了,如果你还在用,可以升级一下版本,或者带上这个header。connection keep-alive
| 协议头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 |
Accept: text/plain |
固定 |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 |
固定 |
| Accept-Encoding | 可接受的响应内容的编码方式。 | Accept-Encoding: gzip, deflate |
固定 |
| Accept-Language | 可接受的响应内容语言列表。 | Accept-Language: en-US |
固定 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 | Accept-Datetime: Sat, 26 Dec 2015 17:30:00 GMT | 临时 |
| Authorization | 用于表示HTTP协议中需要认证资源的认证信息 | Authorization: Basic OSdjJGRpbjpvcGVuIANlc2SdDE== | 固定 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 | Cache-Control: no-cache max-age:缓存无法返回缓存时间长于max-age规定秒的文档 |
固定 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive``Connection: Upgrade |
固定 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie |
Cookie: $Version=1; Skin=new; |
固定:标准 |
| Content-Length | 以8进制表示的请求体的长度 | Content-Length: 348 |
固定 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 | Content-MD5: oD8dH2sgSW50ZWdyaIEd9D== | 废弃 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) | Content-Type: application/x-www-form-urlencoded | 固定 |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的”HTTP日期”格式来发送) | Date: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Expect | 表示客户端要求服务器做出特定的行为 | Expect: 100-continue |
固定 |
| From | 发起此请求的用户的邮件地址 | From: user@itbilu.com |
固定 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 | Host: www.itbilu.com:80``Host: www.itbilu.com |
固定 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 | If-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Modified-Since | 把浏览器端缓存页面的最后修改时间发送到服务器去,服务器会把这个时间与服务器上实际文件的最后修改时间进行对比。如果时间一致,那么返回304,客户端就直接使用本地缓存文件。如果时间不一致,就会返回200和新的文件内容。客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示在浏览器中. | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| If-None-Match | If-None-Match和ETag一起工作,工作原理是在HTTP Response中添加ETag信息。 当用户再次请求该资源时,将在HTTP Request 中加入If-None-Match信息(ETag的值)。如果服务器验证资源的ETag没有改变(该资源没有更新),将返回一个304状态告诉客户端使用本地缓存文件。否则将返回200状态和新的资源和Etag. 使用这样的机制将提高网站的性能 | If-None-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 | If-Range: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
固定 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 |
Origin: http://www.itbilu.com |
固定: 标准 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 | Pragma: no-cache |
固定 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 | Proxy-Authorization: Basic IOoDZRgDOi0vcGVuIHNlNidJi2== | 固定 |
| Range | 表示请求某个实体的一部分,字节偏移以0开始。 | Range: bytes=500-999 |
固定 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 |
Referer: http://itbilu.com/nodejs | 固定 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用”trailers”表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 |
TE: trailers,deflate |
固定 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… |
固定 |
| Upgrade | 要求服务器升级到一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) | 固定 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
响应头
| 响应头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Access-Control-Allow-Origin | 指定哪些网站可以跨域源资源共享 |
Access-Control-Allow-Origin: * |
临时 |
| Accept-Patch | 指定服务器所支持的文档补丁格式 | Accept-Patch: text/example;charset=utf-8 | 固定 |
| Accept-Ranges | 服务器所支持的内容范围 | Accept-Ranges: bytes |
固定 |
| Age | 响应对象在代理缓存中存在的时间,以秒为单位 | Age: 12 |
固定 |
| Allow | 对于特定资源的有效动作; | Allow: GET, HEAD |
固定 |
| Cache-Control | 通知从服务器到客户端内的所有缓存机制,表示它们是否可以缓存这个对象及缓存有效时间。其单位为秒 | Cache-Control: max-age=3600 |
固定 |
| Connection | 针对该连接所预期的选项 | Connection: close |
固定 |
| Content-Disposition | 对已知MIME类型资源的描述,浏览器可以根据这个响应头决定是对返回资源的动作,如:将其下载或是打开。 | Content-Disposition: attachment; filename=”fname.ext” | 固定 |
| Content-Encoding | 响应资源所使用的编码类型。 | Content-Encoding: gzip |
固定 |
| Content-Language | 响就内容所使用的语言 | Content-Language: zh-cn |
固定 |
| Content-Length | 响应消息体的长度,用8进制字节表示 | Content-Length: 348 |
固定 |
| Content-Location | 所返回的数据的一个候选位置 | Content-Location: /index.htm |
固定 |
| Content-MD5 | 响应内容的二进制 MD5 散列值,以 Base64 方式编码 | Content-MD5: IDK0iSsgSW50ZWd0DiJUi== | 已淘汰 |
| Content-Range | 如果是响应部分消息,表示属于完整消息的哪个部分 | Content-Range: bytes 21010-47021/47022 | 固定 |
| Content-Type | 当前内容的MIME类型 |
Content-Type: text/html; charset=utf-8 | 固定 |
| Date | 此条消息被发送时的日期和时间(以RFC 7231中定义的”HTTP日期”格式来表示) | Date: Tue, 15 Nov 1994 08:12:31 GMT | 固定 |
| ETag | 对于某个资源的某个特定版本的一个标识符,通常是一个 消息散列 | ETag: “737060cd8c284d8af7ad3082f209582d” | 固定 |
| Expires | 指定一个日期/时间,超过该时间则认为此回应已经过期 | Expires: Thu, 01 Dec 1994 16:00:00 GMT | 固定: 标准 |
| Last-Modified | 所请求的对象的最后修改日期(按照 RFC 7231 中定义的“超文本传输协议日期”格式来表示) | Last-Modified: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Link | 用来表示与另一个资源之间的类型关系,此类型关系是在RFC 5988中定义 | Link:; rel=”alternate” |
固定 |
| Location | 用于在进行重定向,或在创建了某个新资源时使用。 | Location: http://www.itbilu.com/nodejs | 固定 |
| P3P | P3P策略相关设置 | P3P: CP=”This is not a P3P policy! | 固定 |
| Pragma | 与具体的实现相关,这些响应头可能在请求/回应链中的不同时候产生不同的效果 | Pragma: no-cache |
固定 |
| Proxy-Authenticate | 要求在访问代理时提供身份认证信息。 | Proxy-Authenticate: Basic |
固定 |
| Public-Key-Pins | 用于防止中间攻击,声明网站认证中传输层安全协议的证书散列值 | Public-Key-Pins: max-age=2592000; pin-sha256=”……”; | 固定 |
| Refresh | 用于重定向,或者当一个新的资源被创建时。默认会在5秒后刷新重定向。 | Refresh: 5; url=http://itbilu.com | |
| Retry-After | 如果某个实体临时不可用,那么此协议头用于告知客户端稍后重试。其值可以是一个特定的时间段(以秒为单位)或一个超文本传输协议日期。 | 示例1:Retry-After: 120示例2: Retry-After: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Server | 服务器的名称 | Server: nginx/1.6.3 |
固定 |
| Set-Cookie | 设置HTTP cookie |
Set-Cookie: UserID=itbilu; Max-Age=3600; Version=1 | 固定标准 |
| Status | 通用网关接口的响应头字段,用来说明当前HTTP连接的响应状态。 | Status: 200 OK |
|
| Trailer | Trailer用户说明传输中分块编码的编码信息 |
Trailer: Max-Forwards |
固定 |
| Transfer-Encoding | 用表示实体传输给用户的编码形式。包括:chunked、compress、 deflate、gzip、identity。 |
Transfer-Encoding: chunked | 固定 |
| Upgrade | 要求客户端升级到另一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Vary | 告知下游的代理服务器,应当如何对以后的请求协议头进行匹配,以决定是否可使用已缓存的响应内容而不是重新从原服务器请求新的内容。 | Vary: * |
固定 |
| Via | 告知代理服务器的客户端,当前响应是通过什么途径发送的。 | Via: 1.0 fred, 1.1 itbilu.com (nginx/1.6.3) | 固定 |
| Warning | 一般性警告,告知在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
| WWW-Authenticate | 表示在请求获取这个实体时应当使用的认证模式。 | WWW-Authenticate: Basic |
固定 |
状态码
1XX:信息状态码
100 Continue继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
2XX:成功状态码
200 OK 请求成功。一般用于GET与POST请求 201 Created 已创建。成功请求并创建了新的资源 202 Accepted 已接受。已经接受请求,但未处理完成 203 Non-Authoritative Information 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 204 No Content 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 205 Reset Content 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 206 Partial Content 部分内容。服务器成功处理了部分GET请求 3XX:重定向
300 Multiple Choices 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 301 Moved Permanently 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 302 Found 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI 303 See Other 查看其它地址。与301类似。使用GET和POST请求查看 304 Not Modified 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 305 Use Proxy 使用代理。所请求的资源必须通过代理访问 306 Unused 已经被废弃的HTTP状态码 307 Temporary Redirect 临时重定向。与302类似。使用GET请求重定向 4XX:客户端错误
400 Bad Request 客户端请求的语法错误,服务器无法理解 401 Unauthorized 请求要求用户的身份认证 402 Payment Required 保留,将来使用 403 Forbidden 服务器理解请求客户端的请求,但是拒绝执行此请求 404 Not Found 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面 5XX:服务器错误
500 Internal Server Error 服务器内部错误,无法完成请求 501 Not Implemented 服务器不支持请求的功能,无法完成请求 502 Bad Gateway 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 503 Service Unavailable 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中。服务器的问题,找网管 504 Gateway Time-out 充当网关或代理的服务器,未及时从远端服务器获取请求 505 HTTP Version not supported 服务器不支持请求的HTTP协议的版本,无法完成处理
HTTP2
多路复用
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。 多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。多路复用通过更小的二进制帧构成多条数据流,交错的请求和响应可以并行传输而不被阻塞,这样就解决了HTTP1.1时复用会产生的队头阻塞的问题
队头堵塞:
队头阻塞是由 HTTP 基本的“请求 - 应答”模型所导致的。HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。队列里的请求是没有优先级的,只有入队的先后顺序,排在最前面的请求会被最优先处理。如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本,造成了队头堵塞的现象。
首部压缩
HTTP2有首部压缩的功能,如果两个请求首部(headers)相同,那么会省去这一部分,只传输不同的首部字段,进一步减少请求的体积。
1 | // 请求1 |
从上面两个请求可以看出来,有很多数据都是重复的。如果可以把相同的首部存储起来,仅发送它们之间不同的部分,就可以节省不少的流量,加快请求的时间。
HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。
下面再来看一个简化的例子,假设客户端按顺序发送如下请求首部:
1 | Header1:foo |
当客户端发送请求时,它会根据首部值创建一张表:
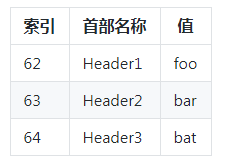
如果服务器收到了请求,它会照样创建一张表。 当客户端发送下一个请求的时候,如果首部相同,它可以直接发送这样的首部块:
1 | 62 63 64 |
服务器会查找先前建立的表格,并把这些数字还原成索引对应的完整首部。
优先级
HTTP2 可以对比较紧急的请求设置一个较高的优先级,服务器在收到这样的请求后,可以优先处理。
流量控制
由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少。流量控制可以对不同的流的流量进行精确控制。
服务器推送
HTTP2 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确地请求。
例如当浏览器请求一个网站时,除了返回 HTML 页面外,服务器还可以根据 HTML 页面中的资源的 URL,来提前推送资源。
HTTPS协议
超文本传输安全协议(Hypertext Transfer Protocol Secure,简称:HTTPS)是一种通过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,利用SSL/TLS来加密数据包。HTTPS的主要目的是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。
HTTP协议采用明文传输信息,存在信息窃听、信息篡改和信息劫持的风险,而协议TLS/SSL具有身份验证、信息加密和完整性校验的功能,可以避免此类问题发生。
不同HTTP的协议
HTTP和HTTPS协议的区别
- HTTS协议需要CA证书,费用较高;而HTTP协议不需要;
- HTTP协议是超文本传输协议,信息是明文传输的,HTTPS则是具有安全性的SSL加密传输协议;
- 使用不同的连接方式,端口也不同,HTTP协议端口是80,HTTPS协议端口是443;
- HTTP协议连接很简单,是无状态的;HTTPS协议是有SSL和HTTP协议构建的可进行加密传输、身份认证的网络协议,比HTTP更加安全。
HTTP 1.0和 HTTP 1.1 有以下区别
- 连接方面,http1.0 默认使用非持久连接,而 http1.1 默认使用持久连接。http1.1 通过使用持久连接来使多个 http 请求复用同一个 TCP 连接,以此来避免使用非持久连接时每次需要建立连接的时延。
- 资源请求方面,在 http1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,http1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 缓存方面,在 http1.0 中主要使用 header 里的 If-Modified-Since、Expires 来做为缓存判断的标准,http1.1 则引入了更多的缓存控制策略,例如 Etag、If-Unmodified-Since、If-Match、If-None-Match 等更多可供选择的缓存头来控制缓存策略。
- http1.1 中新增了 host 字段,用来指定服务器的域名。http1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个IP地址。因此有了 host 字段,这样就可以将请求发往到同一台服务器上的不同网站。
- http1.1 相对于 http1.0 还新增了很多请求方法,如 PUT、HEAD、OPTIONS 等。
HTTP 1.1 和 HTTP 2.0 的区别
二进制协议:HTTP/2 是一个二进制协议。在 HTTP/1.1 版中,报文的头信息必须是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为”帧”,可以分为头信息帧和数据帧。 帧的概念是它实现多路复用的基础。
多路复用: HTTP/2 实现了多路复用,HTTP/2 仍然复用 TCP 连接,但是在一个连接里,客户端和服务器都可以同时发送多个请求或回应,而且不用按照顺序一一发送,这样就避免了”队头堵塞”【1】的问题。
数据流: HTTP/2 使用了数据流的概念,因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的请求。因此,必须要对数据包做标记,指出它属于哪个请求。HTTP/2 将每个请求或回应的所有数据包,称为一个数据流。每个数据流都有一个独一无二的编号。数据包发送时,都必须标记数据流 ID ,用来区分它属于哪个数据流。
头信息压缩: HTTP/2 实现了头信息压缩,由于 HTTP 1.1 协议不带状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如 Cookie 和 User Agent ,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。HTTP/2 对这一点做了优化,引入了头信息压缩机制。一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就能提高速度了。
服务器推送: HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送。使用服务器推送提前给客户端推送必要的资源,这样就可以相对减少一些延迟时间。这里需要注意的是 http2 下服务器主动推送的是静态资源,和 WebSocket 以及使用 SSE 等方式向客户端发送即时数据的推送是不同的。
它主机功能, 它允许用户登录internet主机,并在这台主机上执行命令;
网络管理(SMTP简单网络管理协议),该协议提供了监控网络设备的方法, 以及配置管理,统计信息收集,性能管理及安全管理等;
域名系统(DNS),主机的域名到 IP 地址的映射
域名解析的顺序:
浏览器缓存;
找本机的hosts文件;
路由缓存;
找DNS服务器(本地域名、顶级域名、根域名)->迭代解析、递归查询。
顶级域(com,cn,net,gov,org)、二级域(baidu,taobao,qq,alibaba)、三级域(www)(12-2-0852)。
缓存
https://louiszhai.github.io/2017/04/07/http-cache/
缓存通过复用之前的获取过的资源,可以显著提高网站和应用程序的性能,合理的缓存不仅可以节省巨大的流量也会让用户二次进入时身心愉悦,如果一个资源完全走了本地缓存,那么就可以节省下整个与服务器交互的时间,如果整个网站的内容都被缓存在本地,那即使离线也可以继续访问(很酷,但还没有完全很酷)。HTTP缓存主要分为两种,一种是强缓存,另一种是协商缓存,都通过Headers控制。整体流程如下:


强缓存
本地缓存阶段(也称强缓存)
先在本地查找该资源,如果有发现该资源,而且该资源还没有过期,就使用这一个资源,不会发起任何网络请求;
Expires(该字段是http1.0时的规范,值为一个绝对时间的GMT格式的时间字符串,代表缓存资源的过期时间)Cache-Control:max-age(该字段是http1.1的规范,强缓存利用其max-age值来判断缓存资源的最大生命周期,它的值单位为秒)1
2
3
4
5
6
7Cache-Control: max-age=<seconds>
Cache-Control: max-stale[=<seconds>]
Cache-Control: min-fresh=<seconds>
Cache-control: no-cache
Cache-control: no-store
Cache-control: no-transform
Cache-control: only-if-cached
如 果max-age和Expires同时出现,则max-age有更高的优先级。
常用的有max-age,no-cache和no-store。max-age 是资源从响应开始计时的最大新鲜时间,一般响应中还会出现age标明这个资源当前的新鲜程度。no-cache 会让浏览器缓存这个文件到本地但是不用,Network中disable-cache勾中的话就会在请求时带上这个haader,会在下一次新鲜度验证通过后使用这个缓存。no-store 会完全放弃缓存这个文件。服务器响应时的Cache-Control略有不同,其中有两个需要注意下:
- public, public 表明这个请求可以被任何对象缓存,代理/CDN等中间商。
- private,private 表明这个请求只能被终端缓存,不允许代理或者CDN等中间商缓存。
Expires是一个具体的日期,到了那个日期就会让这个缓存失活,优先级较低,存在max-age的情况下会被忽略,和本地时间绑定,修改本地时间可以绕过。另外,如果你的服务器的返回内容中不存在Expires,Cache-Control: max-age,或 Cache-Control:s-maxage但是存在Last-Modified时,那么浏览器默认会采用一个启发式的算法,即启发式缓存。通常会取响应头的Date_value - Last-Modified_value值的10%作为缓存时间,之后浏览器仍然会按强缓存来对待这个资源一段时间,如果你不想要缓存的话务必确保有no-cache或no-store在响应头中。
协商缓存
协商缓存阶段(也称弱缓存)
如果在本地缓存找到对应的资源,但是不知道该资源是否过期或者已经过期,则发一个http请求到服务器,然后服务器判断这个请求,如果请求的资源在服务器上没有改动过,则返回304,让浏览器使用本地找到的那个资源;
Last-Modified(值为资源最后更新时间,随服务器response返回)If-Modified-Since(通过比较两个时间来判断资源在两次请求期间是否有过修改,如果没有修改,则命中协商缓存)ETag(表示资源内容的唯一标识,随服务器response返回)If-None-Match(服务器通过比较请求头部的If-None-Match与当前资源的ETag是否一致来判断资源是否在两次请求之间有过修改,如果没有修改,则命中协商缓存)
协商缓存一般会在强缓存新鲜度过期后发起,向服务器确认是否需要更新本地的缓存文件,如果不需要更新,服务器会返回304否则会重新返回整个文件。服务器响应中会携带ETag和Last-Modified,Last-Modified 表示本地文件最后修改日期,浏览器会在request header加上If-Modified-Since(上次返回的Last-Modified的值),询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来。但是如果在本地打开缓存文件,就会造成Last-Modified被修改,所以在HTTP / 1.1 出现了ETag。Etag就像一个指纹,资源变化都会导致ETag变化,跟最后修改时间没有关系,ETag可以保证每一个资源是唯一的。If-None-Match的header会将上次返回的ETag发送给服务器,询问该资源的ETag是否有更新,有变动就会发送新的资源回来ETag(If-None-Match)的优先级高于Last-Modified(If-Modified-Since),优先使用ETag进行确认。协商缓存比强缓存稍慢,因为还是会发送请求到服务器进行确认。
有Last-Modified为什么还要有ETag
HTTP1.1中Etag的出现主要是为了解决几个 Last-Modified 比较难解决的问题:
- Last-Modified 标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的新鲜度
- 如果某些文件会被定期生成,当有时内容并没有任何变化,但 Last-Modified 却改变了,导致文件没法使用缓存
- 有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形
ETag
在HTTP1.1规范中,新增了一个HTTP头信息:ETag。浏览器第一次请求一个资源的时候,服务端给予返回,并且返回了ETag: “50b1c1d4f775c61:df3” 这样的字样给浏览器,当浏览器再次请求这个资源的时候,浏览器会将If-None-Match: W/“50b1c1d4f775c61:df3” 传输给服务端,服务端拿到该ETAG,对比资源是否发生变化,如果资源未发生改变,则返回304HTTP状态码,不返回具体的资源。通过Etag来利用浏览器的缓存,降低我们服务器的带宽压力。
第一次请求,服务器返回Etag。强缓存,expires和Cache-Control,判断是否过期,过期,请求服务器,服务端拿到该ETAG,对比资源是否发生变化,如果请求的资源在服务器上没有改动过,则返回304,让浏览器使用本地找到的那个资源;
缓存的流程
浏览器缓存分为强缓存和协商缓存。当客户端请求某个资源时,获取缓存的流程如下
- 先根据这个资源的一些
http header判断它是否命中强缓存,如果命中,则直接从本地获取缓存资源,不会发请求到服务器; - 当强缓存没有命中时,客户端会发送请求到服务器,服务器通过另一些
request header验证这个资源是否命中协商缓存,称为http再验证,如果命中,服务器将请求返回,但不返回资源,而是告诉客户端直接从缓存中获取,客户端收到返回后就会从缓存中获取资源; - 强缓存和协商缓存共同之处在于,如果命中缓存,服务器都不会返回资源; 区别是,强缓存不对发送请求到服务器,但协商缓存会。
- 当协商缓存也没命中时,服务器就会将资源发送回客户端。
- 当
ctrl+f5强制刷新网页时,直接从服务器加载,跳过强缓存和协商缓存; - 当
f5刷新网页时,跳过强缓存,但是会检查协商缓存;
Ajax
Ajax表示Asynchronous JavaScript and XML(异步JavaScript和XML),使我们可以请求特定URL获取数据并显示新的内容而不必重新刷新页面
原生Ajax机制
Ajax的原理简单来说是在用户和服务器之间加了—个中间层(AJAX引擎),通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM更新页面。使用户操作与服务器响应异步化。这其中最关键的一步就是从服务器获得请求数据。
ajax过程
Ajax的过程只涉及JavaScript、XMLHttpRequest和DOM。XMLHttpRequest是ajax的核心机制
1) 创建XMLHttpRequest
var xhr = new XMLHttpRequest();标准浏览器
var xhr = new ActiveXObject(‘Microsoft.XMLHTTP’);IE老版本
2) 准备发送xhr.open(1,2,3)
1 | 参数1,请求方式,get获取数据,post提交数据 |
get请求,url要加参数,这样php才能接受到参数
1
'/01.php?username'+username+'&password'+password
encodeURI()用来对中文参数进行编码,防止中文乱码post请求,url只需要地址,不需要参数,参数在send中传递
3) 执行发送动作
get请求 xhr.send(null);
post请求
1
2
3
4
5
6
7
8
9xhr.setRequestHeader("content-Type","application/x-www-form-urlencoded")//必须要请求头信息
var param='username'+username+'password'+password;
xhr.send(param);这里不需要encodeURI编码
在Form元素的语法中,EncType表明提交数据的格式
用 Enctype 属性指定将数据回发到服务器时浏览器使用的编码类型。
- application/x-www-form-urlencoded : 窗体数据被编码为名称/值对。这是标准的编码格式。(默认)
- multipart/form-data : 窗体数据被编码为一条消息,页上的每个控件对应消息中的一个部分。(type=file使用)
- text/plain : 窗体数据以纯文本形式进行编码,其中不含任何控件或格式字符。4)指定回调函数 浏览器调用
1 | /** 1. 创建连接 **/ |
XMLHttpRequest
XMLHttpRequest
XMLHttpRequest(XHR) 对象用于与服务器交互。通过 XMLHttpRequest 可以在不刷新页面的情况下请求特定 URL,获取数据。这允许网页在不影响用户操作的情况下,更新页面的局部内容。
XMLHttpRequest 可以用于获取任何类型的数据,而不仅仅是 XML。它甚至支持 HTTP 以外的协议(包括 file:// 和 FTP),尽管可能受到更多出于安全等原因的限制。
1. 属性
- XMLHttpRequest.responseType 表示服务器返回数据的类型,这个属性是可写的,在 open 之后,send 之前,告诉服务器返回指定类型的数据。如果 responseType 设为空字符串,就等同于默认值 text 表示服务器返回文本数据;
- XMLHttpRequest.onreadystatechange当
readyState属性发生变化时,调用的EventHandler。 - readyState HTTP 请求的状态,当一个 XMLHttpRequest 初次创建时,这个属性的值从 0 开始,直到接收到完整的 HTTP 响应,这个值增加到 4。
- status由服务器返回的 HTTP 状态代码,如 200 表示成功,而 404 表示 “Not Found” 错误。当 readyState 小于 3 的时候读取这一属性会导致一个异常。
- response 该属性只读表示服务器返回的数据体,可能是任意的数据类型,比如字符串,对象,二进制对象等,具体类型由responseType 属性决定。如果本次请求没有成功或者数据不完整,该属性等于 null
2. 方法
| abort() | 取消当前响应,关闭连接并且结束任何未决的网络活动 |
|---|---|
| getAllResponseHeaders() | 把 HTTP 响应头部作为未解析的字符串返回 |
| getResponseHeader() | 返回指定的 HTTP 响应头部的值 |
| open() | 初始化 HTTP 请求参数,例如 URL 和 HTTP 方法,但是并不发送请求 |
| send() | 发送 HTTP 请求,使用传递给 open() 方法的参数,以及传递给该方法的可选请求体 |
| setRequestHeader() | 向一个打开但未发送的请求设置或添加一个 HTTP 请求头 |
content-Type
接口发送参数、接收响应数据,都需要双方约定好使用什么格式的数据,只有双方按照约定好的格式去解析数据才能正确的收发数据。而 Content-Type 就是用来告诉你数据的格式
application/json:JSON数据格式,现在非常流行的格式application/x-www-form-urlencoded:很常见的一种数据格式,post请求中通常默认是这个multipart/form-data:上传文件时我们需要用到这个格式application/xml:XML数据格式text/html:HTML格式text/plain:纯文本格式image/png:png图片格式
get请求常用数据类型
要么是拼接在URl 后面, 要么就是 QueryString的方式传递,Content-Type 的值就不是那么重要了。
url param
Restful 的规范允许把参数写在 url 中,比如:
1 | http://c1998.cn/api/person/1111 |
这里的111就是路径中的参数 (url params)
query
通过 url 中 ?后面的用 & 分隔的字符串传递数据。比如:
1 | let data = { |
实际请求的路径是: http://c1998.cn/api/person?name=coder&age=111 通过URL传递数据的方式就这两种, 后面的3种是通过 body传递数据的方式
post请求常用数据类型
application/x-www-form-urlencoded
http 请求报文 
qs.stringify()作用是将对象或者数组序列化成URL的格式
1 | 对象序列化 |
qs.parse()则就是反过来啦,将我们通过qs.stringify()序列化的对象或者数组转回去
multipart/form-data
一般用于上传文件、二进制数据、非 ASCII 字符的内容
通过 new FormData将文件转成二进制数据
1 | const formData = new FormData(); |


请求体首先随机生成了一个boundary字段,这个boundary用来分割不同的字段。
一个请求的参数,会以boundary开始,然后是附加信息(参数名称,文件路径等),再空一行,最后是参数的内容
请求体最后再以boundary结束。
json

现在绝大部分的请求都会以json形式进行传输
总结
multipart/form-data:既可以上传文件等二进制数据,也可以上传表单键值对
x-www-form-urlencoded:只能上传键值对,并且键值对都是用&间隔分开的。(用Qs库转换)
application/json: 以序列化的 JSON 字符串形式传输
跨域
https://javascript.ruanyifeng.com/bom/cors.html
https://wangdoc.com/javascript/bom/cors
同源限制

同源策略指的是:协议,域名,端口相同,同源策略是一种安全协议
举例说明:比如一个黑客程序,他利用Iframe把真正的银行登录页面嵌到他的页面上,当你使用真实的用户名,密码登录时,他的页面就可以通过Javascript读取到你的表单中input中的内容,这样用户名,密码就轻松到手了。
跨域请求分类
浏览器将跨域请求分为两大类: 简单请求和非简单请求.
同时满足以下条件的请求都为简单请求:
- 请求方式为下列之一:
- GET
- POST
- HEAD
- HTTP 的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同时满足上面两个条件,就属于非简单请求。一句话,简单请求就是简单的 HTTP 方法与简单的 HTTP 头信息的结合。
简单请求
基本流程
对于简单请求,浏览器直接发出 CORS 请求。具体来说,就是在头信息之中,增加一个Origin字段。
下面是一个例子,浏览器发现这次跨域 AJAX 请求是简单请求,就自动在头信息之中,添加一个Origin字段。
1 | GET /cors HTTP/1.1 |
上面的头信息中,Origin字段用来说明,本次请求来自哪个域(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意这次请求。
如果Origin指定的源,不在许可范围内,服务器会返回一个正常的 HTTP 回应。浏览器发现回应的头信息没有包含Access-Control-Allow-Origin字段,就知道出错了,从而抛出一个错误,被XMLHttpRequest的onerror回调函数捕获。注意,这种错误无法通过状态码识别,因为 HTTP 回应的状态码有可能是200。
如果Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段。
1 | Access-Control-Allow-Origin: http://api.bob.com |
上面的头信息之中,有三个与 CORS 请求相关的字段,都以Access-Control-开头。
(1)Access-Control-Allow-Origin
该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求。
(2)Access-Control-Allow-Credentials
该字段可选。它的值是一个布尔值,表示是否允许发送 Cookie。默认情况下,Cookie 不包括在 CORS 请求之中。设为true,即表示服务器明确许可,浏览器可以把 Cookie 包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送 Cookie,不发送该字段即可。
(3)Access-Control-Expose-Headers
该字段可选。CORS 请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个服务器返回的基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。上面的例子指定,getResponseHeader('FooBar')可以返回FooBar字段的值。
withCredentials 属性
上面说到,CORS 请求默认不包含 Cookie 信息(以及 HTTP 认证信息等)。如果需要包含 Cookie 信息,一方面要服务器同意,指定Access-Control-Allow-Credentials字段。
1 | Access-Control-Allow-Credentials: true |
另一方面,开发者必须在 AJAX 请求中打开withCredentials属性。
1 | var xhr = new XMLHttpRequest(); |
否则,即使服务器同意发送 Cookie,浏览器也不会发送。或者,服务器要求设置 Cookie,浏览器也不会处理。
但是,如果省略withCredentials设置,有的浏览器还是会一起发送 Cookie。这时,可以显式关闭withCredentials。
1 | xhr.withCredentials = false; |
需要注意的是,如果要发送 Cookie,Access-Control-Allow-Origin就不能设为星号,必须指定明确的、与请求网页一致的域名。同时,Cookie 依然遵循同源政策,只有用服务器域名设置的 Cookie 才会上传,其他域名的 Cookie 并不会上传,且(跨域)原网页代码中的document.cookie也无法读取服务器域名下的 Cookie。
非简单请求
预检请求
非简单请求是那种对服务器提出特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的 CORS 请求,会在正式通信之前,增加一次 HTTP 查询请求,称为“预检”请求(preflight)。浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些 HTTP 动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。这是为了防止这些新增的请求,对传统的没有 CORS 支持的服务器形成压力,给服务器一个提前拒绝的机会,这样可以防止服务器大量收到DELETE和PUT请求,这些传统的表单不可能跨域发出的请求。
下面是一段浏览器的 JavaScript 脚本。
1 | var url = 'http://api.alice.com/cors'; |
上面代码中,HTTP 请求的方法是PUT,并且发送一个自定义头信息X-Custom-Header。
浏览器发现,这是一个非简单请求,就自动发出一个“预检”请求,要求服务器确认可以这样请求。下面是这个“预检”请求的 HTTP 头信息。
1 | OPTIONS /cors HTTP/1.1 |
“预检”请求用的请求方法是OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是Origin,表示请求来自哪个源。
除了Origin字段,“预检”请求的头信息包括两个特殊字段。
(1)Access-Control-Request-Method
该字段是必须的,用来列出浏览器的 CORS 请求会用到哪些 HTTP 方法,上例是PUT。
(2)Access-Control-Request-Headers
该字段是一个逗号分隔的字符串,指定浏览器 CORS 请求会额外发送的头信息字段,上例是X-Custom-Header。
预检请求的回应
服务器收到“预检”请求以后,检查了Origin、Access-Control-Request-Method和Access-Control-Request-Headers字段以后,确认允许跨源请求,就可以做出回应。
1 | HTTP/1.1 200 OK |
上面的 HTTP 回应中,关键的是Access-Control-Allow-Origin字段,表示http://api.bob.com可以请求数据。该字段也可以设为星号,表示同意任意跨源请求。
1 | Access-Control-Allow-Origin: * |
如果服务器否定了“预检”请求,会返回一个正常的 HTTP 回应,但是没有任何 CORS 相关的头信息字段,或者明确表示请求不符合条件。
1 | OPTIONS http://api.bob.com HTTP/1.1 |
上面的服务器回应,Access-Control-Allow-Origin字段明确不包括发出请求的http://api.bob.com。
这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被XMLHttpRequest对象的onerror回调函数捕获。控制台会打印出如下的报错信息。
1 | XMLHttpRequest cannot load http://api.alice.com. |
服务器回应的其他 CORS 相关字段如下。
1 | Access-Control-Allow-Methods: GET, POST, PUT |
(1)Access-Control-Allow-Methods
该字段必需,它的值是逗号分隔的一个字符串,表明服务器支持的所有跨域请求的方法。注意,返回的是所有支持的方法,而不单是浏览器请求的那个方法。这是为了避免多次“预检”请求。
(2)Access-Control-Allow-Headers
如果浏览器请求包括Access-Control-Request-Headers字段,则Access-Control-Allow-Headers字段是必需的。它也是一个逗号分隔的字符串,表明服务器支持的所有头信息字段,不限于浏览器在“预检”中请求的字段。
(3)Access-Control-Allow-Credentials
该字段与简单请求时的含义相同。
(4)Access-Control-Max-Age
该字段可选,用来指定本次预检请求的有效期,单位为秒。上面结果中,有效期是20天(1728000秒),即允许缓存该条回应1728000秒(即20天),在此期间,不用发出另一条预检请求。
浏览器的正常请求和回应
一旦服务器通过了“预检”请求,以后每次浏览器正常的 CORS 请求,就都跟简单请求一样,会有一个Origin头信息字段。服务器的回应,也都会有一个Access-Control-Allow-Origin头信息字段。
下面是“预检”请求之后,浏览器的正常 CORS 请求。
1 | PUT /cors HTTP/1.1 |
上面头信息的Origin字段是浏览器自动添加的。
下面是服务器正常的回应。
1 | Access-Control-Allow-Origin: http://api.bob.com |
上面头信息中,Access-Control-Allow-Origin字段是每次回应都必定包含的。
跨域解决方案
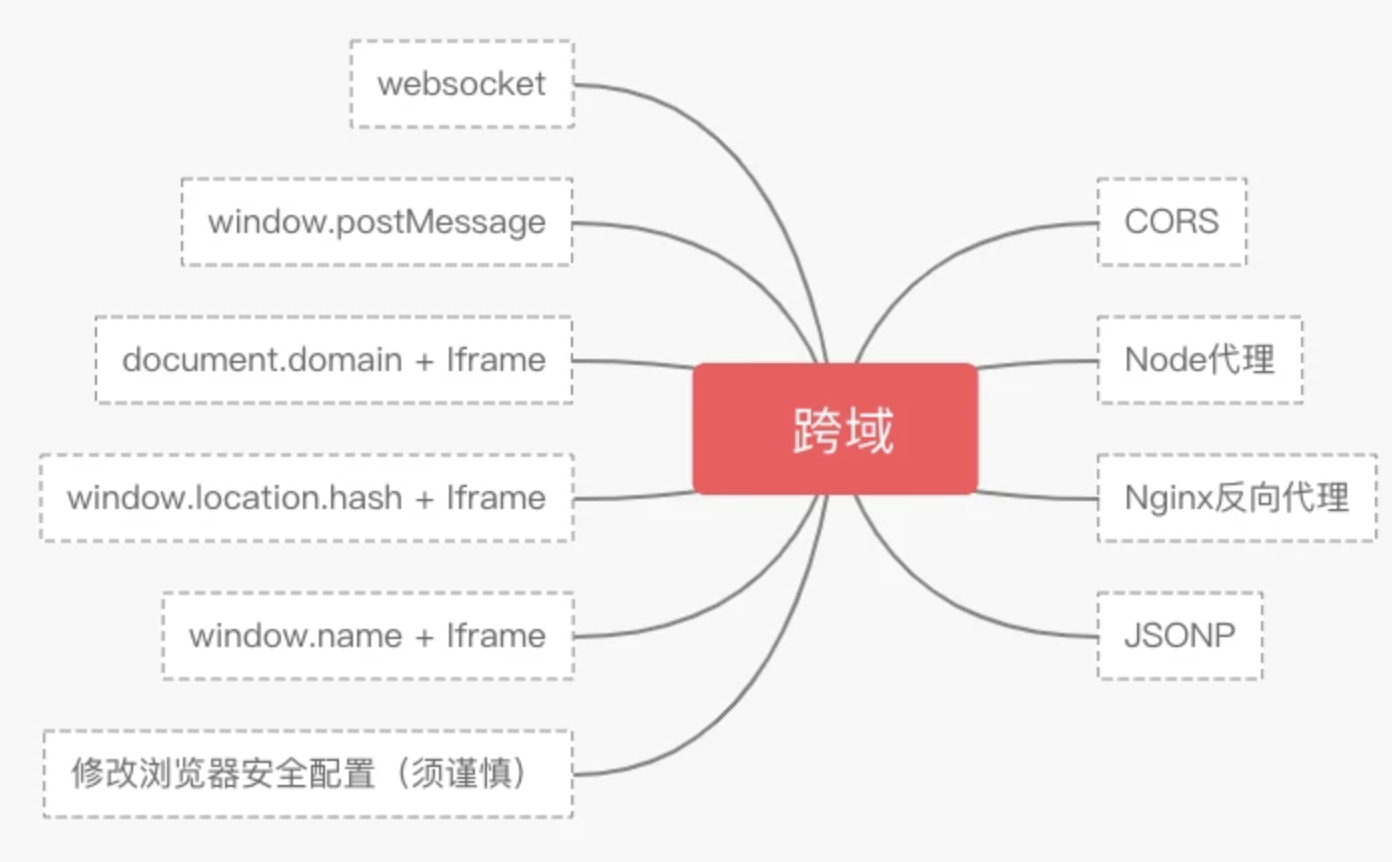
JSONP
只能发起GET请求
jsonp的原理:利用script标签可以跨域的原理实现。
html中通过动态创建一个script标签,通过它的src属性发送跨域请求,从服务器端响应的数据格式是一个函数的调用,函数名要一致。
原生JS实现
1
2
3
4
5
6
7
8
9
10var script = document.createElement('script');
var head = document.getElementByTagName('head')[0];
script.src='http::/1.html/1.php?callback=hello&username=123';
head.appendChild(script);
function hello(data){
console.log(data);
}
服务端返回如下(返回时即执行全局函数):
hello({"success": true, "user": "admin"})jquery Ajax实现
1
2
3
4
5
6
7$.ajax({
url: 'http://www.domain2.com:8080/login',
type: 'get',
dataType: 'jsonp', // 请求方式为jsonp
jsonpCallback: "handleCallback", // 自定义回调函数名
data: {}
});Vue axios实现
1
2
3
4
5
6
7this.$http = axios;
this.$http.jsonp('http://www.domain2.com:8080/login', {
params: {},
jsonp: 'handleCallback'
}).then((res) => {
console.log(res);
})
document.domain
document.domain将子域和主域的设为同一个主域
1)父窗口:(http://www.domain.com/a.html)
1 | <iframe id="iframe" src="http://child.domain.com/b.html"></iframe> |
1)子窗口:(http://child.domain.com/b.html)
1 | <script> |
location.hash + iframe跨域
实现原理: a欲与b跨域相互通信,通过中间页c来实现。 三个页面,不同域之间利用iframe的location.hash传值,相同域之间直接js访问来通信。
具体实现:A域:a.html -> B域:b.html -> A域:c.html,a与b不同域只能通过hash值单向通信,b与c也不同域也只能单向通信,但c与a同域,所以c可通过parent.parent访问a页面所有对象。
1)a.html:(http://www.domain1.com/a.html)
1 | <iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe> |
2)b.html:(http://www.domain2.com/b.html)
1 | <iframe id="iframe" src="http://www.domain1.com/c.html" style="display:none;"></iframe> |
3)c.html:(http://www.domain1.com/c.html)
1 | <script> |
window.name
window对象有个name属性,该属性有个特征:即在一个窗口(window)的生命周期内,窗口载入的所有 的页面都是共享一个window.name的,每个页面对window.name都有读写的权限,window.name是 持久存在一个窗口载入过的所有页面中的
postMessage
1 | <iframe id="ifr" src="b.com/index.html"></iframe> |
1 | <script type="text/javascript"> |
后端CORS
CORS就是一套AJAX跨域问题的解决方案
CORS的原理: 允许浏览器向跨域的服务器,发出
XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
跨域资源共享(CORS) 是一种基于 HTTP 头的机制,它使用额外的HTTP头来告诉浏览器让运行在一个 origin (domain) 上的 Web 应用被准许访问来自不同源服务器上的指定的资源。当一个资源从与该资源本身所在的服务器不同的域、协议或端口请求一个资源时,资源会发起一个跨域 HTTP 请求。
CORS 需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能。因此,实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨域通信。服务器端对于CORS的支持,主要就是通过设置Access-Control-Allow-Origin来进行的。如果浏览器检测到相应的设置,就可以允许Ajax进行跨域的访问。
node
1 | app.use(async (ctx, next) => { |
优势:
- 在服务端进行控制是否允许跨域,可自定义规则
- 支持各种请求方式
缺点:
- 会产生额外的请求
Nginx 代理服务器配置跨域
使用 Nginx 代理服务器之后,请求不会直接到达我们的 Node.js 服务器端,请求会先经过 Nginx 在设置一些跨域等信息之后再由 Nginx 转发到我们的 Node.js 服务端,所以这个时候我们的 Nginx 服务器去监听的 3011 端口,我们把 Node.js 服务的端口修改为 30011,简单配置如下所示:
1 | server { |
缺点:需要在nginx进行额外配置,语义不清晰
跨域操作cookie
需要满足3个条件:
服务的响应头中需要携带Access-Control-Allow-Credentials并且为true。
浏览器发起ajax需要指定withCredentials 为true
响应头中的Access-Control-Allow-Origin一定不能为*,必须是特定的域名
安全
https://mp.weixin.qq.com/s/WqJTHnHMsqvqAWjjJqyfsw
XSS和CSRF
XSS
Cross-Site Scripting(跨站脚本攻击)简称 XSS,是一种代码注入攻击。
攻击者往Web页面里插入恶意 html标签或者javascript代码。比 如:攻击者在论坛中放一个 看似安全的链接,骗取用户点击后,窃取cookie中的用户私密信息;或者攻击者在论坛中加一个恶意表 单, 当用户提交表单的时候,却把信息传送到攻击者的服务器中,而不是用户原本以为的信任站点。
存储型XSS攻击
会经常发生在内容驱动、用户保存数据的社区网站上,比如具备论坛发帖、商品评论、用户私信等功能的网站,危害比较大,可以说是永久型的
攻击者事先将恶意脚本代码提交到目标网站服务端数据库内(通过用户提交时夹杂脚本代码) 当用户打开该目标网站时,服务端将恶意代码取出拼接HTML返回给浏览器 用户浏览器接收到响应后立即执行,而恶意的脚本代码也被自动执行,从而冒充用户,窃取用户数据发送到攻击者网站,或者调用接口执行其他操作 
反射型XSS攻击
反射型XSS漏洞常见于具有通过URL传递参数的功能网站,如网站搜索、跳转等,需要引导用户主动打开URL,和存储型XSS攻击的区别是反射型存储在URL中,存储型存储在数据库中
攻击者通过混杂入恶意脚本构造恶意的URL 用户点击打开含有恶意脚本的URL,网站服务端将恶意代码从URL中取出,拼接在HTML返回给浏览器 用户接收到后,浏览器执行恶意代码,同上,窃取用户数据或者调取接口执行操作 
DOM型XSS
DOM型XSS攻击主要是前端浏览器直接取出恶意代码,而前两者是由后端先取出再拼接返回。
攻击者利用恶意脚本构造恶意URL 用户直接点开恶意的URL,浏览器响应后直接解析执行,前端JS取出URL并执行 浏览器执行恶意代码,同上,窃取用户数据或者调取接口执行操作 比如是诱导用户点击后往img标签src属性里插入恶意脚本等
以上三种XSS攻击主要都是要攻击者构造恶意的脚本执行攻击,存储型和反射型主要是后端安全问题,DOM型主要是前端安全问题
XSS防范方法
首先代码里对用户输入的地方和变量都需要仔细检查长度和对”<”,”>”,”;”,”’”等字符做过滤;其次任何内容 写到页面之前都必须加以encode,避免不小心把html tag 弄出来。这一个层面做好,至少可以堵住超过 一半的XSS 攻击。 首先,避免直接在cookie 中泄露用户隐私,例如email、密码等等。 其次,通过使cookie 和系统ip 绑定来降低cookie 泄露后的危险。这样攻击者得到的cookie 没有实际价 值,不可能拿来重放。 如果网站不需要再浏览器端对cookie 进行操作,可以在Set-Cookie 末尾加上HttpOnly 来防止javascript 代码直接获取cookie 。 尽量采用POST 而非GET 提交表单
CSRF
Cross Site Request Forgery,跨站请求伪造,字面理解意思就是在别的站点伪造了一个请求。专业术语来说就是在受害者访问一个网站时,其 Cookie 还没有过期的情况下,攻击者伪造一个链接地址发送受害者并欺骗让其点击,从而形成 CSRF 攻击。
eg:David 无意间打开了 Gmail 邮箱中的一份邮件,并点击了该邮件中的一个链接。过了几天,David 就发现他的域名被盗
- 首先 David 发起登录 Gmail 邮箱请求,然后 Gmail 服务器返回一些登录状态给 David 的浏览器,这些信息包括了 Cookie、Session 等,这样在 David 的浏览器中,Gmail 邮箱就处于登录状态了。
- 接着黑客通过各种手段引诱 David 去打开他的链接,比如 hacker.com,然后在 hacker.com 页面中,黑客编写好了一个邮件过滤器,并通过 Gmail 提供的 HTTP 设置接口设置好了新的邮件过滤功能,该过滤器会将 David 所有的邮件都转发到黑客的邮箱中。
- 最后的事情就很简单了,因为有了 David 的邮件内容,所以黑客就可以去域名服务商那边重置 David 域名账户的密码,重置好密码之后,就可以将其转出到黑客的账户了。
如何防止 CSRF 攻击,具体来讲主要有三种方式:充分利用好 Cookie 的 SameSite 属性、验证请求的来源站点和使用 CSRF Token。
网页验证码是干嘛的,是为了解决什么安全问题
- 区分用户是计算机还是人的公共全自动程序。可以防止恶意破解密码、刷票、论坛灌水
- 有效防止黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试
XSS与CSRF区别
XSS是获取信息,不需要提前知道其他用户页面的代码和数据包。CSRF是代替用户完成指定的动作,需要知道其他用户页面的代码和数据包。要完成一次CSRF攻击,受害者必须依次完成两个步骤- 登录受信任网站
A,并在本地生成Cookie - 在不登出
A的情况下,访问危险网站B
- 登录受信任网站
重放攻击
重放攻击(Replay Attacks)又称重播攻击、回放攻击,是指攻击者发送一个目的主机已接收过的包,来达到欺骗系统的目的,主要用于身份认证过程,破坏认证的正确性。 重放攻击可以由发起者,也可以由拦截并重发该数据的敌方进行。攻击者利用网络监听或者其他方式盗取认证凭据,之后再把它重新发给认证服务器。 重放攻击在任何网络通信过程中都可能发生,是计算机世界黑客常用的攻击方式之一
重放攻击的基本原理就是把以前窃听到的数据原封不动地重新发送给接收方。很多时候,网络上传输的数据是加密过的,此时窃听者无法得到数据的准确意义。但如果他知道这些数据的作用,就可以在不知道数据内容的情况下通过再次发送这些数据达到愚弄接收端的目的。例如,有的系统会将鉴别信息进行简单加密后进行传输,这时攻击者虽然无法窃听密码,但他们却可以首先截取加密后的口令然后将其重放,从而利用这种方式进行有效的攻击。再比如,假设网上存款系统中,一条消息表示用户支取了一笔存款,攻击者完全可以多次发送这条消息而偷窃存款。
防御方案 (1)加随机数。该方法优点是认证双方不需要时间同步,双方记住使用过的随机数,如发现报文中有以前使用过的随机数,就认为是重放攻击。缺点是需要额外保存使用过的随机数,若记录的时间段较长,则保存和查询的开销较大。 (2)加时间戳。该方法优点是不用额外保存其他信息。缺点是认证双方需要准确的时间同步,同步越好,受攻击的可能性就越小。但当系统很庞大,跨越的区域较广时,要做到精确的时间同步并不是很容易 (3)加流水号。就是双方在报文中添加一个逐步递增的整数,只要接收到一个不连续的流水号报文(太大或太小),就认定有重放威胁。该方法优点是不需要时间同步,保存的信息量比随机数方式小。但是一旦攻击者对报文解密成功,就可以获得流水号,从而每次将流水号递增欺骗认证端。
sql注入
原理:就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令
- 总的来说有以下几点
- 永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双
"-"进行转换等 - 永远不要使用动态拼装SQL,可以使用参数化的
SQL或者直接使用存储过程进行数据查询存取 - 永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接
- 不要把机密信息明文存放,请加密或者
hash掉密码和敏感的信息
- 永远不要信任用户的输入,要对用户的输入进行校验,可以通过正则表达式,或限制长度,对单引号和双
html
html标签
文本加粗标签 > 工作里尽量使用strong
文本倾斜标签 > > 工作里尽量使用em
删除线标签 ~~~~> > 工作里尽量使用del
下划线标签 > 工作里尽量使用ins
上标 下标
超链接a:属性target,’*self’在自身页面打开,’*blank’打开一个新页面
让所有的超链接都在新窗口打开
锚链接:
回到顶部关键字:
网页描述:
网页重定向:
设置icon图标:
img:title当鼠标滑动到元素上的时候显示,alt是<img>的特有属性,是图片内容的等价描述,用于图片无法加载时显示、读屏器阅读图片
表格
https://zhuanlan.zhihu.com/p/527511240?utm_id=0
| 1 | 2 | |
|---|---|---|
| 1 | 1 | 1 |
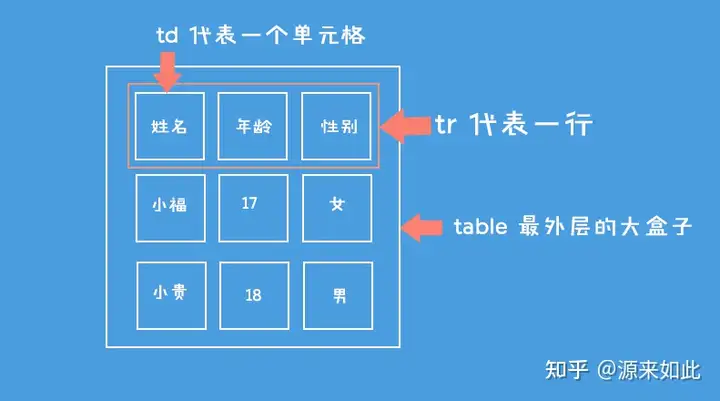
- table用于定义一个表格标签。
- tr标签 用于定义表格中的行,必须嵌套在 table标签中。
- td 用于定义表格中的单元格,必须嵌套在
<tr></tr>标签中。 - 字母 td 指表格数据(table data),即数据单元格的内容,现在我们明白,表格最合适的地方就是用来存储数据的。
表格属性
表格有部分属性我们不常用,这里重点记住 cellspacing 、 cellpadding。
| 属性名 | 含义 | 常用属性值 |
|---|---|---|
| border | 设置表格的边框(默认border=“0”无边框) | 像素值 |
| cellspacing | 设置单元格与单元格边框之间的空白间距 | 像素值(默认为2像素) |
| cellpadding | 设置单元格内容与单元格边框之间的空白间距 | 像素值(默认为1像素) |
| width | 设置表格的宽度 | 像素值 |
| height | 设置表格的高度 | 像素值 |
| align | 设置表格在网页中的水平对齐方式 | left,center,right |
边框合并
colspan=”2” 合并同一行上的单元格
rowspan=”2” 合并同一列上的单元格
1 | table { display: table } |
表单
对表单信息分组 表单信息分组名称 对下拉列表select进行分组。Label=”” 分组名称。1 | <fieldset> |
表单元素属性
- value 用于大部分表单元素的内容获取(option除外)
- type 可以获取input标签的类型(输入框或复选框等)
- disabled 禁用属性
- checked 复选框选中属性
- selected 下拉菜单选中属性
iframe
iframe有那些缺点?
iframe会阻塞主页面的Onload事件- 搜索引擎的检索程序无法解读这种页面,不利于
SEO iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载- 使用
iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript动态给iframe添加src属性值,这样可以绕开以上两个问题
实际应用中,iframe可以当作一个子模块,像vue单一应用那样,选择菜单栏的选项,就切换页面相应的子模块。而使用原生的话,选择菜单栏的选项,就请求相应的iframe模块。
如何知道是iframe模块?
右键点击,出现重新加载框架,点击重新加载框架,就局部加载该iframe模块
iframe 父页面与子页面之间 postMessage() 通信
textarea
textarea文本域在页面中是可以拖动的,即时你给了固定的宽度和高度,但这在我们页面布局中,使我们不需要的,因为可拖拽很多时候会影响我们页面的布局和整体的美观度。
1 | textarea { |
resize:
1.both(默认值)–在xy方向上均可以拖拽;
2.vertical–在垂直方向上
3.horizontal–在水平方向上
4.none–不可以拖拽
5.inherit(继承)–textarea的父集一般是div元素,所以设置为继承的话,也是不可以拖拽的
- -
html5标签
标签
HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加
- 新增选择器
document.querySelector、document.querySelectorAll - 拖拽释放(
Drag and drop) API - 媒体播放的
video和audio - 本地存储
localStorage和sessionStorage - 离线应用
manifest - 桌面通知
Notifications - 语意化标签
article、footer、header、nav、section - 增强表单控件
calendar、date、time、email、url、search - 地理位置
Geolocation - 多任务
webworker - 全双工通信协议
websocket - 历史管理
history - 跨域资源共享(CORS)
Access-Control-Allow-Origin - 页面可见性改变事件
visibilitychange - 跨窗口通信
PostMessage Form Data对象- 绘画
canvas
1 | <!-- 数据列表 --> |
总结
SEO
标签语义化:尽可能少的使用无语义的标签div和span;
- 合理的
title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要关键词即可 - 语义化的
HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页 - 重要内容
HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取 - 重要内容不要用
js输出:爬虫不会执行js获取内容 - 少用
iframe:搜索引擎不会抓取iframe中的内容 - 非装饰性图片必须加
alt - 提高网站速度:网站速度是搜索引擎排序的一个重要指标
Doctype作用
<!DOCTYPE>声明位于文档中的最前面,处于<html>标签之前。告知浏览器的解析器, 用什么文档类型 规范来解析这个文档- 严格模式的排版和
JS运作模式是 以该浏览器支持的最高标准运行 - 在混杂模式中,页面以宽松的向后兼容的方式显示。模拟老式浏览器的行为以防止站点无法工作。
- DOCTYPE 不存在或格式不正确会导致文档以混杂模式呈现
严格模式与混杂模式
严格模式的限制
- 变量必须声明后再使用
- 函数的参数不能有同名属性,否则报错
- 不能使用with语句
- 不能对只读属性赋值,否则报错
- 不能使用前缀0表示八进制数,否则报错
- 不能删除不可删除的属性,否则报错
- 不能删除变量
delete prop,会报错,只能删除属性delete global[prop] eval不会在它的外层作用域引入变量eval和arguments不能被重新赋值arguments不会自动反映函数参数的变化- 不能使用
arguments.callee - 不能使用
arguments.caller - 禁止
this指向全局对象 - 不能使用
fn.caller和fn.arguments获取函数调用的堆栈 - 增加了保留字(比如
protected、static和interface)
Charset编码
Ascll Ansi Unicode Gbk Gb2312 Big5 Utf-8 通用字符集
src 与 href 的区别
src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系。
src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在
位置;在请求 src 资源时会将其指向的资源下载并应用到文档内,例如 js 脚本,img 图片
和 frame 等元素。
当浏览器解析到该元素时,会暂停其他资源的下载和处理,直到将该资源加载、编译、执行
完毕,图片和框架等元素也如此,类似于将所指向资源嵌入当前标签内。这也是为什么将
js 脚本放在底部而不是头部。
href 是 Hypertext Reference 的缩写,指向网络资源所在位置,建立和当前元素(锚点)
或当前文档(链接)之间的链接,如果我们在文档中添加
那么浏览器会识别该文档为 css 文件,就会并行下载资源并且不会停止对当前文档的处理。
这也是为什么建议使用 link 方式来加载 css,而不是使用@import 方式。
XML和JSON的区别
- 数据体积方面
JSON相对于XML来讲,数据的体积小,传递的速度更快些。
- 数据交互方面
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互
- 数据描述方面
JSON对数据的描述性比XML较差
- 传输速度方面
JSON的速度要远远快于XML
css
class命名规范
https://www.cnblogs.com/yyzyou/p/7920023.html
整体结构
头:header
页面主体:main
内容:content/container
侧栏:sidebar
栏目:column
页面外围控制整体布局宽度:wrapper
方向:left right center top bottom
内部: in
尾:footer
版权:copyright
菜单和导航
导航:nav
主导航:mainbav
子导航:subnav
顶导航:topnav
边导航:sidebar
左导航:leftsidebar
右导航:rightsidebar
菜单:menu
子菜单:submenu
下拉菜单:dropmenv
标签页:tab
title
| 文章列表:list | 提示信息:msg | 小技巧:tips |
|---|---|---|
| 栏目标题:title | 字体:font | 注释:note |
| 文本:text | 摘要: summary | |
动词
| 加入:joinus | 指南:guild | 服务:service |
|---|---|---|
| 注册:regsiter | 投票:vote | 滚动:scroll |
| 下载:download | ||
形容词
| 当前的: current | ||
|---|---|---|
功能
| 登录条:loginbar | 广告:banner | 功能区:shop |
|---|---|---|
| 按钮:btn | 图标: icon | 线:line |
| 热点:hot | 新闻:news | 合作伙伴:partner |
| 友情链接:friendlink | 版权:copyright | 标签:label |
| 图片:pic | 首页:homepage | 模态:modal |
| 名片:card | 通知:notification | 平台:platform |
| 优惠券:coupon |
行内元素和块元素
https://blog.csdn.net/Jwhahaha/article/details/102483938
块级元素
可以设置宽高,独自占据一行高度(float浮动除外),一般可以作为其他容器使用,可容纳块级元素和行内元素。块级元素有以下特点:
- 每个块级元素都是独自占一行。
- 元素的高度、宽度、行高和边距都是可以设置的。
- 元素的宽度如果不设置的话,默认为父元素的宽度(父元素宽度100%),高度由内容撑开
1 | h1~h6:标题标签,用于标记网页中的大标题,依次从大到小 |
行内元素 inline
行内元素不可以设置宽(width)和高(height),但可以与其他行内元素位于同一行,行内元素内一般不可以包含块级元素。行内元素的宽和高就是内容撑开的宽高。。行内元素有以下特点:
- 每一个行内元素可以和别的行内元素共享一行,相邻的行内元素会排列在同一行里,直到一行排不下了,才会换行。
- 行内元素的高度、宽度、行高不可设置。
- 元素的宽度就是它包含的文字或图片的宽度,不可改变。
- 行内元素不能设置宽高,和竖直方向的margin、padding ,但左右可以
常见行内元素有以下:
1 | span:是超文本标记语言(HTML)的行内标签,被用来组合文档中的行内元素,span没有固定的格式表现,当对它应用样式时,它会产生视觉上的变化 |
行内块级元素 inline-block
行内块级元素,它既具有块级元素的特点,也有行内元素的特点,它可以自由设置元素宽度和高度,也可以在一行中放置多个行内块级元素。比如input、img就是行内块级元素,它可以设置高宽以及一行多个。具体特点如下:
- 和其他行内或行内块级元素元素放置在同一行上;
- 元素的高度、宽度、行高以及顶和底边距都可设置。
1 | img:用于标记网页中的图像 ,有属性src:图片资源路径 ,alt:提示信息 当图片加载失败 ,以指定文本形式代替图片显示 |
选择器
优先级

在属性后面使用 !important 会覆盖页面内任何位置定义的元素样式。
作为style属性写在元素内的样式 优先级1000
id选择器 优先级100
类选择器和伪类和属性 优先级10
标签选择器和伪元素 优先级1
通配符选择器 优先级0
浏览器自定义或继承 没有优先级
总结排序:!important > 行内样式>ID选择器 > 类选择器 > 标签 > 通配符 > 继承 > 浏览器默认属性
当权值相等时,后定义的样式表要优于先定义的样式表。
交集/后代选择器的优先级 所有优先级 加起来 运算 然后比较
并集的话 就是各算各的。
组合选择器
- 相邻兄弟选择器 A + B,选择紧接在A后的B元素(A和B中间不能有元素),且二者有相同的父元素
- 普通兄弟选择器 A ~ B,选择紧接在A后的所有B元素(A和B中间可以有元素),且二者有相同的父元素
- 子选择器 A > B
- 后代选择器 A B
- 交集 A.B{}
- 并集 A, B{}
属性选择器
1 | /* 存在title属性的<a> 元素 */ |
伪类选择器
用来表示定位元素的某种状态所显示的样式
1 | a:link{属性:值;} 链接默认状态 |
p:first-of-type选择属于其父元素的首个<p>元素的每个<p>元素。p:last-of-type选择属于其父元素的最后<p>元素的每个<p>元素。p:only-of-type选择属于其父元素唯一的<p>元素的每个<p>元素。p:only-child选择属于其父元素的唯一子元素的每个<p>元素。p:nth-child(2)选择属于其父元素的第二个子元素的每个<p>元素。p:nth-of-type(n)选择E的父元素下的第n个E元素:after在元素之前添加内容,也可以用来做清除浮动。:before在元素之后添加内容。:enabled已启用的表单元素。:disabled已禁用的表单元素。:checked单选框或复选框被选中。:empty选中没有任何子节点的E元素;
伪元素选择器
用于创建一些不在文档树中的元素,并为其添加样式。
1 | 伪元素特性 |
E::selection 可改变选中文本的样式
E::placeholder 可改变placeholder默认样式,这个存在明显的兼容问题,比如::-webkit-input-placeholderE:after、E:before
::before创建一个伪元素,该元素是所选元素的第一个子元素::after创建一个伪元素,该元素是所选元素的最后一个子元素块级元素才能有:before, :after,譬如 img 就不能设置
伪类元素的display是默认值inline
```
starof
attr() 通过attr()调用当前元素的属性,比如将图片alt提示文字或者链接的href地址显示出来。
a::after{content: attr(href) ;}
a::before{
content: url(“https://www.baidu.com/img/baidu_jgylogo3.gif");
}1
2
3
- 清除浮动.cf:before,
.cf:after {content: " "; display: table;}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
## 文字
### 基础
- **font-family**
- font-variant 设置字母字体
- **normal :** 正常的字体
- **small-caps :** 设置小型大写字母的字体显示文本,这意味着所有的小写字母均会被转换为大写,但是所有使用小型大写字体的字母与其余文本相比,其字体尺寸更小
- text-transform
- none
- **capitalize :** 将每个单词的第一个字母转换成大写,其余无转换发生
- **uppercase :** 转换成大写
- **lowercase :** 转换成小写
- text-decoration下划线
- none | underline | line-through
- **direction**文本方向 ltr 默认。文本方向从左到右。 rtl 文本方向从右到左。 inherit 规定应该从父元素继承 direction 属性的值。
- **text-size-adjust**:文本溢出算法,根据设备尺寸而自动调整文字大小
auto:启用浏览器的文本溢出算法
none:禁用浏览器的文本溢出算法。
percentage:启用浏览器的文本溢出算法,并使用用一个百分数来确定文本放大程度。
### 间距
- **text-indent :** 规定文本块中首行文本的缩进。
| *length* | 定义固定的缩进。默认值:0。 |
| -------- | ------------------------------------------- |
| *%* | 定义基于父元素宽度的百分比的缩进。 |
| inherit | 规定应该从父元素继承 text-indent 属性的值。 |
- **letter-spacing :**增加或减少字符间的空白(字符间距)
| normal | 默认。规定字符间没有额外的空间。 |
| -------- | ---------------------------------------------- |
| *length* | 定义字符间的固定空间(允许使用负值)。 |
| inherit | 规定应该从父元素继承 letter-spacing 属性的值。 |
-
### **vertical-align**
https://blog.csdn.net/qq_42667613/article/details/123429515
设置一个元素的垂直对齐方式。该属性**定义行内元素(`inline`、`inline-block`、`inline-table`、`table-cell`)的基线相对于该元素所在行的基线的对齐方式**。
> vertical-align不可继承,必须对**子元素**单独设置。
1. baseline:**默认值**,元素的基线与父元素基线对齐。
2. top:把元素的顶端与父元素顶线对齐;
3. **middle:把此元素放置在父元素的中部。**
4. bottom:把元素的顶端与父元素底线对齐
### line-height
**行高是指文本行基线间的垂直距离**
https://blog.csdn.net/a2013126370/article/details/82786681
*length :* 百分比数字 | 由浮点数字和单位标识符组成的长度值,允许为负值。其百分比取值是基于字体的高度尺寸。1em=字体的大小
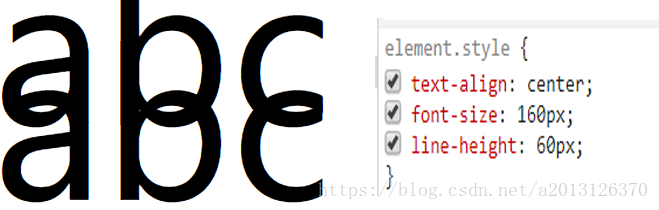
下图中两条红线之间的距离就是行高,上行的底线和下一行顶线之间的距离就是行距,而同一行顶线和底线之间的距离是font-size的大小,行距的一半是半行距。

**line-height=font-size+行间距**
当font-size等于line-height时,行距 = line-height - font-size = 0;而当font-size大于line-height时,则会出现行距为负值,则两行重叠,如下图:
- 如果一个标签没有定义 `height` 属性,那么其最终表现的高度是由 `line-height` 决定的
- 一个容器没有设置高度,那么撑开容器高度的是 `line-height` 而不是容器内的文字内容
- 把 `line-height` 值设置为 `height` 一样大小的值可以实现单行文字的垂直居中
### 换行
#### white-space文本换行
https://blog.csdn.net/qq_37210523/article/details/103145240
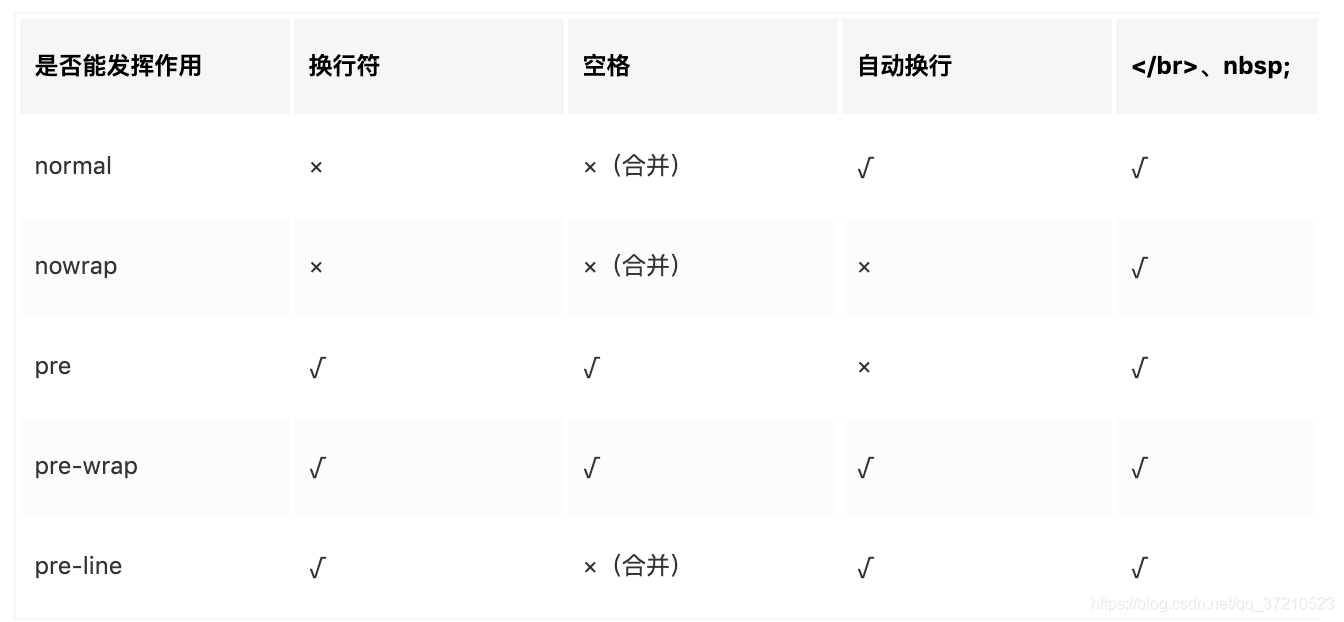
```css
white-space: normal; /*连续的空白符会被合并,换行符会被当作空白符来处理。填充line盒子时,必要的话会换行。 */
white-space: nowrap; /* 和 normal 一样,连续的空白符会被合并。但文本内的换行无效。*/
white-space: pre; /* 连续的空白符会被保留。在遇到换行符或者<br>元素时才会换行。*/
white-space: pre-wrap; /* 连续的空白符会被保留。在遇到换行符或者<br>元素,或者需要为了填充line盒子时才会换行。*/
white-space: pre-line; /* 连续的空白符会被合并。在遇到换行符或者<br>元素,或者需要为了填充line盒子时会换行。*/
white-space: break-spaces;
/**
与 pre-wrap的行为相同,除了:
任何保留的空白序列总是占用空间,包括在行尾。
每个保留的空格字符后都存在换行机会,包括空格字符之间。
这样保留的空间占用空间而不会挂起,从而影响盒子的固有尺寸(最小内容大小和最大内容大小)。
*/
white-space: inherit;
white-space: initial;
white-space: unset;
word-break单词换行
word-break 指定了怎样在单词内断行
1 | word-break:指定了怎样在单词内断行 |
总结
- white-space控制空白字符的显示,同时还能控制是否自动换行。它有五个值:normal | nowrap | pre | pre-wrap | pre-line
- word-break,控制单词如何被拆分换行。它有三个值:normal | break-all | keep-all
- word-wrap(overflow-wrap)控制长度超过一行的单词是否被拆分换行,是word-break的补充,它有两个值:normal | break-word
文本缩略
text-overflow : clip | ellipsis
clip : 不显示省略标记(…),而是简单的裁切 ellipsis : 当对象内文本溢出时显示省略标记(…)
1 | section:nth-of-type(4) p { |
图像
裁剪
clip : auto | rect ( number number number number **)**依据上-右-下-左的顺序剪切图像。必须将position的值设为absolute,此属性方可使用。
clip-path 裁切一个圆角 inset(
object-fit
https://www.runoob.com/cssref/pr-object-fit.html
object-fit 属性指定元素的内容应该如何去适应指定容器的高度与宽度。
object-fit 一般用于 img 和 video 标签,一般可以对这些元素进行保留原始比例的剪切、缩放或者直接进行拉伸等。
| 值 | 描述 |
|---|---|
| fill | 默认,不保证保持原有的比例,内容拉伸填充整个内容容器。 |
| contain | 保持原有尺寸比例。内容被缩放。 |
| cover | 保持原有尺寸比例。但部分内容可能被剪切。 |
| none | 保留原有元素内容的长度和宽度,也就是说内容不会被重置。 |
| scale-down | 保持原有尺寸比例。内容的尺寸与 none 或 contain 中的一个相同,取决于它们两个之间谁得到的对象尺寸会更小一些。 |
| initial | 设置为默认值,关于 initial |
| inherit | 从该元素的父元素继承属性。 关于 inherit |
布局
BFC
https://zhuanlan.zhihu.com/p/25321647
https://www.jianshu.com/p/4d1dbb041bb2
BFC(Block Formatting Context),块级格式化上下文,是一个独立的渲染区域,让处于 BFC 内部的元素与外部的元素相互隔离,使容器里面的元素不会在布局上影响到外面的元素。
触发条件
- body 根元素
- 浮动元素:float 除 none 以外的值
- 绝对定位元素:position (absolute、fixed)
- display 为 inline-block、table-cells、flex
- overflow 除了 visible 以外的值 (hidden、auto、scroll)
BFC场景和应用
1. 同一个 BFC 下外边距会发生折叠
1 | <head> |

从效果上看,因为两个 div 元素都处于同一个 BFC 容器下 (这里指 body 元素) 所以第一个 div 的下边距和第二个 div 的上边距发生了重叠,所以两个盒子之间距离只有 100px,而不是 200px。
2. BFC 可以包含浮动的元素(清除浮动)
我们都知道,浮动的元素会脱离普通文档流,来看下下面一个例子
1 | <div style="border: 1px solid #000;"> |

由于容器内元素浮动,脱离了文档流,所以容器只剩下 2px 的边距高度。如果使触发容器的 BFC,那么容器将会包裹着浮动元素。
float为left/right是子元素本身触发了BFC,使普通布局流变成了浮动流布局;父级元素因为浮动从而高度塌陷,所以需要overflow来触发父级元素的BFC来重新布局回到普通布局。
1 | <div style="border: 1px solid #000;overflow: hidden"> |

3. BFC 可以阻止元素被浮动元素覆盖
先来看一个文字环绕效果:
1 | <div style="height: 100px;width: 100px;float: left;background: lightblue">我是一个左浮动的元素</div> |

这时候其实第二个元素有部分被浮动元素所覆盖,(但是文本信息不会被浮动元素所覆盖) 如果想避免元素被覆盖,可触第二个元素的 BFC 特性,在第二个元素中加入 overflow: hidden,就会变成:

这个方法可以用来实现两列自适应布局,效果不错,这时候左边的宽度固定,右边的内容自适应宽度(去掉上面右边内容的宽度)。
开发中的应用
- 阻止
margin重叠 - 可以包含浮动元素 —— 清除内部浮动(清除浮动的原理是两个
div都位于同一个BFC区域之中) - 自适应两栏布局
- 可以阻止元素被浮动元素覆盖
float
https://blog.csdn.net/qq_36595013/article/details/81810219
概念
设置元素浮动后,对应的元素会脱离文档流,该元素的
display值自动变成block
假如某个div元素A是浮动的,如果A元素上一个元素也是浮动的,那么A元素会跟随在上一个元素的后边(如果一行放不下这两个元素,那么A元素会被挤到下一行);如果A元素上一个元素是标准流中的元素,那么A的顶部和上一个元素的底部对齐。
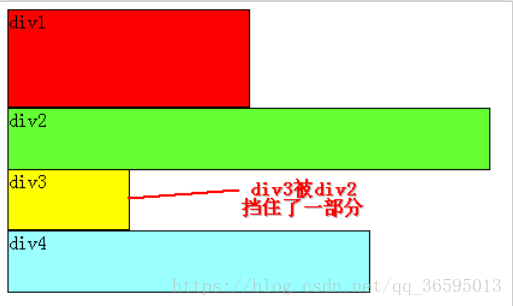
假设上图中的div2浮动,那么它将脱离标准流,但div1、div3、div4仍然在标准流当中,所以div3会自动向上移动,占据div2的位置,重新组成一个流。
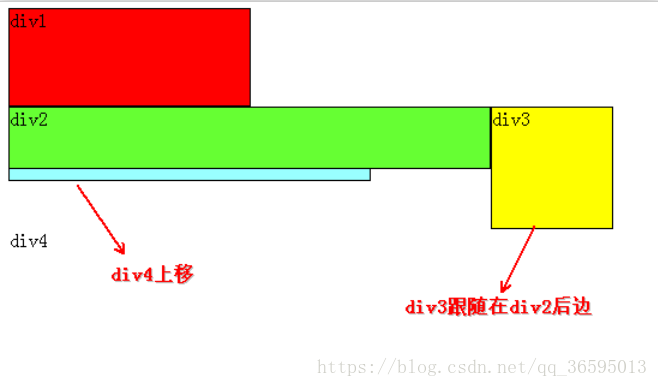
把div2和div3都加上左浮动,由于div2、div3浮动,它们不再属于标准流,因此div4会自动上移,与div1组成一个“新”标准流,而浮动是漂浮在标准流之上,因此div2又挡住了div4。
清除浮动
清除浮动:清除浮动不是不用浮动,清除浮动产生的不利影响。
1 | clear :none| left |right | both |
场景:CSS浮动塌陷,父级元素不设置高度时,高度由随内容增加自适应高度。当父级元素内部的子元素全部都设置浮动float之后,子元素会脱离标准流,不占位,父级元素检测不到子元素的高度,父级元素高度为0。由于父级元素没有高度,下面的元素会顶上去,造成页面的塌陷。
解决:
父元素使用overflow:hidden来清除浮动,最好加上zoom:1;
父级div定义height
在父元素后面使用伪类:after和zoom
1
2
3
4
5
6.box:after{
- display:block;
- content:"";
- height:0;
- clear:both;
- }结尾处加空div标签clear:both
对父元素设置display:table;使父元素形成BFC(块格式化上下文)
应用
- float 可以用来让文字环绕图片而已。
- 如果宽度太小,放不下两个元素,后面的元素会自动滚动到前面元素的下方,不会在水平方向overflow(溢出),避免了水平滚动条的出现。
position
position:absolute
- 会让元素以display:inline-block的方式显示,可以设置长宽,默认宽度并不占满父元素。
- Z-index 仅能在定位元素上奏效(例如 position:absolute;)!
- 脱离文档流
position:relative
相对定位,相对于原来该元素在普通流中的位置重新定位,依旧在普通流中占据位置,没有脱离普通流,只是视觉上发生变化
1
2
3
4background-color: green;
position: relative;
top: 50px;
left: 100px;
- Position:fixed 通常相对于浏览器窗口或 frame 进行定位。
- 固定定位之后,不占据原来的位置(脱标)
- 元素使用固定定位之后,会转化为行内块
- static:默认值。没有定位,元素出现在正常的流中
flex
display: flex; 会浮动
flex-direction: column;决定主轴的方向(即子元素的排列方向)
调整主轴方向(默认为水平方向)包括row、column、row-reverse、column-reverse
justify-content(水平方向)定义了子元素在主轴上的对齐方式
主轴方向对齐,可以调整元素在主轴方向上的对齐方式,包括flex-start、flex-end、center、space-around(多与空间放两边)、space-between(多与空间放中间)几种方式
align-items(垂直方向)定义子元素在侧轴上如何对齐
调整侧轴方向对齐方式,包括flex-start、flex-end、center、baseline、stretch
flex-wrap 控制是否换行,包括wrap、nowrap (不换行)
align-content 定义了多根轴线的对齐方式, 如果子元素只有一根轴线,该属性不起作用 可对应用flex-wrap: wrap后产生的换行进行控制,包括flex-start、flex-end、center、space-between、space-around、stretch
align-self 侧轴上单个项目对齐方式 单独对某一个子元素设置 flex-start、flex-end、center、baseline、stretch
flex 控制子元素伸缩比例
https://blog.csdn.net/qq_41635167/article/details/104190865
https://www.zhangxinxu.com/wordpress/2019/12/css-flex-deep/
1 | flex:1 |
在Flex布局中,一个Flex子项的宽度是由元素自身尺寸,flex-basis设置的基础尺寸,以及外部填充(flex-grow)或收缩(flex-shrink)规则3者共同决定的。
举例:分家产
flex-basis:用于设置子盒子宽度。在Flex布局中,flex-basis优先级是比width高的。
flex-basis的默认值是auto,表示自动,也就是完全根据子列表项自身尺寸渲染。自身尺寸渲染优先级如下:min-width > || max-width > width > Content Size
flex-basis就是分配固定的家产数量。flex-grow(用在子盒子上)属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。 如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
flex-grow就是家产剩余家产仍有富余的时候该如何分配。flex-shrink(flex元素仅在默认宽度之和大于容器的时候才会发生收缩,其收缩的大小是依据 flex-shrink 的值)属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
flex-shrink就是家产剩余家产不足的时候该如何分配。
flex参数
1个值
如果flex的属性值只有一个值,则:
- 如果是数值,例如
flex: 1,则这个1表示flex-grow,此时。更正为:此时flex-shrink和flex-basis都使用默认值,分别是1和autoflex-shrink和flex-basis的值分别是1和0%,注意,这里的flex-basis的值是0%,而不是默认值auto。 - 如果是长度值,例如
flex: 100px,则这个100px显然指flex-basis,因为3个缩写CSS属性中只有flex-basis的属性值是长度值。此时更正为:此时flex-grow和flex-shrink都使用默认值,分别是0和1。flex-grow和flex-shrink都是1,注意,这里的flex-grow的值是1,而不是默认值0。
- 如果是数值,例如
2个值
如果flex的属性值有两个值,则第1个值一定指
flex-grow,第2个值根据值的类型不同表示不同的CSS属性,具体规则如下:- 如果第2个值是数值,例如
flex: 1 2,则这个2表示flex-shrink,此时更正为:此时flex-basis使用默认值auto。flex-basis计算值是0%,并非默认值auto。 - 如果第2个值是长度值,例如
flex: 1 100px,则这个100px指flex-basis,此时flex-shrink使用默认值0。
- 如果第2个值是数值,例如
3个值
如果
flex的属性值有3个值,则这长度值表示flex-basis,其余2个数值分别表示flex-grow和flex-shrink。下面两行CSS语句的语法都是合法的,且含义也是一样的:1
2
3/* 下面两行CSS语句含义是一样的 */
flex: 1 2 50%;
flex: 50% 1 2;
order 定义子元素的排列顺序, 数值越小 排列越靠前 默认为0
案例
元素的水平居中
元素为行内元素,设置父元素
text-align:center如果子元素宽度固定,可以设置左右
margin为auto;绝对定位和移动:
absolute + transform1
2
3
4
5
6
7
8
9
10
11
12
13.parent_box{
width: 400px;
height: 200px;
position: relative;
}
.child_box{
width: 200px;
height: 100px;
position: absolute;
top: 0;
left: 50%;
transform: translate( -50%,0);
}使用
flex-box布局,指定justify-content属性为center```
display:block;
margin:auto;1
2
3
4
5
6
7
8
9
10
11
#### 元素的垂直居中
- 将显示方式设置为表格,`display:table-cell`,同时设置`vertial-align:middle`
- 使用`flex`布局,设置为`align-item:center`
- 绝对定位中设置`bottom:0,top:0`,并设置`margin:auto`
- 绝对定位和移动: `absolute + transform`.parent_box{
width: 400px; height: 200px; position: relative; } .child_box{ width: 200px; height: 100px; position: absolute; left: 0; top: 50%; transform: translate( 0,-50%); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
- 绝对定位中固定高度时设置`top:50%,margin-top`值为高度一半的负值
- 文本垂直居中设置`line-height`为`height`值
#### 垂直水平居中
```css
/** 1 **/
.wraper {
position: relative;
.box {
position: absolute;
top: 50%;
left: 50%;
width: 100px;
height: 100px;
margin: -50px 0 0 -50px;
}
}
/** 2 **/
.wraper {
position: relative;
.box {
margin: 0 !important;
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
}
/** 3 **/
.wraper {
.box {
display: flex;
justify-content:center;
align-items: center;
height: 100px;
}
}
/** 4 **/
.wraper {
display: table;
.box {
display: table-cell;
vertical-align: middle;
}
}
如何垂直居中一个<img>
1 | #container /**<img>的容器设置如下**/ |
响应式
概念
设备尺寸
设备尺寸指的是设备对角线的长度,单位是英寸

像素px
**物理像素/设备像素(device pixel, dp)**: 由一个个物理像素点组成的,通过控制每个像素点的颜色,使屏幕显示出不同的图像,屏幕从工厂出来那天起,它上面的物理像素点就固定不变了,单位pt。 pt 在 css 单位中属于真正的绝对单位,1pt = 1/72(inch), inch及英寸,而1英寸等于2.54厘米。所以设备像素的特点就是大小固定,不可变。比如 iPhone 5 的分辨率为 640 x 1136px.
**CSS像素(css pixel, px)**: CSS像素 =设备独立像素 = 逻辑像素
由于不同的物理设备的物理像素的大小是不一样的,所以
css认为浏览器应该对css中的像素进行调节,使得浏览器中1css像素的大小在不同物理设备上看上去大小总是差不多 ,目的是为了保证阅读体验一致。为了达到这一点浏览器可以直接按照设备的物理像素大小进行换算。

左边表示标清屏幕,右边表示视网膜高清屏幕
宽和高都是2个CSS像素,那么在标清屏中需要用2 * 2个物理像素来显示,即1个CSS像素用1 * 1个物理像素来描述
在高清屏需要4 * 4个物理像素来显示,即1个CSS像素用2 * 2个物理像素来描述
像素比(DPR)
设备像素比:**window.devicePixelRatio = 物理像素 / 独立像素**
通过devicePixelRatio,我们可以知道该设备上一个css像素代表多少个物理像素。在普通屏,1个css像素对应1个物理像素;2倍屏中,一个css像素对应4个物理像素;三倍屏中则是9个。如iPhone6的dpr为2,物理像素750(x轴),则它的逻辑像素为375。
影响像素比(DPR)
- 配置设备分辨率
- 用户缩放。例如,当用户把页面放大一倍,那么css中1px所代表的物理像素也会增加一倍;反之把页面缩小一倍,css中1px所代表的物理像素也会减少一倍。
分辨率
是指桌面设定的分辨率(分辨率是可以改变的),而不是显示器的分辨率 。分辨率指的是宽度上和高度上最多能显示的物理像素点个数。指的是屏幕的像素尺寸。750X1334指的是横向有750个像素,纵向有1334个像素。
视口
视口针对移动设备,对PC没用
(1) 布局视口(layout viewport) 为了能在移动设备上正常显示那些为pc端浏览器设计的网站,移动设备上的浏览器都会把自己默认的 viewport 设为 980px 或其他值,一般都比移动端浏览器可视区域大很多,所以就会出现浏览器出现横向滚动条的情况
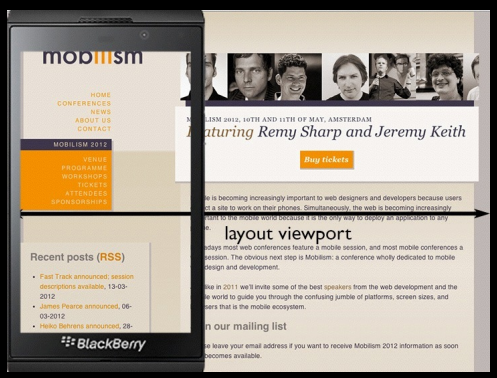
(2) 视觉视口(visual viewport) 视觉视口表示浏览器内看到的网站的显示区域,用户可以通过缩放来查看网页的显示内容,从而改变视觉视口。视觉视口的定义,就像拿着一个放大镜分别从不同距离观察同一个物体,视觉视口仅仅类似于放大镜中显示的内容,因此视觉视口不会影响布局视口的宽度和高度。

(3) 理想视口(ideal viewport)
理想视口或者应该全称为“理想的布局视口”,在移动设备中就是指设备的分辨率。换句话说,理想视口或者说分辨率就是给定设备物理像素的情况下,最佳的“布局视口”。 理想视口的值其实就是屏幕分辨率的值
应用
移动设备默认的viewport是layout viewport,但在进行移动设备网站的开发时,我们需要的是ideal viewport。那么怎么才能得到ideal viewport呢?这就该轮到meta标签出场了。
1 | <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0"> |
该meta标签的作用是让当前viewport的宽度等于设备的宽度,同时不允许用户手动缩放。让viewport的宽度等于设备的宽度,如果你不这样的设定的话,那就会使用那个比屏幕宽的默认viewport,也就是说会出现横向滚动条。
| width | 设置layout viewport 的宽度,为一个正整数,或字符串”width-device” |
|---|---|
| initial-scale | 设置页面的初始缩放值,为一个数字,可以带小数 |
| minimum-scale | 允许用户的最小缩放值,为一个数字,可以带小数 |
| maximum-scale | 允许用户的最大缩放值,为一个数字,可以带小数 |
| height | 设置layout viewport 的高度,这个属性对我们并不重要,很少使用 |
| user-scalable | 是否允许用户进行缩放,值为”no”或”yes”, no 代表不允许,yes代表允许 |
单位
https://blog.csdn.net/liwusen/article/details/80834546
https://www.cnblogs.com/zaoa/p/8630393.html
rem
相对于根元素html的font-size值的大小,此单位若要用于屏幕自适应,可与vw配合使用设置根元素的字体大小。375px的网页的设计稿。此时,1vw=3.75px;4vw=15px;8vw=30px;
百分比%
- 子元素width或height的百分比是父元素width或height的百分比
- top、bottom的百分比是相对于(默认定位)父元素的height
- left、right的百分比是相对于(默认定位)父元素的width
- padding、margin不论是垂直方向或者是水平方向,都相对于直接父元素的width
- border-radius、translate、background-size的百分比,则是相对于自身的width
两个缺点:
(1)计算困难,如果我们要定义一个元素的宽度和高度,按照设计稿,必须换算成百分比单位。 (2)各个属性中如果使用百分比,相对父元素的属性并不是唯一的。比如width和height相对于父元素的width和height,而margin、padding不管垂直还是水平方向都相对比父元素的宽度、border-radius则是相对于元素自身等等,造成我们使用百分比单位容易使布局问题变得复杂。
自适应
https://www.cnblogs.com/chenyoumei/p/10510321.html
查看设计图,确定页面布局,组件的复用等
尽可能的添加多的div来包含元素,并设置对应的classname
外层盒子使用flex进行布局,不设置绝对宽高px(使用rem或者%布局),高度由里面的内容撑开(撑不开就用margin、padding)
box-sizing:border-box以及margin:autoTips
- float的好处是,如果宽度太小,放不下两个元素,后面的元素会自动滚动到前面元素的下方,不会在水平方向overflow(溢出),避免了水平滚动条的出现。
- 图片的自适应,
img { width: auto; max-width: 100%; }
yd ui移动端
https://www.jianshu.com/p/b00cd3506782
自适应不是指你缩放页面大小(ctrl+鼠标滚动条),是指你浏览器大小变化自适应。一般不加自适应,缩放页面,会发现
$(document).width()会根据缩放变大变小,但是元素宽高不会变,相应元素就会感觉变大变小。加入自适应(自适应会根据页面大小来改变px,元素宽高会变),缩放页面,相应元素感觉不会改变。
缩放页面大小有三种情况:
1 | 1. 改变浏览器宽高 |
像素比就是第二种和第三种情况
1 | (function (doc, win) { |
flexible.js
https://github.com/amfe/lib-flexible/blob/2.0/index.js
1 | // 首先是一个立即执行函数,执行时传入的参数是window和document |
移动端
清除默认样式 Normalize.css
浏览器前缀,webpack:autoprefixer
内核 主要代表的浏览器 前缀 Trident IE浏览器 -ms Gecko Firefox -moz Presto Opera -o Webkit Chrome和Safari -webkit h5中如何处理移动端滑动卡顿的问题
1
2
3
4
5
6body {
// height: 100%;
-webkit-overflow-scrolling: touch;
overflow-scrolling: touch;
overflow-y: scroll;
}遮罩层隐藏之后,底部div无法触发点击事件:给遮罩层pointer-events
1
2
3
4
5pointer-events: none;
阻止用户的点击动作产生任何效果
阻止缺省鼠标指针的显示
阻止CSS里的hover和active状态的变化触发事件
阻止JavaScript点击动作触发的事件移动端开发1px像素线条变粗移动端window对象里有个 devicePixelRatios 属性,叫做 设备像数比 ,也就是设备的物理像素与逻辑像素的比值。 我们以iphone6为例子:它的物理像素是750,逻辑像素是375,所以他的 dpr 为 2,那么在css里写1px映射到物理像素就是2pt了
伪类+transform实现
媒体查询
1
2
3
4
5
6
7.border { border: 1px solid #999 }
@media screen and (-webkit-min-device-pixel-ratio: 2) {
.border { border: 0.5px solid #999 }
}
@media screen and (-webkit-min-device-pixel-ratio: 3) {
.border { border: 0.333333px solid #999 }
}利用viewport + js + 使用rem实现
1
2<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no">
复制代码- name=”viewport” content=”width=device-width: 本页面的 「viewport」 的宽度为设备宽度。
- initial-scale=1.0: 初始缩放值为 1,
- maximum-scale=1.0: 最大的缩放值为 1。
- user-scalable=no: 禁止用户进行页面缩放。
那么通过设置viewport的initial-scale,就可以轻松实现:
- 当dpr = 1 时,initial-scale = 1
- 当dpr = 2 时,initial-scale = 0.5
- 当dpr = 3 时,initial-scale = 0.33333333333
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23<html>
<head>
<title></title>
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no">
<style></style>
<script>
let viewport = document.querySelector("meta[name=viewport]");
//下面是根据设备像素设置viewport
if (window.devicePixelRatio == 1) {
viewport.setAttribute('content', 'width=device-width,initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no');
}
if (window.devicePixelRatio == 2) {
viewport.setAttribute('content', 'width=device-width,initial-scale=0.5, maximum-scale=0.5, minimum-scale=0.5, user-scalable=no');
}
if (window.devicePixelRatio == 3) {
viewport.setAttribute('content', 'width=device-width,initial-scale=0.3333333333333333, maximum-scale=0.3333333333333333, minimum-scale=0.3333333333333333, user-scalable=no');
}
let docEl = document.documentElement;
let fontsize = 32* (docEl.clientWidth / 750) + 'px';
docEl.style.fontSize = fontsize;
</script>
</head>
</html>
问题
图片模糊问题
https://juejin.cn/post/6885721051360133133#heading-11
我们平时使用的图片大多数都属于位图(png、jpg..),位图由一个个像素点构成的,每个像素都具有特定的位置和颜色值:
理论上,位图的每个像素对应在屏幕上使用一个物理像素来渲染,才能达到最佳的显示效果。
而在dpr > 1的屏幕上,位图的一个像素可能由多个物理像素来渲染,然而这些物理像素点并不能被准确的分配上对应位图像素的颜色,只能取近似值,所以相同的图片在dpr > 1的屏幕上就会模糊:
1px
出现的原因:
按照iPhone6的尺寸,一张750px宽的设计图,这个750px其实就是iPhone6的设备像素,在测量设计图时量到的1px其实是1设备像素,而当我们设置布局视口等于理想视口等于375px,并且由于iPhone6的DPR为2,写css时的1px对应的是2设备像素,所以看起来会粗一点。
解决办法
1.border-image
基于media查询判断不同的设备像素比给定不同的border-image:
1 | css复制代码.border_1px{ |
2. background-image
和border-image类似,准备一张符合条件的边框背景图,模拟在背景上。
1 | css复制代码.border_1px{ |
上面两种都需要单独准备图片,而且圆角不是很好处理,但是可以应对大部分场景。
3.伪类 + transform
基于media查询判断不同的设备像素比对线条进行缩放:
1 | css复制代码.border_1px:before{ |
这种方式可以满足各种场景,如果需要满足圆角,只需要给伪类也加上border-radius即可。
css属性
Scrollbar滚动条设置,cursor鼠标指针,zoom图像放大倍数
连写属性
font:font-style font-weight font-size/line-height font-family;
文本属性连写文字大小和字体为必写项。
border:color style(solid实线dotted 点线dashed 虚线) width
没有顺序要求,线型为必写项。
Padding: 20px; 上右下左内边距都是20px
Padding: 20px 30px; 上下20px 左右30px
Padding: 20px 30px 40px; 上内边距为20px 左右内边距为30px 下内边距为40
Padding: 20px 30px 40px 50px; 上20px 右30px 下40px 左 50px
calc属性
Calc用户动态计算长度值,任何长度值都可以使用calc()函数计算,需要注意的是,运算符前后都需要保留一个空格,例如:width: calc(100% - 10px);
总结与案例
https://juejin.cn/post/6885721051360133133#heading-0
隐藏和透明度
1 | display:none 隐藏对应的元素,在文档布局中不再给它分配空间,它各边的元素会合拢,就当他从来不存在。 |
透明度 background-color: rgba(0, 0, 0, 0.3); opacity: 0.3; transparent是颜色的一种,这种颜色叫透明色。
rgba()和 opacity 的透明效果有什么不同
rgba()和 opacity 都能实现透明效果,但最大的不同是 opacity 作用于元素,以及元素内的
所有内容的透明度,而 rgba()只作用于元素的颜色或其背景色。(设置 rgba 透明的元素的子元素不会继承透明 效果!)
设置placeholder样式
1 | placeholder(如果是在手机客户端webview 只使用-webkit内核方式即可。) |
link与@import的区别
- @import是CSS提供的语法规则,只有导入样式表的作用;link是HTML提供的标签,不仅可以加载CSS文件,还可以定义RSS,rel连接属性等;
- 加载页面时,link引入的CSS被同时加载,@import引入的CSS将在页面加载完毕后加载;
- link标签作为HTML元素,不存在兼容性问题,而@import是CSS2.1才有的语法,故老版本浏览器(IE5之前)不能识别;
- 可以通过JS操作DOM,来插入link标签改变样式;由于DOM方法是基于文档的,无法使用@import方式插入样式;
link引入的样式权重大于@import引入的样式。
建议使用link的方式引入CSS
display:table和本身的table有什么区别
Display:table和本身table是相对应的,区别在于,display:table的css声明能够让一个html元素和它的子节点像table元素一样,使用基于表格的css布局,使我们能够轻松定义一个单元格的边界,背景等样式,而不会产生因为使用了table那样的制表标签导致的语义化问题。
之所以现在逐渐淘汰了table系表格元素,是因为用div+css编写出来的文件比用table边写出来的文件小,而且table必须在页面完全加载后才显示,div则是逐行显示,table的嵌套性太多,没有div简洁
如何实现小于12px的字体效果
transform:scale()这个属性只可以缩放可以定义宽高的元素,而行内元素是没有宽高的,我们可以加上一个display:inline-block;
1 | transform: scale(0.7); |
自定义浏览器滚动条样式
https://daotin.netlify.app/sxemmx.html
如何设置input输入框的宽度随文字的输入长度而改变?
https://daotin.netlify.app/winm4g.html#%E6%96%B9%E6%B3%95
position定位的
absolute :生成绝对定位的元素, 相对于最近一级的 定位不是 static 的父元素来进行定位。 fixed (老IE不支持)生成绝对定位的元素,通常相对于浏览器窗口或 frame 进行定位。 relative 生成相对定位的元素,相对于其在普通流中的位置进行定位。 static 默认值。没有定位,元素出现在正常的流中 sticky 生成粘性定位的元素,容器的位置根据正常文档流计算得出
盒子中根据内容撑开,但盒子高度比行内元素高度高
1 | <div class="thumb" style="width: 500px;"> |
原因:基线问题,img是行内块元素,一种类似text的元素,在结束的时候,会在末尾加上一个空白符,在块元素里默认有3px或者4px空白(基线对齐所导致)

蒙版
1 | .page{ |
三角形
1 | #box { |
css3
盒模型
https://www.imooc.com/article/68238

标准盒子模型
标准盒模型又称W3C标准盒模型,其中标准盒模型的 width 等于 content 的宽度,标准盒模型的 height 等于 content 的高度。 标准盒大小计算公式:width(content) + padding + border + margin
怪异盒模型/IE盒子模型
怪异盒模型又称IE盒子模型,其中怪异盒子模型的 width 等于 content + padding + border 的宽度,怪异盒子模型的 height 等于 content + padding + border 的高度。 怪异盒大小的计算公式:width(content + padding + border) + margin
box-sizing 常用的属性有哪些?分别有什么作用
box-sizing: content-box;默认的标准(W3C)盒模型元素效果box-sizing: border-box;触发怪异(IE)盒模型元素的效果box-sizing: inherit;继承父元素box-sizing属性的值
阴影
文本阴影:text-shadow
color length lenth opacity [ inset(阴影向内) ]
颜色 水平偏移量 垂直偏移量 模糊度 (缩展量)
边框阴影 :border-shadow
box-shadow:[inset(阴影向内)] 水平偏移量 垂直偏移量 模糊度 (缩展量) 颜色
边框圆角box-radius
四个属性值,分别表示左上角、右上角、右下角、左下角的圆角大小(顺时针方向)
三个属性值,第一个值表示左上角,第二个值表示右上角和左下角(对角),第三个值表示右下角。
两个属性值,第一个值表示左上角和右下角,第二个值表示右上角和左下角
斜杠二组值:第一组值表示水平半径,第二组值表示垂直半径,每组值也可以同时设置1到4个值,规则与上面相同。 border-radius:100px/40px;
outline : outline-color ||outline-style || outline-width
设置或检索对象外的线条轮廓。outline画在border外面,并且不一定是矩形
边框图像
border-image-source: url(images/border.png); border-image-slice: 27;上、右、下、左侧边缘裁剪27像素,图像被分割为九个区域:四个角、四条边以及一个中间区域。 border-image-width: 10px;指定图像边界的宽度: border-image-repeat: round/stretch/repeat;
背景
background:color url repeat position attachment
设置背景颜色会填充content,padding。
连写的时候没有顺序要求,url为必写项
background-position:left top
background-attachment : scroll | fixed
scroll : 背景图像是随对象内容滚动 fixed : 背景图像固定
background-clip:padding-box/content-box/border-box; 修改背景颜色区域/规定背景的绘制区域。
background-origin: border-box;修改背景图片所在区域
**background-position:**center center;图片水平垂直居中
background-size cover 会使“最大”边,进行缩放,另一边同比缩放,铺满容器,超出部分会溢出。 contain 会使“最小”边,进行缩放,另一边同比缩放,不一定铺满容器,会完整显示图片。
渐变
https://juejin.cn/post/7170686085427625992
background-image:linear-gradient();radial-gradient() repeating-linear-gradient repeating-radial-gradient
多列布局
css3媒体查询
1 | @media screen and (max-width:600px) { |
动画
http://www.animate.net.cn/1853.html
过渡transition
第一种叫过渡(transition)动画,就是从初始状态过渡到结束状态这个过程中所产生的动画。所谓的状态就是指大小、位置、颜色、变形(transform)等等这些属性。css过渡只能定义首和尾两个状态,所以是最简单的一种动画。
参数
- property – 什么属性将用动画表现,例如, opacity。
- duration – 过渡的时间
- transition-delay – 设置过渡延时
- timing-function – 过渡的速度
- 匀速linear 逐渐降速ease 加速ease-in 降速ease-out 先加速后减速ease-in-out
1 | transform 和 transition 属性实现简单旋转效果的例子: |
关键帧动画
第二种叫做关键帧(keyframes)动画。不同于第一种的过渡动画只能定义首尾两个状态,关键帧动画可以定义多个状态,或者用关键帧来说的话,过渡动画只能定义第一帧和最后一帧这两个关键帧,而关键帧动画则可以定义任意多的关键帧,因而能实现更复杂的动画效果。
关键帧动画的定义方式也比较特殊,它使用了一个关键字 @keyframes 来定义动画。具体格式为:
1 | @keyframes 动画名称{ |
参数
- animation-name:动画名称
- animation-duration: 动画完成一个周期所花费的秒,默认为0
- animation-timing-function: 动画的速度,默认ease
- animation-delay:动画延时,默认为0
- animation-iteration-count: 动画播放次数,默认为1,infinite无限次
- animation-direction:动画是否再下一个周期逆向播放
- animation-play-state:动画是否正在运行或暂停,默认是running,paused
- animation-fill-mode:动画时间之外的状态

这段代码定义了一个名为demo,且有5个关键帧的动画。0% ,10% 等这些表示的是时间点,是相对于整个动画的持续时间来说的,时间点之后的花括号里则是元素的状态属性集合,描述了这个元素在这个时间点的状态,动画发生时,就是从第一个状态到第二个状态进行过渡,然后从第二个状态到第三个状态进行过渡,直到最后一个状态。一般来说,0%和100%这两个关键帧是必须要定义的。

注意,为了达到最佳的浏览器兼容效果,在实际书写代码的时候,还必须加上各大浏览器的私有前缀
转化transform
CSS**transform**属性允许你旋转,缩放,倾斜或平移给定元素。
示例:https://www.vps5.com/example?pid=2959
transform: rotate(360deg);旋转
transform: skew(45deg);倾斜
transform: scale(1.5);盒子扩大1.5倍
1
2
3
4如何实现小于12px的字体效果
transform:scale()这个属性只可以缩放可以定义宽高的元素,而行内元素是没有宽高的,我们可以加上一个display:inline-block;
transform: scale(0.7);transform: translate(400px) 向左移动400px translate(-50%,-50%) 作用是,往上(x轴),左(y轴)移动自身长宽的 50%
3D
3D 转换方法
| 函数 | 描述 |
|---|---|
| matrix3d(n,n,n,n,n,n, n,n,n,n,n,n,n,n,n,n) | 定义 3D 转换,使用 16 个值的 4x4 矩阵。 |
| translate3d(x,y,z) | 定义 3D 转化。 |
| translateX(x) | 定义 3D 转化,仅使用用于 X 轴的值。 |
| scale3d(x,y,z) | 定义 3D 缩放转换。 |
| scaleX(x) | 定义 3D 缩放转换,通过给定一个 X 轴的值。 |
| rotate3d(x,y,z,angle) | 定义 3D 旋转。 |
| rotateX(angle) | 定义沿 X 轴的 3D 旋转。 |
3D 转换属性
transform:向元素应用 2D 或 3D 转换
transform-origin:变形的原点,允许你改变被转换元素的位置。默认情况,变形的原点在元素的中心点,或者是元素X轴和Y轴的50%处。
示例:https://www.w3school.com.cn/example/css3/demo_css3_transform-origin.html
transform-style:规定被嵌套元素如何在 3D 空间中显示。
设置transform-style的值为flat,则该元素的所有子元素都将被平展到该元素的2D平面中呈现
设置transform-style的值为preserve-3d,它表示不执行平展操作,他的所有子元素位于3D空间中
示例:https://www.w3school.com.cn/tiy/t.asp?f=eg_css3_transform-style
perspective:定义 3D 元素的景深,当为元素定义 perspective 属性时,其子元素会获得透视效果,而不是元素本身(透视效果是写在父亲身上,而不是元素本身)。
用来设置用户和元素3D空间Z平面之间的距离。值越小,用户与3D空间Z平面距离越近,视觉效果更令人印象深刻;反之,值越大,用户与3D空间Z平面距离越远,视觉效果就很小。
示例:https://www.w3school.com.cn/tiy/t.asp?f=eg_css3_perspective1
perspective-origin:perspective属性的源点角度
backface-visibility:定义元素在不面对屏幕时是否可见。
预编译器
less、scss/sass区别
less、scss/sass
scss/sass是动态样式语言,比css多出很多功能(如变量、嵌套、运算,混入(Mixin)、继承、颜色处理,函数等),更方便阅读和维护。
less也是动态样式语言,一样也比css多处很多功能(如变量,继承,运算, 函数), Less 既可以在客户端上运行,也可在服务端运行 ( Node.js)。
scss和sass的关系 Sass是缩排语法,对于习惯css的web开发者来说很不直观,还是有点学习成本,也不能将css代码加入到sass里面,因此sass语法进行了改良,Sass 3就变成了Scss(sassy css)。与原来的语法兼容,只是用{}取代了原来的缩进,更容易阅读。
Sass/Scss与Less区别
编译环境
sass的安装需要Ruby环境,是在服务端处理的,而less是需要引入less.js来处理less代码输出css到浏览器,也可以在开发环节使用less,然后编译成css文件,直接放到项目中,也有 Less.app、SimpleLess、CodeKit.app这样的工具,也有在线编译地址。在一般前端项目里面使用 yarn add less yarn add less-loader添加到对应的项目里面。
变量
1、less、scss的变量符不一样
less是@、scss是$、css变量是两根连词线(- -)
2、变量作用域不一样
1 | /** Less-作用域*/ |
输出
less没有输出设置 scss提供四种输出选项:nested, compact, compressed 和 expanded。 有四种选择,默认为nested
nested:嵌套缩进的css代码 expanded:展开的多行css代码 compact:简洁格式的css代码 compressed:压缩后的css代码
条件语句
less不支持条件语句 scss语句支持if{}else{}、for{}循环语句
1 | /** if else */ |
引入外部css
scss引用的外部文件命名必须以_开头, 如下例所示:其中_test1.scss、_test2.scss、_test3.scss文件分别设置的h1 h2 h3。文件名如果以下划线_开头的话,sass会认为该文件是一个引用文件,不会将其编译为css文件.
1 | // 源代码: |
less引用外部文件和css中的@import没什么差异。
总结
sass/scss或是less,都可以看作为一种基于css之上的高级语言,其目的是使得css开发更灵活和更强大,sass的功能比less强大,基本可以说是一种真正的编程语言了,less则相对清晰明了,易于上手,对编译环境要求比较宽松,在实际开发中更倾向于选择less。但如果认真深入scss之后还是建议切换到scss,因为更加强大,更好用。
scss
数据类型
数字,1, 2, 13, 10px
字符串,有引号字符串与无引号字符串,”foo”, ‘bar’, baz
颜色,blue, #04a3f9, rgba(255,0,0,0.5)
布尔型,true, false
$a: true;$b: false; 只有自身是false和null才会返回false,其他一切都将返回true
空值,null
$value: null; 由于它代表空,所以不能够使用它与任何类型进行算数运算
数组 (list),用空格或逗号作分隔符,1.5em 1em 0 2em, Helvetica, Arial, sans-serif
maps, 相当于 JavaScript 的 object,(key1: value1, key2: value2)
变量
1 | $blue : #1875e7; |
如果变量需要镶嵌在字符串之中,就必须需要写在**#{}插值表达式**之中。
1 | $side : left; |
作用域
Sass变量的作用域只能在当前层级上有效果。
1 | $fontColor: #EEEEEE; |
可以使用!global关键词来设置变量为全局变量。
1 | // 此时body和a内自涂颜色都为green。 |
所有的全局变量我们一般定义在同一个文件,如:globals.scss,然后我们使用 @include来引入该文件。
计算功能
SASS允许在代码中使用算式:
1 | body { |
嵌套
SASS允许选择器嵌套。比如,下面的CSS代码:
1 | div h1 { |
可以写成:
1 | div { |
属性也可以嵌套,比如border-color属性,可以写成:
1 | p { |
在嵌套的代码块内,可以使用&引用父元素。比如a:hover伪类,可以写成:
1 | a { |
注释
SASS共有两种注释风格。
标准的CSS注释 /* comment */ ,会保留到编译后的文件。
单行注释 // comment,只保留在SASS源文件中,编译后被省略。
在/*后面加一个感叹号,表示这是”重要注释”。即使是压缩模式编译,也会保留这行注释,通常可以用于声明版权信息。
1
2
3/*!
重要注释!
*/
条件语句
1 | @if可以用来判断: |
代码的重用
继承
SASS允许一个选择器,继承另一个选择器。
1 | .class1 { |
class2要继承class1,就要使用@extend命令:
1 | .class2 { |
Mixin
Mixin有点像C语言的宏(macro),是可以重用的代码块。
使用@mixin命令,定义一个代码块。
1 | @mixin left { |
使用@include命令,调用这个mixin。
1 | div { |
mixin的强大之处,在于可以指定参数和缺省值。
1 | @mixin left($value: 10px) { |
使用的时候,根据需要加入参数:
1 | div { |
循环
使用@each 循环
1.循环一个 list: 类名为 icon-10px 、icon-12px、icon-14px 写他们的字体大小写法就可以如下:
2.循环一个 map:类名为 icon-primary、icon-success、icon-secondary 等,但是他们的值又都是变量,写法如下:
map-get
map-get(map,key) 函数的作用是根据 key 参数,返回 key 在 map 中对应的 value 值。如果 key 不存在 map 中,将返回 null 值。此函数包括两个参数:
map:定义好的 map。
key:需要遍历的 key。
假设要获取 facebook 键值对应的值 #3b5998,我们就可以使用 map-get() 函数来实现:
使用&嵌套覆盖原有样式
当一个元素的样式在另一个容器中有其他指定的样式时,可以使用嵌套选择器让他们保持在同一个地方。.no-opacity &相当于.no-opacity .foo。
map-merge
合并两个 map 形成一个新的 map 类型,即将 map2 添加到 map1的尾部
1 | $font-sizes: ("small": 12px, "normal": 18px, "large": 24px) |
@content
@content 用在 mixin 里面的,当定义一个 mixin 后,并且设置了 @content; @include 的时候可以传入相应的内容到 mixin 里面
js
常识
命名
1 | 变量的命名规则和规范:由字母、数字、下划线、$符号组成,不能以数字开头 |
堆栈
栈:
- 存储基础数据类型
- 栈会开辟一个内存
- 按值访问
- 存储的值大小固定
- 由系统自动分配内存空间
- 空间小,运行效率高
- 先进后出,后进先出
堆:
- 存储引用数据类型
- 堆共用同一个内存
- 按引用访问
- 存储的值大小不定,可动态调整
- 主要用来存放对象
- 空间大,但是运行效率相对较低
- 无序存储,可根据引用直接获取
区别
- 栈由系统自动分配,而堆是人为申请开辟
- 栈由系统自动分配,速度较快,而堆一般速度比较慢
- 栈是连续的空间,而堆是不连续的空间
对象序列化
百度:序列化(Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程
前端:对象序列化是指将对象的状态转换为字符串
1 | var obj = {x:1, y:2}; |
当这句代码运行时,对象obj的内容会存储在一块内存中,而obj本身存储的只是这块内存的地址的映射而已。简单的说,对象obj就是我们的程序在电脑通电时在内存中维护的一种东西,如果我们程序停止了或者电脑断电了,对象obj将不复存在。那么如何把对象obj的内容保存在磁盘上呢(也就是说在没电时继续保留着)?这时就需要把对象obj序列化,也就是说把obj的内容转换成一个字符串的形式,然后再保存在磁盘上。另外,我们又怎么通过HTTP协议把对象obj的内容发送到客户端呢?没错,还是需要先把对象obj序列化,然后客户端根据接收到的字符串再反序列化(也就是将字符串还原为对象)解析出相应的对象。这也正是”百度百科—序列化“中描述的两个作用——存储、传输。
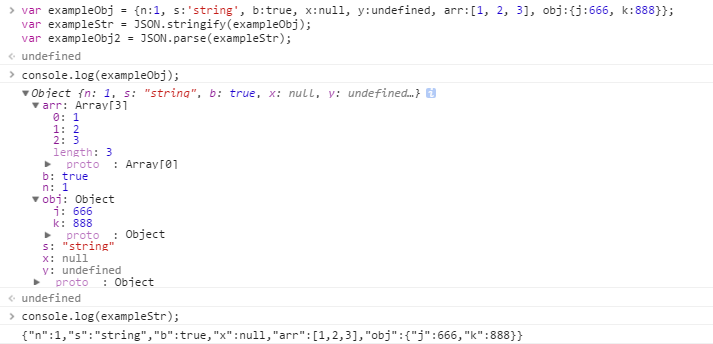
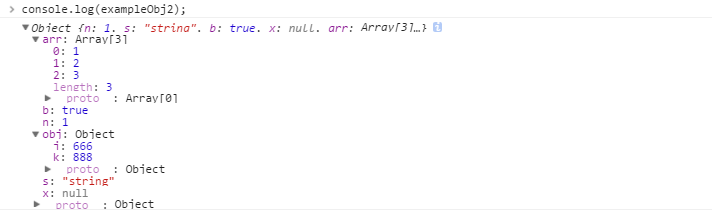
可以看到,exampleStr和exampleObj2中并没有 y:undefined 的内容。这说明:JSON的语法是JavaScript语法的子集,它并不能表示JavaScript中的所有值,对于JSON语法不支持的属性,序列化后会将其省略。
其详细规则如下:
①对于JavaScript中的五种原始类型,JSON语法支持数字、字符串、布尔值、null四种,不支持undefined;
②NaN、Infinity和-Infinity序列化的结果是null;
③JSON语法不支持函数;
④除了RegExp、Error对象,JSON语法支持其他所有对象;
⑤日期对象序列化的结果是ISO格式的字符串,但JSON.parse()依然保留它们字符串形态,并不会将其还原为日期对象;
⑥JSON.stringify()只能序列化对象的可枚举的自有属性;
闭包
局部变量无法共享和长久的保存,而全局变量可能造成变量污染,当我们希望有一种机制既可以长久的保存变量又不会造成全局污染。闭包就是指有权访问另一个函数作用域中的变量的函数
1 | function outterFn(){ |
需求:实现变量a 自增
1 | let a = 10; |
因为没有将闭包函数作为对象引用出去,所以执行之后,会被销毁
1 | let a = 10; |
将函数Add赋值给全局变量c时,Add会执行一次,并返回闭包函数,此时全局变量c的值为闭包函数的引用,此时函数Add虽然已执行完,但因为内部return的函数中包含上层函数链中的变量,所以函数 Add 的执行期上下文会继续保留在内存中,不会被JS的垃圾回收机制回收
闭包的优缺点
闭包的优点
- 可以减少全局变量的定义,避免全局变量的污染
- 能够读取函数内部的变量
- 在内存中维护一个变量,可以用做缓存
闭包的缺点
造成内存泄露
闭包会使函数中的变量一直保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。
解决方法——使用完变量后,手动将它赋值为null;
闭包可能在父函数外部,改变父函数内部变量的值。
造成性能损失。由于闭包涉及跨作用域的访问,所以会导致性能损失。
案例
模拟两人对话
1 | function person(name) { |
使setTimeout支持传参
1 | function func(param){ |
封装私有变量
1 | //用闭包定义能访问私有函数和私有变量的公有函数。 |
面向对象
https://segmentfault.com/a/1190000019250357
背景
(1)对象是单个实物的抽象。
一本书、一辆汽车、一个人都可以是对象,一个数据库、一张网页、一个远程服务器连接也可以是对象。当实物被抽象成对象,实物之间的关系就变成了对象之间的关系,从而就可以模拟现实情况,针对对象进行编程。
(2)对象是一个容器,封装了属性(property)和方法(method)。
属性是对象的状态,方法是对象的行为(完成某种任务)。比如,我们可以把动物抽象为animal对象,使用“属性”记录具体是哪一种动物,使用“方法”表示动物的某种行为(奔跑、捕猎、休息等等)。
JavaScript 语言使用构造函数(constructor)作为对象的模板。所谓”构造函数”,就是专门用来生成实例对象的函数。它就是对象的模板,描述实例对象的基本结构。一个构造函数,可以生成多个实例对象,这些实例对象都有相同的结构。
特征
封装
将一个事物所有的状态(属性),行为(方法)封装成一个对象
多态
封装的对象生成不同的单个对象
继承
直接创建对象
1 | var obj = new Object(); |
这种方式创建对象简单,但也存在一些问题:创建出来的对象无法实现对象的重复利用,并且没有一种固定的约束,操作起来可能会出现这样或者那样意想不到的问题。如下面这种情况。
1 | var a = new Object(); |
工厂模式
1 | var createPerson = function (name, age) { |
缺点:1.无法识别对象类型; 2.每个对象都有自己的 sayName 函数,函数不能共享,造成内存浪费
构造函数
1 | const p1 = { |
构造函数模式和工厂模式存在一下不同之处:
- 没有显示的创建对象(new Object() 或者 var a = {})
- 直接将属性和方法赋给this对象
- 没有return语句
- 函数共享
原型链

①所有
引用类型都有一个__proto__(隐式原型)属性,属性值是一个普通的对象 ②所有函数都有一个prototype(原型)属性,属性值是一个普通的对象 ③所有引用类型的__proto__属性指向构造函数的prototype
1 | var a = [1,2,3]; |
所有对象都有自己的原型对象(prototype)。原型对象的所有属性和方法,都能被实例对象共享。当我们访问对象的属性或者方法时,会优先访问实例对象自身的属性和方法。
当访问一个对象的某个属性时,会先在这个对象本身属性上查找,如果没有找到,则会去它的
__proto__隐式原型上查找,即它的构造函数的prototype,如果还没有找到就会再在构造函数的prototype的__proto__中查找,这样一层一层向上查找就会形成一个链式结构,我们称为原型链。
如果一层层地上溯,所有对象的原型最终都可以上溯到Object.prototype,即Object构造函数的prototype属性。也就是说,所有对象都继承了Object.prototype的属性。这就是所有对象都有valueOf和toString方法的原因,因为这是从Object.prototype继承的。
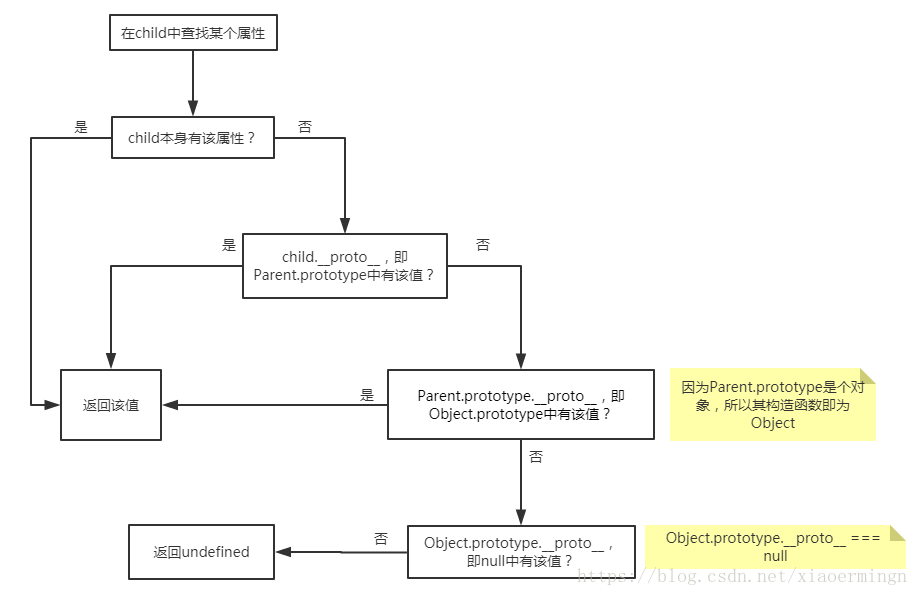
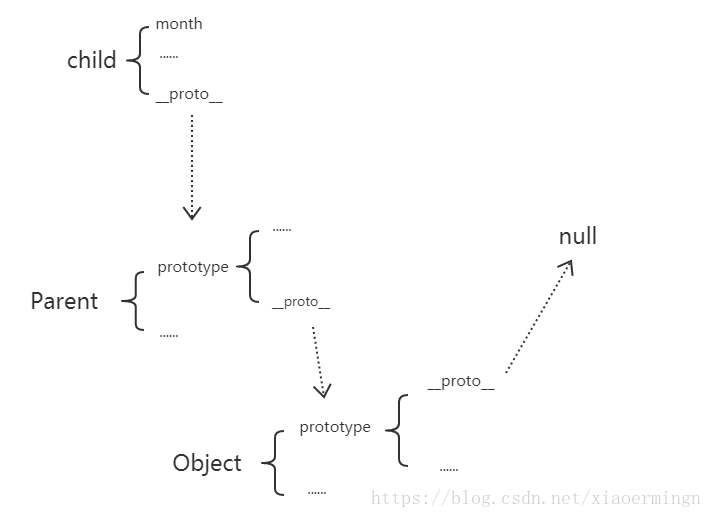
Object.prototype的原型是null。null没有任何属性和方法,也没有自己的原型。因此,原型链的尽头就是null。
1 | console.log(Object.getPrototypeOf(Object.prototype));// null |
new 命令的机制
1 | // 先一本正经的创建一个构造函数,其实该函数与普通函数并无区别 |
使用new命令时,它后面的函数依次执行下面的步骤。
- 创建一个空对象,作为将要返回的对象实例。
- 将这个空对象的原型,指向构造函数的
prototype属性。 - 将这个空对象赋值给构造函数内部的
this关键字。 - 开始执行构造函数内部的代码。
__proto__
当一个实例对象被创建时,这个构造函数将会把它的属性prototype赋给实例对象的内部属性__proto__。proto是指向构造函数原型对象的指针。
constructor
prototype对象有一个constructor属性,默认指向prototype对象所在的构造函数。
1 | function P() {} |
由于constructor属性定义在prototype对象上面,意味着可以被所有实例对象继承。
1 | function P() {} |
上面代码中,p是构造函数P的实例对象,但是p自身没有constructor属性,该属性其实是读取原型链上面的P.prototype.constructor属性。
instanceof
instanceof 是用来判断 A 是否为 B 的实例(不能判断一个对象实例具体属于哪种类型)
表达式为:A instanceof B。如果 A 是 B 的实例,则返回 true,否则返回 false。
在这里需要特别注意的是:instanceof 检测的是原型,我们用一段伪代码来模拟其内部执行过程:
1 | instanceof (A,B) = { |
从上述过程可以看出,当 A 的 proto 指向 B 的 prototype 时,就认为 A 就是 B 的实例,我们再来看几个例子:
1 | [] instanceof Array; // true |
虽然 instanceof 能够判断出 [ ] 是Array的实例,但它认为 [ ] 也是Object的实例
我们来分析一下 [ ]、Array、Object 三者之间的关系:
从 instanceof 能够判断出 [ ].proto 指向 Array.prototype,而 Array.prototype.proto 又指向了Object.prototype,最终 Object.prototype.proto 指向了null,标志着原型链的结束。因此,[]、Array、Object 就在内部形成了一条原型链:

从原型链可以看出,[] 的 proto 直接指向Array.prototype,间接指向 Object.prototype,所以按照 instanceof 的判断规则,[] 就是Object的实例。依次类推,类似的 new Date()、new Person() 也会形成一条对应的原型链 。因此,instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
判断是否是数组
1 | [] instanceof Array; // true |
判断某个对象是否是某个构造函数的实例
1 | function a(){} |
继承
https://blog.csdn.net/qq_42926373/article/details/83149347
首先创建一个构造函数,并为其设置私有属性和公有属性。
1 | // 定义一个人类 |
原型链继承
重点圈起来:将父类实例赋值给子类原型对象
1 | function Super(name, age) { |
优点
简单易于实现,父类的新增的方法与属性子类都能访问。
缺点
1)可以在子类中增加实例属性,如果要新增加原型属性和方法需要在 new 父类构造函数的后面
2)创建子类实例时,不能向父类构造函数中传参数。
构造继承
重点圈起来:执行父构造,将This指向本身,拉取父私有属性
1 | function Super(name, age, score) { |
优点
只需要继承父类的属性时这种方式很简单。
缺点
只能继承父类自己的属性,父类原型上的属性与方法也不能继承。
组合继承
1 | function Super(name, age, score) { |
优点
组合继承避免了原型链和借用构造函数的缺陷,融合了它们的优点。而且,使用 instanceof 操作符和isPrototype()方法也能够用于识别基于组合继承创建的对象。
缺点
会调用两次父类型构造函数:一次是在创建子类型原型的时候,另一次是在子类型构造函数内部。
this指向
this 是和执行上下文绑定的,也就是说每个执行上下文中都有一个 this。
实质
JavaScript 语言之所以有 this 的设计,跟内存里面的数据结构有关系。
1 | var obj = { foo: 5 }; |
上面的代码将一个对象赋值给变量obj。JavaScript 引擎会先在内存里面,生成一个对象{ foo: 5 },然后把这个对象的内存地址赋值给变量obj。也就是说,变量obj是一个地址(reference)。后面如果要读取obj.foo,引擎先从obj拿到内存地址,然后再从该地址读出原始的对象,返回它的foo属性。
原始的对象以字典结构保存,每一个属性名都对应一个属性描述对象。举例来说,上面例子的foo属性,实际上是以下面的形式保存的。
1 | { |
注意,foo属性的值保存在属性描述对象的value属性里面。
这样的结构是很清晰的,问题在于属性的值可能是一个函数。
1 | var obj = { foo: function () {} }; |
这时,引擎会将函数单独保存在内存中,然后再将函数的地址赋值给foo属性的value属性。
1 | { |
由于函数是一个单独的值,所以它可以在不同的环境(上下文)执行。
1 | var f = function () {}; |
JavaScript 允许在函数体内部,引用当前环境的其他变量。
1 | var f = function () { |
上面代码中,函数体里面使用了变量x。该变量由运行环境提供。
现在问题就来了,由于函数可以在不同的运行环境执行,所以需要有一种机制,能够在函数体内部获得当前的运行环境(context)。所以,this就出现了,它的设计目的就是在函数体内部,指代函数当前的运行环境。
1 | var f = function () { |
上面代码中,函数体里面的this.x就是指当前运行环境的x。
1 | var f = function () { |
上面代码中,函数f在全局环境执行,this.x指向全局环境的x;在obj环境执行,this.x指向obj.x。
类型指向
https://blog.csdn.net/m0_65450343/article/details/123109326
全局作用域中的this
在严格模式下,在全局作用域中,this指向window对象
全局作用域中函数中的this
- 在非严格模式下: this的指向依旧是window对象
- 在严格模式下:this的指向是undefined
1 | "use strict"; |
对象方法中的this
在严格模式下,对象的函数中的this指向调用函数的对象实例
1 | console.log("在对象的函数中的this"); |
特殊情况
- ```js
const obj = {
name() {
}console.log(this) //obj function fn() { console.log(this) //window } fn()
}
obj.name()const obj = {1
2
3
4
5
6
7
如何让函数fn也能使用当前obj这个对象了
1. 将this赋值给that
2. 使用箭头函数
}name() { console.log(this) //obj const fn = () => { console.log(this) //window } fn() }
obj.name()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 将对象中方法赋值给变量
```js
const a = {
a: 10,
b: {
a: 12,
fn: function () {
console.log(this);
}
}
}
const j = a.b.fn
a.b.fn()//12
j()//window
构造函数的this
this指向构造函数的实例对象
1 | function constru() { |
setTimeout
超时调用(setTimeout回调)的代码都是在全局作用域环境中执行的
1 | const a = { |
如果定时器中放箭头函数 ,则会将this指向所在的对象
1 | const a = { |
箭头函数
箭头函数体内的this对象,就是定义该函数时所在的作用域指向的对象,而不是使用时所在的作用域指向的对象。箭头函数没有自己的this, 它的this是继承而来; 默认指向在定义它时所处的对象(宿主对象),此处指父级作用域
1 | function foo() { |
因为所有的内层函数都是箭头函数,都没有自己的this,它们的this其实都是最外层foo函数的this。所以箭头函数的this指向是创建它所在的对象,不会改变。
React中this指向
https://blog.csdn.net/weixin_58207509/article/details/121185142
1 | import React from 'react' |

render方法中的this指向当前react组件。
事件处理程序中的this指向的是undefined
分析原因
class的内部,开启了局部严格模式use strict,所以this不会指向window而是undefined
onClick={this.fn}中,this.fn的调用并不是通过类的实例调用的,所以值是undefined
render函数是被组件实例调用的,因此render函数中的this指向当前组件
call、apply、bind
作用
他们的作用都是改变函数内部的this。这三个函数都是Function原型中的方法(所有的函数都是Function的
实例),也就是说只有函数才可以直接调用这些方法。
1 | function getDate(month, day) { |
参数
参数:三个函数的第一个参数都是需要绑定的 this。
call: 可以有n个参数,从第二个参数开始的所有参数都是原函数的参数。
foo.call(this, arg1,arg2, … ,argn );
bind: 可以有n个参数,从第二个参数开始的所有参数都是原函数的参数。
foo.bind(this, arg1,arg2, … ,argn)
apply:只有两个参数,并且第二个参数必须为数组,数组中的所有元素一一对应原函数的参数。
foo.apply(this, [ arg1,arg2, … ,argn ] );
call/apply 修改完this指向后,会立即调用原函数,但是 bind 只是修改this指向,并不会调用,调用后返回已经绑定好this的函数。
场景
- 处理伪数组 (最常用)
- 继承
- 取数组最大最小值
- 合并数组
源码
1 | //在函数原型上增加call1方法 |
高阶函数
高阶组件即高阶函数。React遵循函数式开发,而高阶组件这个概念其实是React社区繁衍出来的概念。
在这里我们要谨记这一句话,组件 = 函数。
高阶函数:一个函数,接受一个或多个函数作为参数并返回一个函数 。
高阶组件:一个函数,接受一个或多个组件作为参数并返回一个组件 。
实际应用场景
vue:防抖按钮
1 | // NewButton.vue |
使用新组件的时候
1 | // test.vue |
react:权限按钮
1 | import React, { FC } from 'react'; |
使用高阶组件
1 | import React from "react"; |
防抖/节流
https://www.jianshu.com/p/c8b86b09daf0
函数节流(throttle)与函数防抖(debounce)都是为了限制函数的执行频次,以优化函数触发频率过高导致的响应速度跟不上触发频率,出现延迟,假死或卡顿的现象。如鼠标移动事件onmousemove, 滚动滚动条事件onscroll,窗口大小改变事件onresize,瞬间的操作都会导致这些事件会被高频触发。
使用闭包
防抖
当持续触发事件时,n秒内没有再触发事件,事件处理函数才会执行一次,如果设定的时间到来之前,又一次触发了事件,就重新开始延时

1 | let div = document.querySelector("div"); |
节流
连续触发事件但是在 n 秒中只执行一次函数。节流会稀释函数的执行频率

1 | // 手写节流函数 |
内置方法
Math
1 | Math.PI // 圆周率 |
round
1 | Math.ceil(Math.random()*10); // 获取从 1 到 10 的随机整数,取 0 的概率极小。 |
Math.trunc()
1 | //1. |
Math.sign()
Math.sign方法用来判断一个数到底是正数、负数、还是零。
它会返回五种值。
- 参数为正数,返回+1;
- 参数为负数,返回-1;
- 参数为0,返回0;
- 参数为-0,返回-0;
- 其他值,返回NaN。
1 | Math.sign('') // 0 |
Math.cbrt()
方法用于计算一个数的立方根。对于非数值,Math.cbrt()方法内部也是先使用Number()方法将其转为数值。
实战
生成从minNum到maxNum的随机数
1 | //生成从minNum到maxNum的随机数 |
Date
**new Date()**创建新的日期对象
用整数初始化日期对象
new Date(yyyy,mth,dd,hh,mm,ss); new Date(yyyy,mth,dd);
注意:
- 您不能省略月份。如果只提供一个参数,则将其视为毫秒。
- 一位和两位数年份将被解释为 19xx 年:
1
2
3
4
5
6yyyy:四位数表示的年份
mth:用整数表示月份,从(1月)0到11(12月)
dd:表示一个 月中的第几天,从1到31
hh:小时数,从0(午夜)到23(晚11点)
mm: 分钟数,从0到59的整数
ss:秒数,从0到59的整数用字符串初始化日期对象
new Date(“2017/06/06”);
new Date(“2017-08-08”);
new Date(“month dd,yyyy hh:mm:ss”);
new Date(“month dd,yyyy”);
用毫秒时间戳初始化日期对象
new Date(ms);
1
2JavaScript 将日期存储为自 1970 年 1 月 1 日 00:00:00 UTC(协调世界时)以来的毫秒数。
零时间是 1970 年 1 月 1 日 00:00:00 UTC。
获取日期方法
| 方法 | 描述 |
|---|---|
| getDate() | 以数值返回天(1-31) |
| getDay() | 以数值获取周名(0-6) |
| getFullYear() | 获取四位的年(yyyy) |
| getHours() | 获取小时(0-23) |
| getMilliseconds() | 获取毫秒(0-999) |
| getMinutes() | 获取分(0-59) |
| getMonth() | 获取月(0-11) |
| getSeconds() | 获取秒(0-59) |
| getTime() | 获取时间(从 1970 年 1 月 1 日至今) |
1 | date.getFullYear()//获取完整的年份(4位,1970-????) |
日期设置方法
设置方法用于设置日期的某个部分。下面是最常用的方法(按照字母顺序排序):
| 方法 | 描述 |
|---|---|
| setDate() | 以数值(1-31)设置日 |
| setFullYear() | 设置年(可选月和日) |
| setHours() | 设置小时(0-23) |
| setMilliseconds() | 设置毫秒(0-999) |
| setMinutes() | 设置分(0-59) |
| setMonth() | 设置月(0-11) |
| setSeconds() | 设置秒(0-59) |
| setTime() | 设置时间(从 1970 年 1 月 1 日至今的毫秒数) |
时间戳转化为日期的方式
1 | // Mon May 28 2018 |
实战
纯js
1 | //时间差 |
1 | //比较时间 |
moment
获取前一天的日期
1 | moment(new Date()).subtract(1, "days").format("YYYY-MM-DD") |
比较时间
1 | compareTime = (startTime, endTime) => { |
以什么格式获取当前时间
1 | let now = moment().locale('zh-cn').format('YYYY-MM-DD HH:mm:ss'); |
距离当前时间60天的moment对象
1 | moment().subtract(60, 'days') |
传入年份和月份 获取该年对应月份的天数
1 | function getMonthDays(year,month){ |
两个时间相差多少天
分别获取两个日期的时间戳,相减得到数值是毫秒,再换算成天(即除以1 * 24 * 60 * 60 * 1000)即可。
1 | /** |
console
1 | console.log(window.console);//打印信息 |
defer和async
页面的加载和渲染过程:
- 浏览器通过HTTP协议请求服务器,获取HMTL文档并开始从上到下解析,构建DOM树;
- 在构建DOM过程中,如果遇到外联的样式声明和脚本声明,则暂停文档解析,创建新的网络连接,并开始下载样式文件和脚本文件;
- 样式文件下载完成后,构建样式表;脚本文件下载完成后,解释并执行,然后继续解析文档构建DOM
- 完成文档解析后,将DOM树和样式表进行关联和映射,最后将视图渲染到浏览器窗口
defer和async只对外部脚本有效(引入的js文件)
deferscript异步加载,html解析完,DomCOntentLoaded之前执行asyncscript加载完后会立即执行,执行的过程仍会阻塞后续html的解析

- 蓝色线代表网络读取,
- 红色线代表js执行时间
- 绿色线代表 HTML 解析。
- 通常情况下defer的使用频率较高,它能保证script之间的变量依赖。
- 需要注意的是:async script的资源请求时异步的,但script的执行仍然会阻塞后续渲染(单线程),defer是在html渲染完之后执行的所以不会阻塞后续html的解析。
setTimeout
setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式
| 参数 | 描述 |
|---|---|
| function | 必需。要调用的函数后要执行的 JavaScript 代码串。 |
| millisec | 可选。执行或调用 code/function 需要等待的时间,以毫秒计。默认为 0。 |
| param1, param2, … | 可选。 传给执行函数的其他参数(IE9 及其更早版本不支持该参数) |
1 | function show(x, y, z) { |
实例
看以下例子可以知道,代码运行为6次打印了6。因为setTimeout因为是一个异步函数,var变量存在变量提升、无块级作用域等,等执行到setTimeout时,for循环已经遍历结束,i的值已经是6。
1 | for (var i = 0; i < 6; i++) { |
解决办法
1、闭包;使用闭包将i的值驻留在内存中,打印j的值(形成了自己的作用域),实际的外部函数的变量i
1 | for (var i = 0; i < 6; i++) { |
2、setTimeout的第三个参数,该参数就是给setTimeout第一个函数的参数。每次传入setTimeout第一个函数的j值是for遍历的值,个人认为还是作用域的问题。
1 | for (var i = 0; i < 6; i++) { |
实战
看以下例子可以知道,代码运行为6次打印了6。因为setTimeout因为是一个异步函数,var变量存在变量提升、无块级作用域等,等执行到setTimeout时,for循环已经遍历结束,i的值已经是6。
1 | for (var i = 0; i < 6; i++) { |
解决办法
1、闭包;使用闭包将i的值驻留在内存中,打印j的值(形成了自己的作用域),实际的外部函数的变量i
1 | for (var i = 0; i < 6; i++) { |
2、setTimeout的第三个参数,该参数就是给setTimeout第一个函数的参数。每次传入setTimeout第一个函数的j值是for遍历的值,个人认为还是作用域的问题。
1 | for (var i = 0; i < 6; i++) { |
MutationObserver
https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver/MutationObserver
当父元素中的元素有删减,会调用该函数。
eg:点击按钮,table中添加tr,调用该函数,可以为tr中的input设置disabled
tip: 添加合理的判断条件,否则会执行死循环
数据类型
JS的基本数据类型和引用数据类型
- 基本数据类型:
undefined、null、boolean、number、string、symbol - 引用数据类型:
object、array、function
number
数值判断转换
NaN:not a number 该属性用于指示某个值不是数字。
- NaN 与任何值都不相等,包括他本身
isNaN: is not a number判断是否是数字,若是数字返回false
isFinite(number ) 函数用于检查其参数是否是无穷大。
提示: 如果 number 是 NaN(非数字),或者是正、负无穷大的数,则返回 false。
1 | undefined表示一个声明了没有初始化的变量,变量只声明的时候值默认是undefined |
转换成字符串类型:
- toString() String() 拼接字符串方式
转换成数值类型:
- 1.Number()可以把任意值转换成数值,如果要转换的字符串中有一个不是数值的字符,返回NaN
- 2.parseInt()
- 3.parseFloat()
实战
判断字符串或者数字是否是正整数
1 | const isInteger = (s) => { |
判断字符串或者数字是否是小数
1 | const isDecimal = (s) => { |
字符串
不会改变原来的字符串
charAt
charAt(index)
1 | 获取指定位置处字符 myString.charAt(1) |
charCodeAt() //获取指定位置处字符的ASCII码
indexOf
indexOf(‘’,[index] )
返回指定内容在元字符串中的位置,只找第一个匹配的,若没有则返回-1
indexOf(‘a’,2);从位置2开始找到a的位置 lastIndexOf() //从后往前找,只找第一个匹配的
lastIndexOf
lastIndexOf(‘’)
concat
拼接字符串,等效于+,+更常用
slice
提取字符串的一部分,并返回新的字符串
str.slice(start, end)
end 参数可选,start可取正值,也可取负值。
取正值时表示从索引为start的位置截取到end的位置(不包括end所在位置的字符,如果end省略则截取到字符串末尾) 取负值时表示从索引为 length+start 位置截取到end所在位置的字符
1 | ar str = "It is our choices that show what we truly are, far more than our abilities."; |
substring
str.slice(start, end) 取正值时表示从索引为start的位置截取到end的位置(不包括end所在位置的字符,如果end省略则截取到字符串末尾) 取负值时表示从索引为 length+start 位置截取到end所在位置的字符
substr
返回字符串指定位置开始的指定数量的字符。
substr(fromIndex,length)
start 表示开始截取字符的位置,可取正值或负值。取正值时表示start位置的索引,取负值时表示 length+start位置的索引。
length 表示截取的字符长度。
trim
trim()去除空白 只能去除字符串前后的空白,字符之间的空格不能去掉
toLocaleUpperCase
toLocaleLowerCase() 方法返回调用该方法的字符串被转换成小写的值,转换规则根据本地化的大小写映射toLocaleUpperCase() 方法则是转换成大写的值。
语法:str.toLocaleLowerCase(), str.toLocaleUpperCase()
1 | console.log('ABCDEFG'.toLocaleLowerCase()); // abcdefg |
split
split()字符转换为数组 split()还可以结合正则表达式
1 | var str='a,b,c,d'; |
includes(ES6)
includes() 方法基于ECMAScript 2015(ES6)规范,它用来判断一个字符串是否属于另一个字符。如果是,则返回true,否则返回false。
语法:str.includes(subString [, position])
subString 表示要搜索的字符串,position 表示从当前字符串的哪个位置开始搜索字符串,默认值为0。
1 | var str = "Practice makes perfect."; |
endsWith(ES6)
endsWith() 方法基于ECMAScript 2015(ES6)规范,它基本与 contains() 功能相同,不同的是,它用来判断一个字符串是否是原字符串的结尾。若是则返回true,否则返回false。
语法:str.endsWith(substring [, position])
与contains 方法不同,position 参数的默认值为字符串长度。
1 | var str = "Learn and live."; |
startsWith() 方法基于ECMAScript 2015(ES6)规范,它用来判断当前字符串是否是以给定字符串开始的,若是则返回true,否则返回false。
语法:str.startsWith(subString [, position])
1 | var str = "Where there is a will, there is a way."; |
实战
找到第一个不重复的字符,并返回它的索引
1 | const firstUniqChar = (s) => { |
数组
会改变原来数组的有:
pop()
删除数组的最后一个元素并返回删除的元素。
push()
向数组的末尾添加一个或更多元素,并返回新的长度。
shift()
删除并返回数组的第一个元素。
unshift()
向数组的开头添加一个或更多元素,并返回新的长度。reverse()—反转数组的元素顺序。
reverse()
翻转数组
sort()
arr.sort([comparefn])
- comparefn是可选的,如果省略,数组元素将按照各自转换为字符串的Unicode(万国码)位点顺序排序
- 如果指明了comparefn,数组将按照调用该函数的返回值来排序。若 a 和 b 是两个将要比较的元素:
- 若 comparefn(a, b) < 0,那么a 将排到 b 前面;
- 若 comparefn(a, b) = 0,那么a 和 b 相对位置不变;
- 若 comparefn(a, b) > 0,那么a , b 将调换位置;
1 | //即使是数组sort也是根据字符,从小到大排序 |
sort()方法的比较逻辑为: 前一半的数组进行比较,并排好序,后一半数组再与前面排序好的数组的中间一个值比较(二分法,判断是与前面还是后面的数组比较,更快),并排序
splice()
1 | array.splice(index, howmany, item1, ....., itemX) |
参数值
| 参数 | 描述 |
|---|---|
| index | 必需。整数,指定在什么位置添加/删除项目,使用负值指定从数组末尾开始的位置。 |
| howmany | 可选。要删除的项目数。如果设置为 0,则不会删除任何项目。 |
| item1, …, itemX | 可选。要添加到数组中的新项目。 |
arr.splice(start,deleteCount[, item1[, item2[, …]]])
删除
1 | var array = ["apple","boy"]; |
插入
1 | var array = ["one", "two", "four"]; |
不会改变原来数组的有:
indexOf和lastIndexOf
indexOf(arr[i],[index] ) 从位置index查找arr[i]在数组中的位置,只找第一个匹配的,如果不存在,则返回-1。
concat()
将传入的数组或者元素与原数组合并,组成一个新的数组并返回。
语法:arr.concat(value1, value2, …, valueN)
1 | var array = [1, 2, 3]; |
若concat方法中不传入参数,那么将基于原数组浅复制生成一个一模一样的新数组(指向新的地址空间)。
1 | var array = [{a: 1}]; |
join()
将数组中的所有元素连接成一个字符串。
语法:arr.join([separator = ‘,’]) separator可选,缺省默认为逗号。
1 | var array = ['We', 'are', 'Chinese']; |
slice()
将数组中一部分元素浅复制存入新的数组对象,并且返回这个数组对象。
语法:arr.slice([start[, end]])
参数 start 指定复制开始位置的索引,end如果有值则表示复制结束位置的索引(不包括此位置)。
如果 start 的值为负数,假如数组长度为 length,则表示从 length+start 的位置开始复制,此时参数 end 如果有值,只能是比 start 大的负数,否则将返回空数组。
slice方法参数为空时,同concat方法一样,都是浅复制生成一个新数组。
1 | var array = ["one", "two", "three","four", "five"]; |
浅复制 是指当对象的被复制时,只是复制了对象的引用,指向的依然是同一个对象。下面来说明slice为什么是浅复制。
1 | var array = [{color:"yellow"}, 2, 3]; |
由于slice是浅复制,复制到的对象只是一个引用,改变原数组array的值,array2也随之改变。
toString和toLocaleString
ES6
from
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据结构Set和Map)。
1 | let arrayLike = { |
实际应用中,常见的类似数组的对象是DOM操作返回的NodeList集合,以及函数内部的arguments对象。Array.from都可以将它们转为真正的数组。
只要是部署了Iterator接口的数据结构,Array.from都能将其转为数组。
1 | c |
值得提醒的是,扩展运算符(…)也可以将某些数据结构转为数组。
1 | // arguments对象 |
扩展运算符背后调用的是遍历器接口(Symbol.iterator),如果一个对象没有部署这个接口,就无法转换。Array.from方法则是还支持类似数组的对象。所谓类似数组的对象,本质特征只有一点,即必须有length属性。因此,任何有length属性的对象,都可以通过Array.from方法转为数组,而此时扩展运算符就无法转换。
1 | Array.from({ length: 3 }); |
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
1 | Array.from(arrayLike, x => x * x); |
下面的例子是取出一组DOM节点的文本内容。
1 | let spans = document.querySelectorAll('span.name'); |
Array.of
Array.of方法用于将一组值,转换为数组。
1 | Array.of(3, 11, 8) // [3,11,8] |
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。
1 | Array() // [] |
Array.of基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一。
1 | Array.of() // [] |
copyWithin
数组实例的copyWithin方法,在当前数组内部,将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组。也就是说,使用这个方法,会修改当前数组。
1 | Array.prototype.copyWithin(target, start = 0, end = this.length) |
它接受三个参数。
- target(必需):从该位置开始替换数据。
- start(可选):从该位置开始读取数据,默认为0。如果为负值,表示倒数。
- end(可选):到该位置前停止读取数据,默认等于数组长度。如果为负值,表示倒数。
这三个参数都应该是数值,如果不是,会自动转为数值。
1 | [1, 2, 3, 4, 5].copyWithin(0, 3) |
上面代码表示将从3号位直到数组结束的成员(4和5),复制到从0号位开始的位置,结果覆盖了原来的1和2。
1 | // 将3号位复制到0号位 |
find和findIndex
数组实例的find方法,用于找出第一个符合条件的数组成员。它的参数是一个回调函数,所有数组成员依次执行该回调函数,直到找出第一个返回值为true的成员,然后返回该成员。如果没有符合条件的成员,则返回undefined。
1 | [1, 4, -5, 10].find((n) => n < 0) |
上面代码找出数组中第一个小于0的成员。
1 | [1, 5, 10, 15].find(function(value, index, arr) { |
上面代码中,find方法的回调函数可以接受三个参数,依次为当前的值、当前的位置和原数组。
数组实例的findIndex方法的用法与find方法非常类似,返回第一个符合条件的数组成员的位置,如果所有成员都不符合条件,则返回-1。
1 | [1, 5, 10, 15].findIndex(function(value, index, arr) { |
另外,这两个方法都可以发现NaN,弥补了数组的IndexOf方法的不足。
1 | [NaN].indexOf(NaN) |
上面代码中,indexOf方法无法识别数组的NaN成员,但是findIndex方法可以借助Object.is方法做到。
fill()
fill方法使用给定值,填充一个数组。
1 | ['a', 'b', 'c'].fill(7) |
上面代码表明,fill方法用于空数组的初始化非常方便。
entries和keys和values
ES6提供三个新的方法——entries(),keys()和values()——用于遍历数组。它们都返回一个遍历器对象(详见《Iterator》一章),可以用for...of循环进行遍历,唯一的区别是keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。
1 | for (let index of ['a', 'b'].keys()) { |
如果不使用for...of循环,可以手动调用遍历器对象的next方法,进行遍历。
1 | let letter = ['a', 'b', 'c']; |
includes()
Array.prototype.includes方法返回一个布尔值,表示某个数组是否包含给定的值,与字符串的includes方法类似。该方法属于ES7,但Babel转码器已经支持。
1 | [1, 2, 3].includes(2); // true |
数组的空位
数组的空位指,数组的某一个位置没有任何值。比如,Array构造函数返回的数组都是空位。
1 | Array(3) // [, , ,] |
上面代码中,Array(3)返回一个具有3个空位的数组。
注意,空位不是undefined,一个位置的值等于undefined,依然是有值的。空位是没有任何值,in运算符可以说明这一点。
1 | 0 in [undefined, undefined, undefined] // true |
上面代码说明,第一个数组的0号位置是有值的,第二个数组的0号位置没有值。
ES5对空位的处理,已经很不一致了,大多数情况下会忽略空位。
forEach(),filter(),every()和some()都会跳过空位。map()会跳过空位,但会保留这个值join()和toString()会将空位视为undefined,而undefined和null会被处理成空字符串。
1 | // forEach方法 |
ES6则是明确将空位转为undefined。
Array.from方法会将数组的空位,转为undefined,也就是说,这个方法不会忽略空位。
1 | Array.from(['a',,'b']) |
扩展运算符(...)也会将空位转为undefined。
1 | [...['a',,'b']] |
copyWithin()会连空位一起拷贝。
1 | [,'a','b',,].copyWithin(2,0) // [,"a",,"a"] |
fill()会将空位视为正常的数组位置。
1 | new Array(3).fill('a') // ["a","a","a"] |
for...of循环也会遍历空位。
1 | let arr = [, ,]; |
上面代码中,数组arr有两个空位,for...of并没有忽略它们。如果改成map方法遍历,空位是会跳过的。
entries()、keys()、values()、find()和findIndex()会将空位处理成undefined。
1 | // entries() |
由于空位的处理规则非常不统一,所以建议避免出现空位。
实战
根据数组长度创建一个一样长度的数组并初始化值为0
1 | const arr = new Array(5).fill(0) |
选择一个随机值
1 | const random = (arr) => arr[Math.floor(Math.random() * arr.length)] |
数组去重
https://zhuanlan.zhihu.com/p/90017508
1 | function removeDuplicate(arr) { |
数组中最大元素的下标
1 | function maxValIndex(arr){ |
找出数组中出现最多的元素和次数
1 | function findMost(arr) { |
数组对象
数组对象去重
1 | tempArr1 = tempArr1.filter((item,index) =>{ |
判断两个数组对象是否相等
数据转化
自动转换
赋值
不全等
null,NaN,undefined,0-0,+0,true,false
基本数据类型有隐式转换
字符串与数字比较 (等号两侧转化为数字,再比较)
1
2
3
4
5100 == "100" ==> 100 == 100 // true
100 == "99" ==> 100 == 99 // false
100 == "abc" ==> 100 == NaN // false
1 == "abc" ==> 1 == NaN // false
1 == "" ==> 1 == 0 // false字符串与布尔值比较(等号两侧转换为数字,再比较)
1
2
3
4"abc" == true ==> NaN == 1 // false
"abc" == false ==> NaN == 0 // false
"" == true ==> 0 == 1 // false
"" == false ==> 0 == 0 // true数字与布尔值比较(等号两侧转换为数字,再比较)
1
2
3
4
5
61 == true ==> 1 == 1 // true
0 == true ==> 0 == 1 // false
100 == true ==> 100 == 1 // false
1 == false ==> 1 == 0 // false
0 == false ==> 0 == 0 // true
100 == false ==> 100 == 0 // falseundefined 和 null
1
2
3
4
5
6undefined 与 null 比较特殊,比较相等性之前,不能将 null 和 undefined 转换成其他任何值。undefined 和 null 互相比较返回 true,和自身比较也返回 true,其他情况返回 false
undefiend == undefined // true
undefined == null // true
null == null // true
undefined == 其他值 // false
null == 其他值 // falseNaN
1
2
3NaN(非数值)也很特殊,NaN 和任何值(包括自己)比较都是返回 false
NaN == NaN // false
NaN == 其他值 // false
复杂数据类型
由于引用类型保存的是对象(包括数组,函数)的地址值,所以地址值不同的,返回的都是 false
等号两侧为不同的引用数据类型时
有且只有一侧为引用数据类型时
1
2
3
4
5
6
7
8[1,2] == 1 ==> NaN == 1 // false
[1,2] == true ==> NaN == 1 // false
[1] == 1 ==> 1 == 1 // true
[1] == '1' ==> '1' == '1' // true
[] == 0 ==> 0 == 0 // true
[] == '0' ==> '' == '0' // false
[] == '' ==> '' == '' // true
全等
1 | +0 === -0 //true |
自动转换布尔值
除了以下五个值,其他都是自动转为true。
undefinednull+0或-0NaN''(空字符串)
自动转换为字符串
具体规则是,先将复合类型的值转为原始类型的值,再将原始类型的值转为字符串。
字符串的自动转换,主要发生在字符串的加法运算时。当一个值为字符串,另一个值为非字符串,则后者转为字符串。
1 | '5' + 1 // '51' |
自动转换为数值
JavaScript 遇到预期为数值的地方,就会将参数值自动转换为数值。系统内部会自动调用Number()函数。
除了加法运算符(+)有可能把运算子转为字符串,其他运算符都会把运算子自动转成数值。
1 | '5' - '2' // 3 |
上面代码中,运算符两侧的运算子,都被转成了数值。
注意:
null转为数值时为0,而undefined转为数值时为NaN。
一元运算符也会把运算子转成数值。
1 | +'abc' // NaN |
强制转换
Number
基本类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 数值:转换后还是原来的值
Number(324) // 324
// 字符串:如果可以被解析为数值,则转换为相应的数值
Number('324') // 324
// 字符串:如果不可以被解析为数值,返回 NaN
Number('324abc') // NaN
// 空字符串转为0
Number('') // 0
// 布尔值:true 转成 1,false 转成 0
Number(true) // 1
Number(false) // 0
// undefined:转成 NaN
Number(undefined) // NaN
// null:转成0
Number(null) // 0Number函数将字符串转为数值,要比parseInt函数严格很多。基本上,只要有一个字符无法转成数值,整个字符串就会被转为NaN。1
2parseInt('42 cats') // 42
Number('42 cats') // NaN引用类型
简单的规则是,
Number方法的参数是对象时,将返回NaN,除非是包含单个数值的数组。1
2
3Number({a: 1}) // NaN
Number([1, 2, 3]) // NaN
Number([5]) // 5第一步,调用对象自身的
valueOf方法。如果返回原始类型的值,则直接对该值使用Number函数,不再进行后续步骤。第二步,如果
valueOf方法返回的还是对象,则改为调用对象自身的toString方法。如果toString方法返回原始类型的值,则对该值使用Number函数,不再进行后续步骤。第三步,如果
toString方法返回的是对象,就报错。请看下面的例子。
1
2
3
4
5
6
7
8
9const obj = { x: 1 };
console.log(Number(obj)); // NaN
// 等同于
if (typeof obj.valueOf() === 'object') {
console.log(Number(obj.toString()));
} else {
console.log(Number(obj.valueOf()));
}上面代码中,
Number函数将obj对象转为数值。背后发生了一连串的操作,首先调用obj.valueOf方法, 结果返回对象本身;于是,继续调用obj.toString方法,这时返回字符串[object Object],对这个字符串使用Number函数,得到NaN。1
2
3
4
5
6
7
8
9
10
11const obj = {
valueOf: function () {
return {};
},
toString: function () {
return {};
}
};
Number(obj)
// TypeError: Cannot convert object to primitive value上面代码的
valueOf和toString方法,返回的都是对象,所以转成数值时会报错。
string
基本类型
- 数值:转为相应的字符串。
- 字符串:转换后还是原来的值。
- 布尔值:
true转为字符串"true",false转为字符串"false"。 - undefined:转为字符串
"undefined"。 - null:转为字符串
"null"。
1
2
3
4
5String(123) // "123"
String('abc') // "abc"
String(true) // "true"
String(undefined) // "undefined"
String(null) // "null"引用类型
String方法的参数如果是对象,返回一个类型字符串;如果是数组,返回该数组的字符串形式。1
2String({a: 1}) // "[object Object]"
String([1, 2, 3]) // "1,2,3"String方法背后的转换规则,与Number方法基本相同,只是互换了valueOf方法和toString方法的执行顺序。- 先调用对象自身的
toString方法。如果返回原始类型的值,则对该值使用String函数,不再进行以下步骤。 - 如果
toString方法返回的是对象,再调用原对象的valueOf方法。如果valueOf方法返回原始类型的值,则对该值使用String函数,不再进行以下步骤。 - 如果
valueOf方法返回的是对象,就报错。
1
2
3
4
5
6
7
8
9
10
11var obj = {
valueOf: function () {
return {};
},
toString: function () {
return {};
}
};
String(obj)
// TypeError: Cannot convert object to primitive value- 先调用对象自身的
Boolean
Boolean()函数可以将任意类型的值转为布尔值。
它的转换规则相对简单:除了以下五个值的转换结果为false,其他的值全部为true。
undefinednull0(包含-0和+0)NaN''(空字符串)
1 | Boolean(undefined) // false |
当然,true和false这两个布尔值不会发生变化。
1 | Boolean(true) // true |
注意,所有对象(包括空对象)的转换结果都是true,甚至连false对应的布尔对象new Boolean(false)也是true(详见《原始类型值的包装对象》一章)。
1 | Boolean({}) // true |
判断数据类型
1、typeof
typeof 是一个操作符,其右侧跟一个一元表达式,并返回这个表达式的数据类型。返回的结果用该类型的字符串(全小写字母)形式表示,包括以下 7 种:
- 值类型(基本类型):字符串(String)、数字(Number)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol。
- 引用数据类型:对象(Object)、数组(Array)、函数(Function)。
1 | typeof''; // string 有效 |
注意:
- 对于基本类型,除 null 以外,均可以返回正确的结果。
- 对于引用类型,除 function 以外,一律返回 object 类型。
- 对于 null ,返回 object 类型。因为在定义typeof时还没有null这种类型。
其中,null 有属于自己的数据类型 Null , 引用类型中的 数组、日期、正则 也都有属于自己的具体类型,而 typeof 对于这些类型的处理,只返回了处于其原型链最顶端的 Object 类型,没有错,但不是我们想要的结果。
2、instanceof
instanceof 是用来判断 A 是否为 B 的实例(不能判断一个对象实例具体属于哪种类型)
表达式为:A instanceof B。如果 A 是 B 的实例,则返回 true,否则返回 false。
在这里需要特别注意的是:instanceof 检测的是原型,我们用一段伪代码来模拟其内部执行过程:
1 | instanceof (A,B) = { |
从上述过程可以看出,当 A 的 proto 指向 B 的 prototype 时,就认为 A 就是 B 的实例,我们再来看几个例子:
1 | [] instanceof Array; // true |
虽然 instanceof 能够判断出 [ ] 是Array的实例,但它认为 [ ] 也是Object的实例
我们来分析一下 [ ]、Array、Object 三者之间的关系:
从 instanceof 能够判断出 [ ].proto 指向 Array.prototype,而 Array.prototype.proto 又指向了Object.prototype,最终 Object.prototype.proto 指向了null,标志着原型链的结束。因此,[]、Array、Object 就在内部形成了一条原型链:
从原型链可以看出,[] 的 proto 直接指向Array.prototype,间接指向 Object.prototype,所以按照 instanceof 的判断规则,[] 就是Object的实例。依次类推,类似的 new Date()、new Person() 也会形成一条对应的原型链 。因此,instanceof 只能用来判断两个对象是否属于实例关系, 而不能判断一个对象实例具体属于哪种类型。
3、constructor
当一个函数 F被定义时,JS引擎会为F添加 prototype 原型,然后在 prototype上添加一个 constructor 属性,并让其指向 F 的引用。如下所示:
当执行 var f = new F() 时,F 被当成了构造函数,f 是F的实例对象,此时 F 原型上的 constructor 传递到了 f 上,因此 f.constructor == F

可以看出,F 利用原型对象上的 constructor 引用了自身,当 F 作为构造函数来创建对象时,原型上的 constructor 就被遗传到了新创建的对象上, 从原型链角度讲,构造函数 F 就是新对象的类型。这样做的意义是,让新对象在诞生以后,就具有可追溯的数据类型。
同样,JavaScript 中的内置对象在内部构建时也是这样做的:

- null 和 undefined 是无效的对象,因此是不会有 constructor 存在的,这两种类型的数据需要通过其他方式来判断。
- 函数的 constructor 是不稳定的,这个主要体现在自定义对象上,当开发者重写 prototype 后,原有的 constructor 引用会丢失,constructor 会默认为 Object

为什么变成了 Object?
因为 prototype 被重新赋值的是一个 { }, { } 是 new Object() 的字面量,因此 new Object() 会将 Object 原型上的 constructor 传递给 { },也就是 Object 本身。
因此,为了规范开发,在重写对象原型时一般都需要重新给 constructor 赋值,以保证对象实例的类型不被篡改。
4、toString
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格
式为 [object Xxx] ,其中 Xxx 就是对象的类型。
对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call /
apply 来调用才能返回正确的类型信息。
1 | Object.prototype.toString.call('') ; // [object String] |
遍历
数组
迭代方法 不会修改原数组
every()、filter()、forEach()、map()、some()
forEach()
指定数组的每项元素都执行一次传入的函数,返回值为undefined。
语法:arr.forEach(fn, thisArg)
fn 表示在数组每一项上执行的函数,接受三个参数:
- value 当前正在被处理的元素的值
- index 当前元素的数组索引
- array 数组本身
thisArg 可选,用来当做fn函数内的this对象。
1 | var array = [1, 3, 5]; |
map()
使用传入函数处理每个元素,并返回函数的返回值组成的新数组。
语法:arr.map(fn, thisArg)
参数介绍同 forEach 方法的参数介绍。
every()
数组的每一项执行的函数都满足条件就返回true
some()
对数组的每一项运行给定函数,如果该函数对任一项返回true,则返回true。
1 | let list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]; |
es6中的some也可实现此功能。some循环中只要有一个符合条件则会跳出循环体
filter()
执行函数过滤掉不符和条件的数组元素,返回复合条件的数组元素
语法:arr.filter(fn, thisArg)
1 | var array = [18, 9, 10, 35, 80]; |
0,undefined,null,false,"",''可以很容易地通过以下方法省略
1 | const array = [3, 0, 6, 7, '', false]; |
删除重复值
1 | const array = [5,4,7,8,9,2,7,5]; |
reduce()
reduce() 方法接收一个方法作为累加器,数组中的每个值(从左至右) 开始合并,最终为一个值。
语法:array.reduce(function(total, currentValue, currentIndex, arr), initialValue)
参数
| 参数 | 描述 |
|---|---|
| initialValue | 可选。传递给函数的初始值 |
| function(total,currentValue, index,arr) | 必需。用于执行每个数组元素的函数。 |
| 参数 | 描述 |
|---|---|
| total(累计器) | 必需。初始值, 或者计算结束后的返回值。 |
| currentValue(当前值) | 必需。当前元素 |
| currentIndex(当前索引) | 可选。当前元素的索引 |
| arr(源数组) | 可选。当前元素所属的数组对象。 |
代码
1 | [1,2,3,4].reduce((acc, cur) => { //不带初始值 |
初始值 initialValue 可以是任意类型。如果没有提供 initialValue,reduce 会从索引 1 的地方开始执行 callback 方法,跳过第一个索引。如果提供 initialValue,从索引 0 开始
entries()
方法基于ECMAScript 2015(ES6)规范,返回一个数组迭代器对象,该对象包含数组中每个索引的键值对。
语法:arr.entries()
1 | var array = ["a", "b", "c"]; |
keys
keys() 方法基于ECMAScript 2015(ES6)规范,返回一个数组索引的迭代器。(浏览器实际实现可能会有调整)
语法:arr.keys()
1 | var array = ["abc", "xyz"]; |
values()
values() 方法基于ECMAScript 2015(ES6)规范,返回一个数组迭代器对象,该对象包含数组中每个索引的值。其用法基本与上述 entries 方法一致。
语法:arr.values()
遗憾的是,现在没有浏览器实现了该方法,因此下面将就着看看吧。
1 | var array = ["abc", "xyz"]; |
for
for…in循环
精准的迭代,可以迭代对象的元素。也可以迭代数组。
【注意】使用for ... in,迭代的是元素(keys),对于数组来说,则为下标(0,1,2…,length-1)
1 | for(var key in arr) { |
for…of循环(ES6支持)
1 | for(let item of arr) { |
和for...in不同的是,for...of迭代出来的是值(value),对于数组来说,则是一个元素值。
对象
for…in
for…in遍历
1 | var book = { |
for … of遍历
此方法,不能遍历普通对象(因为能够被for…of正常遍历的,都需要实现一个遍历器Iterator。而数组、字符串、Set、Map结构,早就内置好了Iterator(迭代器),它们的原型中都有一个Symbol.iterator方法,而Object对象并没有实现这个接口(对象(Object)之所以没有默认部署Iterator接口,是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。),使得它无法被for…of遍历。),需要和Object.keys()搭配使用,先获取对象的所有key的数组 然后遍历:
1 | var book = { |
【注意】Object.values()返回对象所有的键值组成的数组,但是由于无法获取到key值,功能会比较残缺。
同时,由于Object.keys()返回一个数组,包括对象自身的(不含继承的)所有可枚举属性(不含Symbol属性).所以我们可以使用forEach()等上面的方法,来进行数组的遍历,再通过对象的访问来进行值的访问。
DOM操作
位置获取
概念
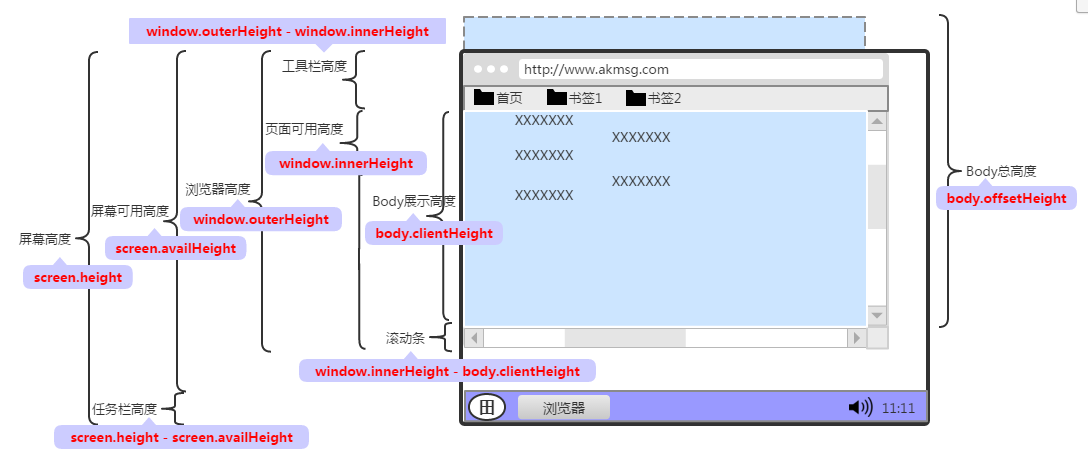
视口/浏览器窗口可视区域:不包括浏览器的 UI,菜单栏等——即指你正在浏览的文档的那一部分。
视口大小是可变的
document.documentElement.clientWidth
获取鼠标当前位置(事件对象)
- offsetX、offsetY: 鼠标的当前位置 相对于 目标节点的内填充边顶部、内填充边左部的位置。内填充边意思是不包含border,但包含padding,类似于padding-box。
- clientX、clientY: 鼠标当前位置 相对于 视口顶部、浏览器可视区域左部 的位置;
- pageY、pageX: 鼠标当前位置 相对于 页面/文档顶部、页面/文档左部的位置;
- screenY、screenX:鼠标当前位置 相对于 屏幕顶部、屏幕左部的位置;
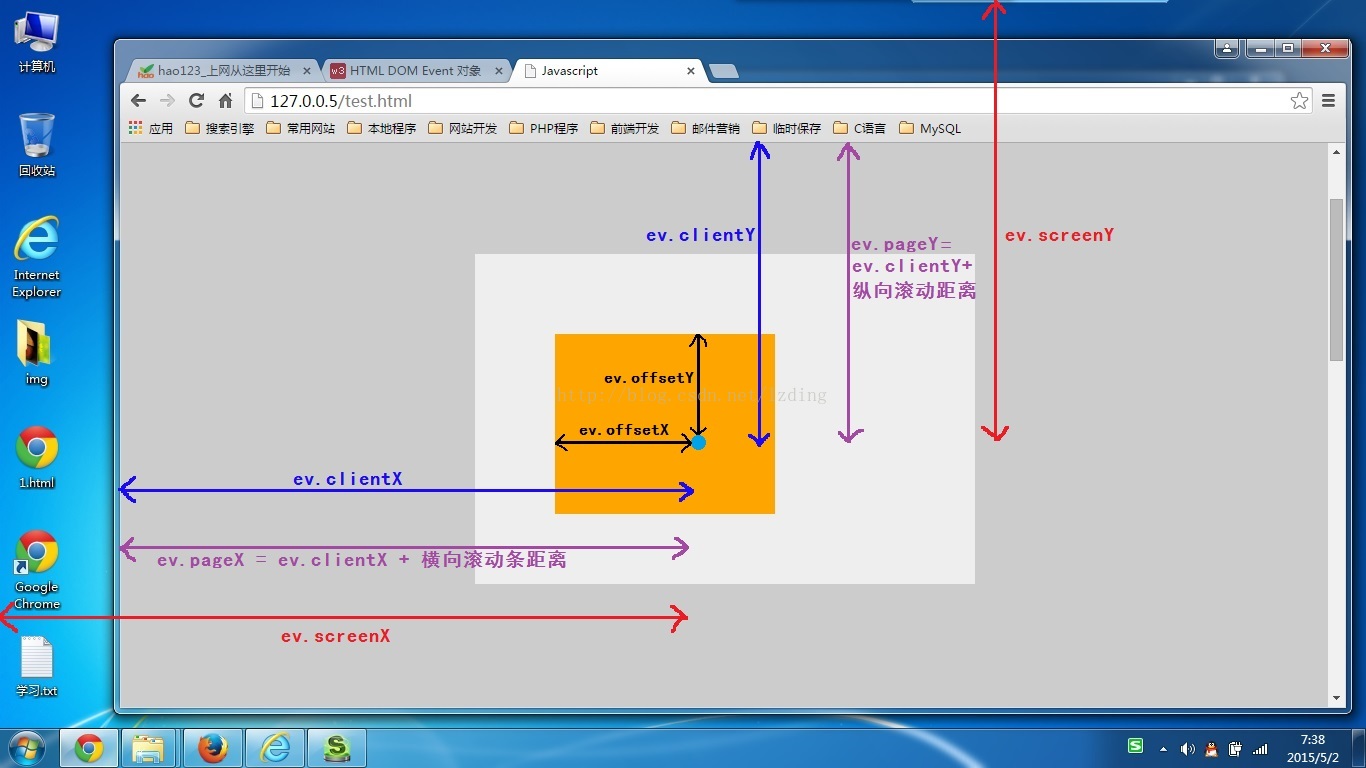
获取元素当前位置
Element.getBoundingClientRect() 获取元素相对于视口的位置
width、height:元素自身的宽高
top、bottom、left、right:分别是该元素的元素框(盒模型)上下左右位置距视口的距离。
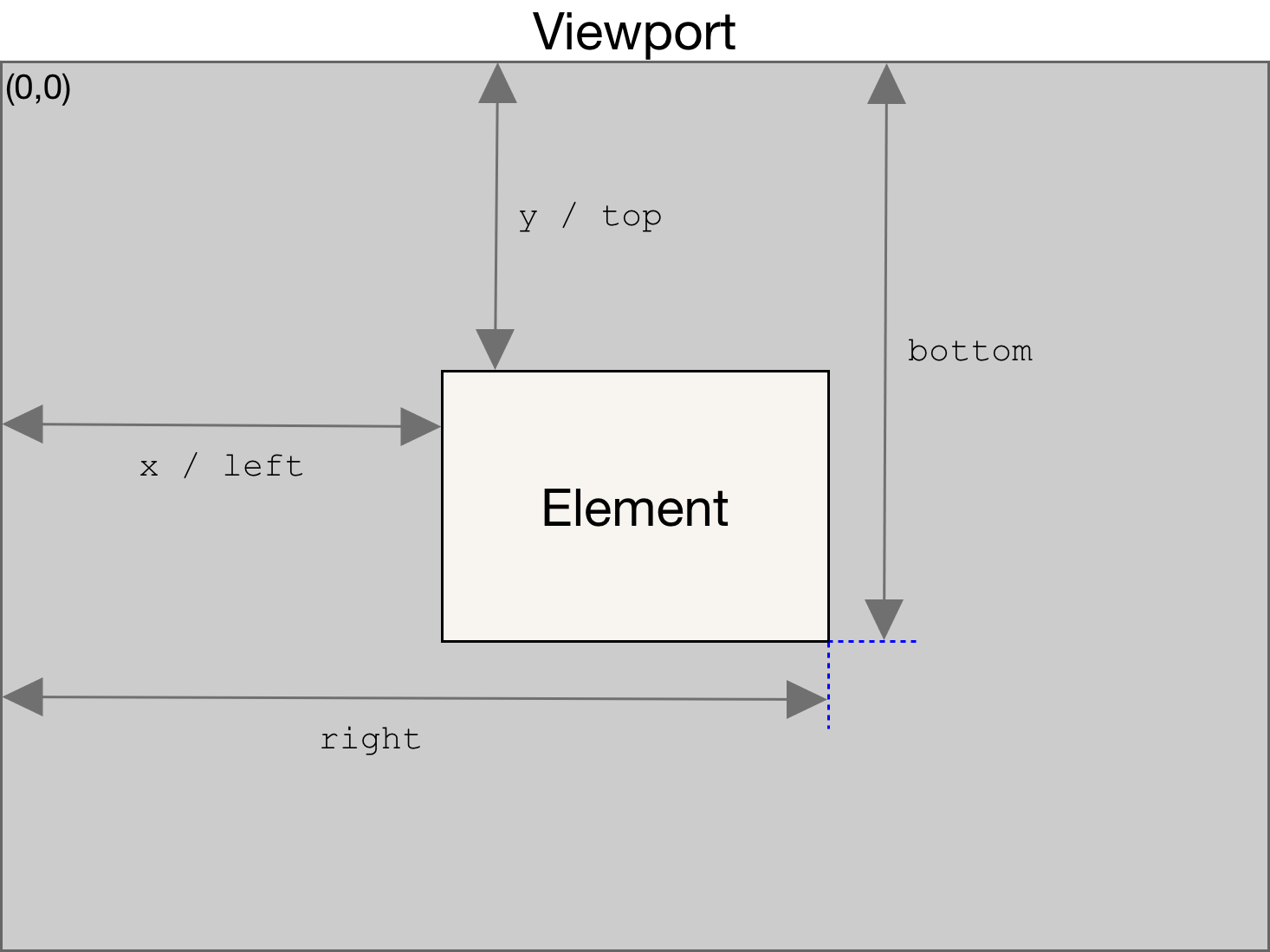
clientHeight:内容+padding(上下)
clientWidth:内容+padding(左右)
offsetTop:从边框border(不包含)距离父元素的高度距离
offsetLeft:从边框border(不包含)距离父元素的宽度距离
offsetHeight:内容+padding+border
offsetWidth: 内容+padding+border
scrolleft/top:读取或设置元素滚动条到元素左边的距离。
scrollWidth/height 总的宽/高(显示+隐藏的)
获取浏览器宽高
1 | window.outerWidth/Height获取浏览器显示区域,包括所有界面元素(如工具栏) |

1 | JQ |
滚动
window.scrollTo(options)方法,options是一个对象,有三个属性: top,left ,behavior 类型String,表示滚动行为,支持参数 smooth(平滑滚动),instant(瞬间滚动),默认值auto(等同于instant)
属性获取
js获取css属性值
- jquery方法
1
2
3
4//jquery方法
const jq_width = $('.box').css('width');
const jq_lineHeight = $('.box').css('line-height');
console.log(jq_width,jq_lineHeight);//200px 150px- 然后我们再用js原生方法去获取
1
2
3
4
5
6// 原生style.css方法
const box = document.querySelector('.box');
const js_width = box.style.width;
const js_lineHeight = box.style.lineHeight;
console.log(js_width,js_lineHeight);// 50px
//在这里我们会发现style.css方法只能获取到写在标签上的属性 style = "line-height:150px" 不能获取写在<style>``</style>中的css属性- 使用
window.getComputedStyle这个方法获取所有经过浏览器计算过的样式
elementNode.getAttribute(name):方法通过名称获取属性的值。
elementNode.setAttribute(name, value):方法创建或改变某个新属性。
elementNode.removeAttribute(name):方法通过名称删除属性的值。
节点元素获取
getElementsBy方法都是伪数组arguments
判断当前的子节点是否是元素节点 if (node.nodeType === 1)
parentNode 父元素 childNodes 所有子节点 children 所有的子元素
lastChild 获取最后一个子节点 lastElementChild 获取最后一个子元素
nextSibling 下一个兄弟节点 nextElementSibling 下一个兄弟元素
previousSibling 上一个兄弟节点 previousElementSibling 上一个兄弟元素
事件
事件流阶段
W3C中定义事件的发生经历三个阶段:捕获阶段(capturing)、目标阶段(targetin)、冒泡阶段(bubbling)
- 冒泡型事件:当你使用事件冒泡时,子级元素先触发,父级元素后触发
- 捕获型事件:当你使用事件捕获时,父级元素先触发,子级元素后触发
DOM事件流:同时支持两种事件模型:捕获型事件和冒泡型事件- 阻止冒泡:在
W3c中,使用stopPropagation()方法;在IE下设置cancelBubble = true - 阻止捕获:阻止事件的默认行为,例如
click - <a>后的跳转。在W3c中,使用preventDefault()方法,在IE下设置window.event.returnValue = false
监听事件
1 | .addEventListener('click', fn, false);//false(默认)是事件冒泡,true是事件捕获 |
事件委托
简介:事件委托指的是,不在事件的发生地(直接dom)上设置监听函数,而是在其父元素上设置监听函数,通过事件冒泡,父元素可以监听到子元素上事件的触发,通过判断事件发生元素DOM的类型,来做出不同的响应。
举例:最经典的就是ul和li标签的事件监听,比如我们在添加事件时候,采用事件委托机制,不会在li标签上直接添加,而是在ul父元素上添加。
好处:比较合适动态元素的绑定,新添加的子元素也会有监听函数,也可以有事件触发机制。可以大量节省内存占用,减少事件注册
事件对象event
target是事件触发的真实元素currentTarget是事件绑定的元素- 事件处理函数中的
this指向是中为currentTarget。 currentTarget和target,有时候是同一个元素,有时候不是同一个元素 (因为事件冒泡)- 当事件是子元素触发时,
currentTarget为绑定事件的元素,target为子元素- 若绑定父元素,点击子元素冒泡触发事件,e.target指向子元素
- 当事件是元素自身触发时,
currentTarget和target为同一个元素。
- 当事件是子元素触发时,
e.type点击对象的事件类型
1 | $("a").click(function(event) { |
事件
加载事件
- 当 DOMContentLoaded 事件触发时,仅当DOM加载完成,不包括样式表,图片。(譬如如果有async加载的脚本就不一定完成)
- 当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了。
顺序是:DOMContentLoaded -> load
页面加载完成有两种事件:
ready,表示文档结构已经加载完成(不包含图片等非文字媒体文件)
onload,指示页面包含图片等文件在内的所有元素都加载完成。
1
2
3
4window.onload = function () {
// 当页面加载完成执行
// 当页面完全加载所有内容(包括图像、脚本文件、CSS 文件等)执行
}onunload
1
2
3window.onunload = function () {
// 当用户退出页面时执行
}
鼠标事件
mouseup事件在释放按下的鼠标键时触发。
mousedown事件在按下鼠标键时触发。
mousemove事件当鼠标在一个节点内部移动时触发。当鼠标持续移动时,该事件会连续触发。为了避免性能问题,建议对该事件的监听函数做一些限定,比如限定一段时间内只能运行一次代码。
mouseover事件和mouseenter事件,都是鼠标进入一个节点时触发。
两者的区别是,mouseover事件会冒泡,mouseenter事件不会。子节点的mouseover事件会冒泡到父节点,进而触发父节点的mouseover事件。mouseenter事件就没有这种效果,所以进入子节点时,不会触发父节点的监听
mouseout事件和mouseleave事件,都是鼠标离开一个节点时触发。
两者的区别是,mouseout事件会冒泡,mouseleave事件不会。子节点的mouseout事件会冒泡到父节点,进而触发父节点的mouseout事件。mouseleave事件就没有这种效果,所以离开子节点时,不会触发父节点的监听函数。
拖拉事件
https://blog.csdn.net/u012060033/article/details/89787009
拖拉指的是,用户在某个对象上按下鼠标键不放,拖动它到另一个位置,然后释放鼠标键,将该对象放在那里。
拖拉的对象有好几种,包括Element节点、图片、链接、选中的文字等等。在HTML网页中,除了Element节点默认不可以拖拉,其他(图片、链接、选中的文字)都是可以直接拖拉的。为了让Element节点可拖拉,可以将该节点的draggable属性设为true。
1 | <div draggable="true"> |
draggable属性可用于任何Element节点,但是图片(img元素)和链接(a元素)不加这个属性,就可以拖拉。对于它们,用到这个属性的时候,往往是将其设为false,防止拖拉。
注意,一旦某个Element节点的draggable属性设为true,就无法再用鼠标选中该节点内部的文字或子节点了。
当Element节点或选中的文本被拖拉时,就会持续触发拖拉事件,包括以下一些事件:
- drag事件:拖拉过程中,在被拖拉的节点上持续触发。
- dragstart事件:拖拉开始时在被拖拉的节点上触发,该事件的target属性是被拖拉的节点。通常应该在这个事件的监听函数中,指定拖拉的数据。
- dragend事件:拖拉结束时(释放鼠标键或按下escape键)在被拖拉的节点上触发,该事件的target属性是被拖拉的节点。它与dragStart事件,在同一个节点上触发。不管拖拉是否跨窗口,或者中途被取消,dragend事件总是会触发的。
- dragenter事件:拖拉进入当前节点时,在当前节点上触发,该事件的target属性是当前节点。通常应该在这个事件的监听函数中,指定是否允许在当前节点放下(drop)拖拉的数据。如果当前节点没有该事件的监听函数,或者监听函数不执行任何操作,就意味着不允许在当前节点放下数据。在视觉上显示拖拉进入当前节点,也是在这个事件的监听函数中设置。
- dragover事件:拖拉到当前节点上方时,在当前节点上持续触发,该事件的target属性是当前节点。该事件与dragenter事件基本类似,默认会重置当前的拖拉事件的效果(DataTransfer对象的dropEffect属性)为none,即不允许放下被拖拉的节点,所以如果允许在当前节点drop数据,通常会使用preventDefault方法,取消重置拖拉效果为none。
- dragleave事件:拖拉离开当前节点范围时,在当前节点上触发,该事件的target属性是当前节点。在视觉上显示拖拉离开当前节点,就在这个事件的监听函数中设置。
- drop事件:被拖拉的节点或选中的文本,释放到目标节点时,在目标节点上触发。注意,如果当前节点不允许drop,即使在该节点上方松开鼠标键,也不会触发该事件。如果用户按下Escape键,取消这个操作,也不会触发该事件。该事件的监听函数负责取出拖拉数据,并进行相关处理。
关于拖拉事件,有以下几点注意事项。
拖拉过程只触发以上这些拖拉事件,尽管鼠标在移动,但是鼠标事件不会触发。
将文件从操作系统拖拉进浏览器,不会触发dragStart和dragend事件。
dragenter和dragover事件的监听函数,用来指定可以放下(drop)拖拉的数据。由于网页的大部分区域不适合作为drop的目标节点,所以这两个事件的默认设置为当前节点不允许drop。如果想要在目标节点上drop拖拉的数据,首先必须阻止这两个事件的默认行为,或者取消这两个事件。
1
2<div ondragover="return false">
<div ondragover="event.preventDefault()">上面代码中,如果不取消拖拉事件或者阻止默认行为,就不可能在div节点上drop被拖拉的节点。
addEventListener自定义事件
背景
在js事件中,我们首先想到的是click、dblclick、mouseover、mouseout、mouseenter、mouseleave、mousedown、mouseup、mousemove、wheel、contextmenu(点击鼠标右键时)这些常用的事件,在给第三方提供sdk使用时,这些预定义的事件有时无法满足我们的需求。
由于第三方sdk运行环境未知,而且可能会导致事件冲突的问题,这时候就需要我们自定义事件避免问题的发生。
自定义事件构造器
new Event(type[, options]);
type —— 事件类型,
自定义事件名称,可以是像这样
"click"的字符串,或者我们自己的像这样"my-event"的参数。options —— 具有两个可选属性的对象:
bubbles: true/false—— 如果为true,那么事件会冒泡。cancelable: true/false—— 如果为true,那么“默认行为”就会被阻止。稍后我们会看到对于自定义事件,它意味着什么。
默认情况下,以上两者都为 false:
{bubbles: false, cancelable: false}。
new CustomEvent
1
2
3
4
5
6
7
8
9
10
11
12<h1 id="elem">Hello for John!</h1>
<script>
// 事件附带给处理程序的其他详细信息
elem.addEventListener("hello", function(event) {
alert(event.detail.name);
});
elem.dispatchEvent(new CustomEvent("hello", {
detail: { name: "John" }
}));
</script>
从技术上讲,CustomEvent 和
Event一样。除了一点不同。在第二个参数(对象)中,我们可以为我们想要与事件一起传递的任何自定义信息添加一个附加的属性
detail。
dispatchEvent
Event 构造函数
使用Event 构造函数来创建一个新事件:
1 | let event = new Event(type, [,options]); |
Event 构造函数接受两个参数:
type:指定事件类型,比如
click。options:为对象类型,有两个属性:
bubbles:为布尔值,表示事件是否冒泡。如果为true,则事件冒泡,反之亦然。cancelable:也是布尔值,表示事件是否可以取消,如果为true,则可以取消,反之亦然。
1
默认`options`对象为:{ bubbles: false, cancelable: false}
dispatchEvent 方法
创建完事件后,我们就可以使用dispatchEvent() 方法在目标元素上触发它,像这样
1 | element.dispatchEvent(event); |
下面我在一个页面中来测试它:
1 | <button class="btn">测试dispatchEvent()方法</button> |
event.isTrusted
有一种方法可以区分“真实”用户事件和通过脚本生成的事件。
对于来自真实用户操作的事件,
event.isTrusted属性为true,对于脚本生成的事件,event.isTrusted属性为false
冒泡示例
我们可以创建一个名为 “hello” 的冒泡事件,并在 document 上捕获它。
我们需要做的就是将 bubbles 设置为 true:
1 | <h1 id="elem">Hello from the script!</h1> |
浏览器对象
window对象
navigator
navigator.userAgent用来区分设备和浏览器
userAgent 属性是一个只读的字符串,声明了浏览器用于 HTTP 请求的用户代理头的值。
打印
1
2
3<script>document.write("用户代理: " + navigator.userAgent);</script>
输出结果:
用户代理: Mozilla/5.0 (Linux; Android) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.109 Safari/537.36 CrKey/1.54.248666属性
1
2
3
4
5
6
7
8
9navigator.appVersion 浏览器的版本号
navigator.appName 浏览器的名称
navigator.language 浏览器使用的语言
navigator.platform 浏览器使用的平台
navigator.userAgent 浏览器的user-agent信息判断终端和环境
1
2
3
4
5
6
7
8var ua = navigator.userAgent.toLowerCase();
//终端
let isAndroid = ua.indexOf('Android') > -1 || u.indexOf('Linux') > -1
let isIOS = !!ua.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/)
//环境
ua.match(/weibo/i) == "weibo"
ua.indexOf('qq/')!= -1
ua.match(/MicroMessenger/i)=="micromessenger" //微信判断pc和手机端
1
2
3
4
5
6
7
8
9export const IsPC = () => {
var userAgentInfo = navigator.userAgent;
var Agents = new Array("Android", "iPhone", "SymbianOS", "Windows Phone", "iPad", "iPod");
var flag = true;
for (var v = 0; v < Agents.length; v++) {
if (userAgentInfo.indexOf(Agents[v]) > 0) { flag = false; break; }
}
return flag;
}isIPhoneX
1
2
3
4
5
6
7
8
9
10
11
12
13
14isIPhoneX() {
var u = navigator.userAgent;
var isIOS = !!u.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/); //ios终端
if (isIOS) {
if ((window.screen.height == 812 && window.screen.width == 375) || (window.screen.width === 414 && window.screen.height === 896)) {//有底部小黑条
//是iphoneX(375*812) iphoneXR(414*896) iphoneXS max(414*896) iphone11(414*896) iphone pro max(414*896)
return true
} else {//没有底部小黑条
return false
}
} else {
return false
}
},
在web应用程序中使用文件
Content-Type:multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格
网络
function updateOnline() {
console.log(‘999’);
console.log(navigator.onLine ? ‘online’ : ‘offline’);
}
window.addEventListener(‘online’, updateOnline);
window.addEventListener(‘offline’, updateOnline);
const connection = navigator.connection || navigator.mozConnection || navigator.webkitConnection;
connection.addEventListener(‘change’, () => {
// connection.effectiveType返回的是具体的网络状态:4g/3g/2g
console.log(connection.effectiveType);
});
History对象
Error对象
原生错误类型
SyntaxError 对象
SyntaxError对象是解析代码时发生的语法错误。
1 | // 变量名错误 |
ReferenceError 对象
ReferenceError对象是引用一个不存在的变量时发生的错误。
RangeError 对象
RangeError对象是一个值超出有效范围时发生的错误。
TypeError 对象
TypeError对象是变量或参数不是预期类型时发生的错误。比如,对字符串、布尔值、数值等原始类型的值使用new命令,就会抛出这种错误,因为new命令的参数应该是一个构造函数。
1 | new 123 |
上面代码的第二种情况,调用对象不存在的方法,也会抛出TypeError错误,因为obj.unknownMethod的值是undefined,而不是一个函数。
URIError 对象
URIError对象是 URI 相关函数的参数不正确时抛出的错误,主要涉及encodeURI()、decodeURI()、encodeURIComponent()、decodeURIComponent()、escape()和unescape()这六个函数。
总结
以上这6种派生错误,连同原始的Error对象,都是构造函数。开发者可以使用它们,手动生成错误对象的实例。这些构造函数都接受一个参数,代表错误提示信息(message)。
1 | var err1 = new Error('出错了!'); |
自定义错误
1 | function UserError(message) { |
上面代码自定义一个错误对象UserError,让它继承Error对象。然后,就可以生成这种自定义类型的错误了。
1 | new UserError('这是自定义的错误!'); |
throw 语句
1 | if (x <= 0) { |
上面代码中,throw抛出的是一个UserError实例。
throw也可以抛出自定义错误。
1 | function UserError(message) { |
上面代码中,throw抛出的是一个UserError实例。
throw可以抛出任何类型的值
1 | // 抛出一个字符串 |
try…catch 结构
一旦发生错误,程序就中止执行了。JavaScript 提供了try...catch结构,允许对错误进行处理,选择是否往下执行。
1 | try { |
try代码块抛出错误(上例用的是throw语句),JavaScript 引擎就立即把代码的执行,转到catch代码块,或者说错误被catch代码块捕获了。
finally 代码块
try...catch结构允许在最后添加一个finally代码块,表示不管是否出现错误,都必需在最后运行的语句。
FormData表单对象
https://wangdoc.com/javascript/bom/form
表单FormData对象
每一个控件都会生成一个键值对,所有的键值对都会提交到服务器。提交的数据格式跟<form>元素的method属性有关。只要键值不是 URL 的合法字符(比如汉字“张三”和“提交”),浏览器会自动对其进行编码。
点击submit控件,就可以提交表单。
1 | <form> |
表单里面的<button>元素如果没有用type属性指定类型,那么默认就是submit控件。
1 | <form> |
除了点击submit控件提交表单,还可以用表单元素的submit()方法,通过脚本提交表单。
1 | formElement.submit(); |
表单数据以键值对的形式向服务器发送,这个过程是浏览器自动完成的。但是有时候,我们希望通过脚本完成过程
FormData 首先是一个构造函数,用来生成实例。
1 | var formdata = new FormData(form); |
FormData 实例方法
创建表单:
1 | <form id="advForm"> |
通过表单元素作为参数,实现对formData的初始化:
1 | //获得表单按钮元素 |
发送数据:
1 | var btn=document.querySelector("#btn"); |
FormData.get(key):获取指定键名对应的键值,参数为键名。如果有多个同名的键值对,则返回第一个键值对的键值。FormData.getAll(key):返回一个数组,表示指定键名对应的所有键值。如果有多个同名的键值对,数组会包含所有的键值。FormData.set(key, value):设置指定键名的键值,参数为键名。如果键名不存在,会添加这个键值对,否则会更新指定键名的键值。如果第二个参数是文件,还可以使用第三个参数,表示文件名。FormData.delete(key):删除一个键值对,参数为键名。FormData.append(key, value):添加一个键值对。如果键名重复,则会生成两个相同键名的键值对。如果第二个参数是文件,还可以使用第三个参数,表示文件名。FormData.has(key):返回一个布尔值,表示是否具有该键名的键值对。FormData.keys():返回一个遍历器对象,用于for...of循环遍历所有的键名。FormData.values():返回一个遍历器对象,用于for...of循环遍历所有的键值。FormData.entries():返回一个遍历器对象,用于for...of循环遍历所有的键值对。如果直接用for...of循环遍历 FormData 实例,默认就会调用这个方法。
自动校验
表单提交的时候,浏览器允许开发者指定一些条件,它会自动验证各个表单控件的值是否符合条件。
1 | <!-- 必填 --> |
如果一个控件通过验证,它就会匹配:valid的 CSS 伪类,浏览器会继续进行表单提交的流程。如果没有通过验证,该控件就会匹配:invalid的 CSS 伪类,浏览器会终止表单提交,并显示一个错误信息。
File对象
https://wangdoc.com/javascript/bom/arraybuffer
https://wangdoc.com/javascript/bom/file
blob对象
https://developer.mozilla.org/zh-CN/docs/Web/API/Blob
https://zhuanlan.zhihu.com/p/97768916
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或二进制的格式进行读取
如你所见,myBlob 对象含有两个属性:size 和 type。其中 size 属性用于表示数据的大小(以字节为单位),type 是 MIME 类型的字符串。Blob 表示的不一定是 JavaScript 原生格式的数据。比如 File 接口基于 Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。
Blob 由一个可选的字符串 type(通常是 MIME 类型)和 blobParts 组成:
Blob 构造函数的语法为:
1 | var aBlob = new Blob(blobParts, options); |
blobParts数组:
arraybuffer
response 是一个包含二进制数据的 JavaScript ArrayBuffer。
ArrayBufferView
blob
response 是一个包含二进制数据的 Blob 对象 。
document
response 是一个 HTML Document 或 XML XMLDocument,这取决于接收到的数据的 MIME 类型。DOMStrings 会被编码为 UTF-8。
options:一个可选的对象,包含以下两个属性:
- type —— 默认值为
"",它代表了将会被放入到 blob 中的数组内容的 MIME 类型。 - endings —— 默认值为
"transparent",用于指定包含行结束符\n的字符串如何被写入。 它是以下两个值中的一个:"native",代表行结束符会被更改为适合宿主操作系统文件系统的换行符,或者"transparent",代表会保持 blob 中保存的结束符不变。
file对象
https://developer.mozilla.org/zh-CN/docs/Web/API/File
File 对象是来自用户在一个 元素上选择文件后返回的 FileList 对象,也可以是来自由拖放操作生成的 DataTransfer 对象
File 对象是特殊类型的 Blob,且可以用在任意的 Blob 类型的 context 中
剪切板
Clipboard.JS:Selection 与 execCommand API
运行
ClipboardJS.isSupported()来检查是否支持clipboard.js点击按钮两次才执行
图像写入剪切板
base64,file和Blob的转换
阮一峰:剪贴板操作 Clipboard API 教程
文字
1 | <input id="foo" type="text" value="大家好,我是阿宝哥"> |
除了 input 元素之外,复制的目标还可以是 div 或 textarea 元素。在以上示例中,我们复制的目标是通过 data-* 属性 来指定。此外,我们也可以在实例化 clipboard 对象时,设置复制的目标:
1 | // https://github.com/zenorocha/clipboard.js/blob/master/demo/function-target.html |
如果需要设置复制的文本,我们也可以在实例化 clipboard 对象时,设置复制的文本:
1 | // https://github.com/zenorocha/clipboard.js/blob/master/demo/function-text.html |
图像
1 | //将base64转换为blob对象 |
Chrome 浏览器规定,navigator.clipboard只有 HTTPS 协议的页面才能使用这个 API。不过,开发环境(localhost)允许使用非加密协议。
WEB存储
cookie对象
https://mp.weixin.qq.com/s/D7tWeUPsUfYsA97au5soNg
https://wangdoc.com/javascript/bom/cookie
https://zh.javascript.info/cookie#domain
Cookie 通常是由 Web 服务器使用响应
Set-CookieHTTP-header 设置的。然后浏览器使用CookieHTTP-header 将它们自动添加到(几乎)每个对相同域的请求中。

Cookie 是服务器保存在浏览器的一小段文本信息,一般来说,单个域名设置的 Cookie 不应超过30个,每个 Cookie 的大小不能超过 4KB。超过限制以后,Cookie 将被忽略,不会被设置。浏览器每次向服务器发出请求,就会自动附上这段信息。
用户可以设置浏览器不接受Cookie,也可以设置不向服务器发送 Cookie。window.navigator.cookieEnabled属性返回一个布尔值,表示浏览器是否打开 Cookie 功能。
1 | window.navigator.cookieEnabled // true |
document.cookie属性返回当前网页的 Cookie。
1 | document.cookie // "id=foo;key=bar" |
Cookie 的目的就是区分用户,以及放置状态信息,它的使用场景主要如下。
- 最常见的用处之一就是身份验证:
- 登录后,服务器在响应中使用
Set-CookieHTTP-header 来设置具有唯一“会话标识符(session identifier)”的 cookie。 - 下次当请求被发送到同一个域时,浏览器会使用
CookieHTTP-header 通过网络发送 cookie。 - 所以服务器知道是谁发起了请求。
- 登录后,服务器在响应中使用
- 对话(session)管理:保存登录状态、购物车等需要记录的信息。
- 个性化信息:保存用户的偏好,比如网页的字体大小、背景色等等。
- 追踪用户:记录和分析用户行为。
Cookie配置
Domain / Path
cookie 是要限制::「空间范围」::的,通过 Domain(域)/ Path(路径)
path=/,默认为当前路径,使 cookie 仅在该路径下可见。domain=site.com,默认 cookie 仅在当前域下可见。如果显式地设置了域,可以使 cookie 在子域下也可见。
Domain属性指定浏览器发出 HTTP 请求时,哪些域名要附带这个 Cookie。如果没有指定该属性,浏览器会默认将其设为当前 URL 的一级域名,比如 www.example.com 会设为 example.com,而且以后如果访问example.com的任何子域名,HTTP 请求也会带上这个 Cookie。如果服务器在Set-Cookie字段指定的域名,不属于当前域名,浏览器会拒绝这个 Cookie。
Path属性指定浏览器发出 HTTP 请求时,哪些路径要附带这个 Cookie。只要浏览器发现,Path属性是 HTTP 请求路径的开头一部分,就会在头信息里面带上这个 Cookie。比如,PATH属性是/,那么请求/docs路径也会包含该 Cookie。当然,前提是域名必须一致。
Expires / Max-Age
cookie 还可以限制::「时间范围」::,通过 Expires、Max-Age 中的一种。
expires 或 max-age 设定了 cookie 过期时间。如果没有设置,则当浏览器关闭时 cookie 就会失效。
Expires属性指定一个具体的到期时间,到了指定时间以后,浏览器就不再保留这个 Cookie。它的值是 UTC 格式。如果不设置该属性,或者设为null,Cookie 只在当前会话(session)有效,浏览器窗口一旦关闭,当前 Session 结束,该 Cookie 就会被删除。另外,浏览器根据本地时间,决定 Cookie 是否过期,由于本地时间是不精确的,所以没有办法保证 Cookie 一定会在服务器指定的时间过期。
Max-Age属性指定从现在开始 Cookie 存在的秒数,比如60 * 60 * 24 * 365(即一年)。过了这个时间以后,浏览器就不再保留这个 Cookie。
如果同时指定了Expires和Max-Age,那么Max-Age的值将优先生效。
如果Set-Cookie字段没有指定Expires或Max-Age属性,那么这个 Cookie 就是 Session Cookie,即它只在本次对话存在,一旦用户关闭浏览器,浏览器就不会再保留这个 Cookie。
—— Cookie — JavaScript 标准参考教程(alpha)
Secure / HttpOnly
cookie 可以限制::「使用方式」::。
secure使 cookie 仅在 HTTPS 下有效。默认情况下,如果我们在
http://site.com上设置了 cookie,那么该 cookie 也会出现在https://site.com上,反之亦然。也就是说,cookie 是基于域的,它们不区分协议。
Secure属性指定浏览器只有在加密协议 HTTPS 下,才能将这个 Cookie 发送到服务器。另一方面,如果当前协议是 HTTP,浏览器会自动忽略服务器发来的Secure属性。该属性只是一个开关,不需要指定值。如果通信是 HTTPS 协议,该开关自动打开。
HttpOnly属性指定该 Cookie 无法通过 JavaScript 脚本拿到,主要是Document.cookie属性、XMLHttpRequest对象和 Request API 都拿不到该属性。这样就防止了该 Cookie 被脚本读到,只有浏览器发出 HTTP 请求时,才会带上该 Cookie。
samesite
samesite,如果请求来自外部网站,禁止浏览器发送 cookie。这有助于防止 XSRF 攻击。

Strict
Strict最为严格,完全禁止第三方Cookie,跨站点时,任何情况下都不会发送Cookie。换言之,只有当前网页的URL与请求目标一致,才会带上Cookie。Set-Cookie: CookieName=CookieValue; SameSite=Strict;这个规则过于严格,可能造成非常不好的用户体验。比如,当前网页有一个GitHub链接,用户点击跳转就不会带有GitHub的Cookie,跳转过去总是未登陆状态。Lax
Lax规则稍稍放宽,大多数情况也是不发送第三方
Cookie,但是导航到目标网址的Get请求除外。Set-Cookie: CookieName=CookieValue; SameSite=Lax;设置了Strict或Lax以后,基本就杜绝了CSRF攻击。当然,前提是用户浏览器支持SameSite属性。None
网站可以选择显式关闭
SameSite属性,将其设为None。不过,前提是必须同时设置Secure属性(Cookie只能通过HTTPS协议发送),否则无效。Set-Cookie: widget_session=abc123; SameSite=None; Secure
域名
路径
- 用户访问网址
www.example.com,服务器在浏览器写入一个 Cookie。这个 Cookie 的所属域名为www.example.com,生效路径为根路径/。 - 如果 Cookie 的生效路径设为
/forums,那么这个 Cookie 只有在访问www.example.com/forums及其子路径时才有效。以后,浏览器访问某个路径之前,就会找出对该域名和路径有效,并且还没有到期的 Cookie,一起发送给服务器。
Cookie 是按照域名区分的,foo.com只能读取自己放置的 Cookie,无法读取其他网站(比如bar.com)放置的 Cookie。一般情况下,一级域名也不能读取二级域名留下的 Cookie,比如mydomain.com不能读取subdomain.mydomain.com设置的 Cookie。但是有一个例外,设置 Cookie 的时候(不管是一级域名设置的,还是二级域名设置的),明确将domain属性设为一级域名,则这个域名下面的各级域名可以共享这个 Cookie。
1 | Set-Cookie: name=value; domain=mydomain.com |
上面示例中,设置 Cookie 时,domain属性设为mydomain.com,那么各级的子域名和一级域名都可以读取这个 Cookie。
注意,区分 Cookie 时不考虑协议和端口。也就是说,http://example.com设置的 Cookie,可以被https://example.com或http://example.com:8080读取。
cookie读写
读写流程
- 在提供标记的接口,通过 HTTP 返回头的 Set-Cookie 字段,直接「种」到浏览器上
- 浏览器发起请求时,会自动把 cookie 通过 HTTP 请求头的 Cookie 字段,带给接口
1 | Set-Cookie: username=jimu; domain=jimu.com; path=/blog; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly |
HTTP 头对 cookie 的读写
HTTP 返回的一个 Set-Cookie 头用于向浏览器写入「一条(且只能是一条)」cookie,格式为 cookie 键值 + 配置键值。例如:
1 | Set-Cookie: username=jimu; domain=jimu.com; path=/blog; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly |
那我想一次多 set 几个 cookie 怎么办?多给几个 Set-Cookie 头(一次 HTTP 请求中允许重复)
1 | Set-Cookie: username=jimu; domain=jimu.com |
前端对 cookie 的读写
前端可以自己创建 cookie,如果服务端创建的 cookie 没加HttpOnly,那恭喜你也可以修改他给的 cookie。
调用document.cookie可以创建、修改 cookie,和 HTTP 一样,一次document.cookie能且只能操作一个 cookie。
1 | document.cookie = 'username=jimu; domain=jimu.com; path=/blog; Expires=Wed, 21 Oct |
调用document.cookie也可以读到 cookie,也和 HTTP 一样,能读到所有的非HttpOnlycookie。
1 | console.log(document.cookie); |
Location对象
localStorage - 用于长久保存整个网站的数据,保存的数据没有过期时间,直到手动去除。
1
2
3
4// 存储 localStorage.sitename = "菜鸟教程";
// 查找 document.getElementById("result").innerHTML =localStorage.sitename;
//移除 localStorage 中的 "sitename" :
localStorage.removeItem("sitename");sessionStorage - 用于临时保存同一窗口(或标签页)的数据,在关闭窗口或标签页之后将会删除这些数据。
1 | 不管是 localStorage,还是 sessionStorage,可使用的API都相同,常用的有如下几个(以localStorage为例): |
cookie和storage区别
生命周期:
Cookie:可设置失效时间,否则默认为关闭浏览器后失效
Localstorage:除非被手动清除,否则永久保存
Sessionstorage:仅在当前网页会话下有效,关闭页面或浏览器后就会被清除
存放数据:
Cookie:4k左右
Localstorage和sessionstorage:可以保存5M的信息
http请求:
cookie数据始终在同源的http请求中携带(即使不需要),会在浏览器和服务器间来回传递
其他两个:仅在客户端即浏览器中保存,不参与和服务器的通信
易用性:
Cookie:需要程序员自己封装,原生的cookie接口不友好
其他两个:即可采用原生接口,亦可再次封装
应用场景
每次http请求都会携带cookie信息,这样子浪费了带宽,所以cookie应该尽可能的少用(识别用户登陆来说,cookie还是比storage好用),此外cookie还需要指定作用域,不可以跨域调用
Cookie 不是一种理想的客户端存储机制。它的容量很小(4KB),缺乏数据操作接口,而且会影响性能。客户端存储建议使用 Web storage API 和 IndexedDB。只有那些每次请求都需要让服务器知道的信息,才应该放在 Cookie 里面。
Tips
设置属性(setAttribute),属性名为’data-‘开头的,可以使用dataset来获取值
1 | setAttribute('data-age', value); dataset['age'] |
兼容性
webpak 引入autoprefixer,自动加上各种前缀让不同的浏览器得以支持
冒泡和捕获
1 | function pauseEvent(e) { |
取消默认事件
1 | function pauseEvent(e) { |
event事件对象
1 | var ev = ev || window.event |
设备像素比
1 | //获取设备像素比 |
将浏览器的前进按钮禁止
1 | // 将浏览器的前进按钮禁止 |
回到顶部
1 | //图标固定 |
获取url的参数
1 | function getQueryVariable(variable){ |
数组转换为JSON数据
方法一:使用Object.assign()
Object.assign()方法将枚举的所有属性的值从源对象(一个或多个)复制到目标对象
语法:
1 | Object.assign(target, ...sources) |
数组循环中删除元素
1 | (function () { |
产生这个结果的原因是因为,当删除掉了一个元素后,数组中元素的索引(下标)发生了实时变化,造成了程序的异常。
方案
循环中索引添加递加判断,只有在不删除元素时才对索引递加
1
2
3
4
5
6
7for(var i=0; i<arr.length;) {
if(arr[i].gender === 2) {
arr.splice(i,1);
}else{
i++;
}
}倒序删除
1
2
3
4
5
6
7
8
9
10
11(function () {
var arr = [1, 2, 2, 3, 4, 5];
var i = arr.length;
while(i--) {
console.log(i + ' = ' + arr[i]);
if(arr[i] === 2) {
arr.splice(i, 1);
}
}
console.log(arr);
})();
Web Notification桌面通知
https://daotin.netlify.app/gc12ta.html#%E6%9C%80%E5%90%8E
开始
要创建一个消息通知,非常简单,直接使用 window 对象下面的Notification类即可,代码如下:
1 | var n = new Notification("桌面推送", { |
于是你就会看到系统桌面弹出我上面那张截图的通知。
PS:消息通知只有通过
Web服务访问该页面时才会生效,如果直接双击打开本地文件,是没有任何效果的。也就是说你的文件需要使用服务器的形式打开,而不是直接使用浏览器打开本地文件。
当然也有可能你什么都没看到,别着急继续往下看。
基本语法
当然在想要弹出上面通知之前,有必要了解一下一个通知的基本语法:
1 | let myNotification = new Notification(title, options); |
title:定义一个通知的标题,当它被触发时,它将显示在通知窗口的顶部。
options(可选)对象包含应用于通知的任何自定义设置选项。
常用的选项有:
- body: 通知的正文,将显示在标题下方。
- tag: 类似每个通知的ID,以便在必要的时候对通知进行刷新、替换或移除。
- icon: 显示通知的图标
- image: 在通知正文中显示的图像的URL。
- data: 您想要与通知相关联的任意数据。这可以是任何数据类型。
- renotify: 一个 Boolean 指定在新通知替换旧通知后是否应通知用户。默认值为false,这意味着它们不会被通知。
- requireInteraction: 表示通知应保持有效,直到用户点击或关闭它,而不是自动关闭。默认值为false。
当这段代码执行时,浏览器会询问用户,是否允许该站点显示消息通知,如下图所示:
只有用户点击了允许,授权了通知,通知才会被显示出来。
授权
如何获取到用户点击的是“允许”还是“阻止”呢?
window的 Notification实例有一个 requestPermission 函数用来获取用户的授权状态:
1 | // 首先,我们检查是否具有权限显示通知 |
注意:如果用户点击了授权右上角的关闭按钮,则status的值为default。
之后,我们只需要判断 status 的值是否为granted,来决定是否显示通知。
通知事件
但是单纯的显示一个消息框是没有任何吸引力的,所以消息通知应该具有一定的交互性,在显示消息的前前后后都应该有事件的参与。
Notification一开始就制定好了一系列事件函数,开发者可以很方面的使用这些函数处理用户交互:
有:onshow,onclick,onerror,onclose。
1 | var n = new Notification("桌面推送", { |
一个简单的例子
1 | <meta charset="UTF-8"> |
当我们打开界面的时候,就会弹出授权申请,如果我们点击允许,然后点击按钮,就可以发送一条通知到桌面,我们就可以在桌面右下角看到这条通知。

上面我们只是显示一条消息。
1 | if (status === "granted") { |
如果我们有很多消息的话,比如我是用个for循环来模拟大量通知的情况。
1 | for(var i=0; i<10; i++) { |
可以看到有10条通知都显示出来。但是某些情况下对于用户来说,显示大量通知是件令人痛苦的事情。
比如,如果一个即时通信应用向用户提示每一条传入的消息。为了避免数以百计的不必要通知铺满用户的桌面,可能需要接管一个挂起消息的队列。
因此,需要为新建的通知添加一个标记。
如果有一条新通知和上一条通知具有相同的标记,那么这条新通知将会替换上一条通知,最后桌面上只会显示最新的通知。
还是上面的例子,只需要在触发通知加个tag属性即可:
1 | for (var i = 0; i < 10; i++) { |
最后
消息通知是个不错的特性,可是也不排除有些站点恶意的使用这个功能,一旦用户授权之后,不时的推送一些不太友好的消息,打扰用户的工作,这个时候我们可以移除该站点的权限,禁用其消息通知功能。
我们可以点击浏览器地址输入框左边的叹号就有一个通知的选项,我们可以修改授权。或者在通知页面也有修改通知的选项,可以根据具体情况进行修改授权通知。

于是最基本的 Web Notification 就实现了。
jquery
核心
$([selector,[context]])
$()将在当前的 HTML document中查找 DOM 元素;如果指定了 context 参数,如一个 DOM 元素集或 jQuery 对象,那就会在这个 context 中查找。
jQuery 代码:
1
2$("input:radio", document.forms[0]);
//在文档的第一个表单中,查找所有的单选按钮(即: type 值为 radio 的 input 元素)。```js
//DOM文档载入完成后执行的函数
$(function(){
// 文档就绪
});1
2
3
4
5
6
7
8
9
10
11
- ## this
```js
当你用的是jquery时,就用$(this),如果是JS,就用this
jquery对象$(this)[0]等同于JS里的元素this
console.log($(this)[0]==this) //true
JS里的元素只要包上$()就是jquery对象了,而jquery的对象只要加上[0]或者.get(0),就是js元素了
$(this).get(0)与$(this)[0]等价。
console.log($(this)[0]==$(this).get(0)) //trueeach(callback),每次执行传递进来的函数时,函数中的this关键字都指向一个不同的DOM元素
1 | $("img").each(function(i){ |
size()/length当前匹配的元素个数
get(index)取得其中一个匹配的元素
HTML 代码:
1
<img src="test1.jpg"/> <img src="test2.jpg"/>
jQuery 代码:
1
$("img").get(0);
index(一个DOM选择器/ jQuery 选择器)
搜索匹配的元素,并返回相应元素的索引值,从0开始计数。
1 | <ul> |
属性
attr(name|key,value)返回或设置被选元素的属性值。removeAttr
1
2$("img").attr({ src: "test.jpg", alt: "Test Image" });//为所有图像设置src和alt属性。
$("img").attr("src","test.jpg");//为所有图像设置src属性。removeAttr(name)从每一个匹配的元素中删除一个属性
1
2$("img").removeAttr("src");
//将文档中图像的src属性删除addClass(class|fn)为每个匹配的元素添加指定的类名。removeClass
1
2
3$('ul li:last').addClass(function(index,class) {
return 'item-' + $(this).index();
});//给li加上不同的classtoggleClass(class|fn)如果存在(不存在)就删除(添加)一个类。
1
2
3
4var count = 0;
$("p").click(function(){
$(this).toggleClass("highlight", count++ % 3 == 0);
});//每点击三下加上一次 'highlight' 类html()
1
2
3
4//返回p元素的内容。取得第一个匹配元素的html内容。
$('p').html();
//设置所有 p 元素的内容
$("p").html("Hello <b>world</b>!");text()
1
2
3
4//返回p元素的文本内容。
$('p').text();
//设置所有 p 元素的文本内容
$("p").text("Hello world!");val()
css
css
1
2
3
4
5
6//取得第一个段落的color样式属性的值。
$("p").css("color");
//将所有段落的字体颜色设为红色并且背景为蓝色。
$("p").css({ "color": "#ff0011", "background": "blue" });
//将所有段落字体设为红色
$("p").css("color","red");height()
1
2
3
4
5
6
7
8
9
10
11//获取第一段的高
$("p").height();
//把所有段落的高设为 20:
$("p").height(20);
//以 10 像素的幅度增加 p 元素的高度
$("button").click(function(){
$("p").height(function(n,c){
//n,c索引位置和元素旧的高度值
return c+10;
});
});
选择器
层级
prev + next匹配所有紧接在 prev 元素后的 next 元素
1
2
3
4
5
6
7
8
9
10
11
12
13//匹配所有跟在 label 后面的 input 元素
<form>
<label>Name:</label>
<input name="name" />
<fieldset>
<label>Newsletter:</label>
<input name="newsletter" />
</fieldset>
</form>
<input name="none" />
$("label + input")
[ <input name="name" />, <input name="newsletter" /> ]prev ~ siblings匹配 prev 元素之后的所有 siblings 元素
1
2
3
4
5
6
7
8
9
10
11
12<form>
<label>Name:</label>
<input name="name" />
<fieldset>
<label>Newsletter:</label>
<input name="newsletter" />
</fieldset>
</form>
<input name="none" />
$("form ~ input")
[ <input name="none" /> ]
基本
:first获取第一个元素–>last
1
$('li:first');
:not去除所有与给定选择器匹配的元素
1
2
3
4//查找所有未选中的 input 元素
<input name="apple" />
<input name="flower" checked="checked" />
$("input:not(:checked)"):even()匹配所有索引值为偶数的元素,从 0 开始计数–>:odd()
:eq()匹配一个给定索引值的元素,从 0 开始计数
:gt()匹配所有大于给定索引值的元素,从 0 开始计数–>:It()
可见性
属性
子元素
表单
文档处理
内部插入
append()向每个匹配的元素内部追加内容。
appendTo()把所有匹配的元素追加到另一个指定的元素元素集合中。
1
2
3
4
5<p>I would like to say: </p>
<div></div><div></div>
$("p").appendTo("div");
<div><p>I would like to say: </p></div>
<div><p>I would like to say: </p></div>prepend()向每个匹配的元素内部前置内容。–>prependTo()
外部插入
- after()在每个匹配的元素之后插入内容。–>before
- insertAfter–>insertBefore
替换
- replaceWith(content|fn)将所有匹配的元素替换成指定的HTML或DOM元素。
删除
- empty()删除匹配的元素集合中所有的子节点。
- remove()从DOM中删除所有匹配的元素。
筛选
is(expr|obj|ele|fn)根据选择器、DOM元素或 jQuery 对象来检测匹配元素集合,如果其中至少有一个元素符合这个给定的表达式就返回true。
map(fn)将一组元素转换成其他数组(不论是否是元素数组)用这个函数来建立一个列表,不论是值、属性还是CSS样式,
1 | $("p").append( $("input").map(function(){ |
children(expr),取得一个包含匹配的元素集合中每一个元素的所有子元素的元素集合。expr用以过滤子元素的表达式
find(expr|obj|ele),搜索所有与指定表达式匹配的元素。这个函数是找出正在处理的元素的后代元素的好方法。与$(“p span”)相同。
next(expr),取得一个包含匹配的元素集合中每一个元素紧邻的后面同辈元素的元素集合。
nextAll(expr),查找当前元素之后所有的同辈元素。
prev(expr)取得一个包含匹配的元素集合中每一个元素紧邻的前一个同辈元素的元素集合。
siblings(expr)取得一个包含匹配的元素集合中每一个元素的所有唯一同辈元素的元素集合。可以用可选的表达式进行筛选。
事件
1 | 1.one(type,[data],fn) 为每一个匹配元素的特定事件(像click)绑定一个一次性的事件处理函数。在每个对象上,这个事件处理函数只会被执行一次。 其他规则与bind()函数相同(bind()的事件函数只能针对已经存在的元素进行事件的设置)。 |
trigger(type,[data])在每一个匹配的元素上触发某类事件。
hover([over,]out)
over:鼠标移到元素上要触发的函数
out:鼠标移出元素要触发的函数
toggle([speed],[easing],[fn])用于绑定两个或多个事件处理器函数,以响应被选元素的轮流的 click 事件。如果元素是可见的,切换为隐藏的;如果元素是隐藏的,切换为可见的。
1 | $("td").toggle( |
change([data],fn)当元素的值发生改变时,会发生 change 事件。
unload([[data],fn])在当用户离开页面时,会发生 unload 事件。
会发出 unload 事件:
- 点击某个离开页面的链接
- 在地址栏中键入了新的 URL
- 使用前进或后退按钮
- 关闭浏览器
- 重新加载页面
正则表达式
正则表达式的组成
边界
| ^ | 表示匹配行首的文本(以谁开始) |
|---|---|
| $ | 表示匹配行尾的文本(以谁结束) |
| \b | 当前位置的左右两侧,只能有一侧是字母数字或下划线 |
元字符
| 元字符 | 说明 |
|---|---|
| \d | 匹配数字 |
| \D | 匹配任意非数字的字符 |
| \w | 匹配字母或数字或下划线 |
| \W | 匹配任意不是字母,数字,下划线 |
| \s | 匹配任意的空白符(包括空格、制表符、换页符) |
| \S | 匹配任意不是空白符的字符 |
| . | 匹配除换行符以外的任意单个字符 |
限定符
| 限定符 | 说明 | |
|---|---|---|
| * | 表达式尽可能的多匹配,最少可以不匹配,相当于 {0, } | |
| + | 表达式尽可能的多匹配,至少匹配1次,相当于 {1, } | “zo+”与“zo”和“zoo”匹配,但与“z”不匹配。+ 等效于 {1,} |
| ? | 表达式尽可能匹配1次,也可以不匹配,相当于 {0, 1} | “do(es)?”匹配“do”或“does”中的“do”。? 等效于 {0,1}。 |
| {n} | 表达式固定重复n次 | “o{2}”与“Bob”中的“o”不匹配,但与“food”中的两个“o”匹配。 |
| {n,} | 表达式尽可能的多匹配,至少重复n次 | “o{2,}”不匹配“Bob”中的“o”,而匹配“foooood”中的所有 o。“o{1,}”等效于“o+”。“o{0,}”等效于“o*” |
| {n,m} | 表达式尽可能重复m次,至少重复n次 | “o{1,3}”匹配“fooooood”中的头三个 o。’o{0,1}’ 等效于 ‘o?’。注意:您不能将空格插入逗号和数字之间。 |
| {n, m}? | 表达式尽量只匹配n次,最多重复m次。 | |
| {m, n}+ | 表达式尽可能重复n次,至少重复m次。 |
贪婪模式:在限定符之后的表达式能够匹配成功的情况下,不定次数的限定符总是尽可能的多匹配。如果之后的表达式匹配失败,限定符可适当“让出”能够匹配的字符,以使整个表达式匹配成功。这种模式就叫“贪婪模式”。
- 限定符之后添加加号(+),总是尽可能多的匹配
非贪婪匹配模式:正则表达式去匹配时,会尽量少的匹配符合条件的内容 也就是说,一旦发现匹配符合要求,立马就匹配成功,而不会继续匹配下去(除非有
g,开启下一组匹配)- 限定符之后添加问号(?),总是尽可能少的匹配
前瞻/先行断言
1 | // 前瞻/先行断言: |
转义符
| 表达式 | 可匹配 |
|---|---|
| \r, \n | 代表回车和换行符 |
| \t | 制表符 |
| \ | 代表 “” 本身 |
其它
有特殊用处的标点符号,在前面加 “\” 后,就代表该符号本身
| 表达式 | 可匹配 |
|---|---|
| ^ | 匹配 ^ 符号本身 |
| \ $ | 匹配 $ 符号本身 |
| \ . | 匹配小数点(.)本身 |
方括号 [ ] 包含一系列字符,能够匹配其中任意一个字符。**[^] 匹配除中括号以内的内容**
表达式 可匹配 [ab5@] 匹配 “a” 或 “b” 或 “5” 或 “@” [^abc] 匹配 “a”,”b”,”c” 之外的任意一个字符 [f-k] 匹配 “f”~”k” 之间的任意一个字母 [^A-F0-3] 匹配 “A” “F”,”0”“3” 之外的任意一个字符| 选择左右两边的一个。注意|将左右两边分为两部分,而不管左右两边有多长多乱。
eg:gr(a|e)y匹配gray和grey
() 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用
\(和\)。
JavaScript 中使用正则表达式
正则表达式 new RegExp() 和 / /的区别
首先就是举例:
区别1: 用 / /来书写正则表达式,并不会将/d 中的/ 当做转义字符,而用 new RegExp()书写的正则表达式则会将/d 中的/ 当做转义字符;
var reg = /^ \d{6}$/
console.log(reg); // /^\d{6}$/
var regs = new RegExp(“^\d{6}$”);
console.log(regs);// /^d{6}$/
区别2:new RegExp(“/“) 会自动的将/ 进行转义
1 | var regs = new RegExp("/"); |
问题解析:js 会自动的默认 \ 是一个转义字符,然后会到转义字符表中查找;如果没有会默认的将 \ 进行删除
问题解决:使用模板字符串的String.raw来解决
var regs = new RegExp(String.raw
^\d{6}$); :第一步要将正则表达式的语句放到模板字符串中,然后才能使用String.raw
创建正则对象
方式1:
1 | var reg = new RegExp('\d', 'i'); |
方式2:
1 | var reg = /\d/i; |
参数
| 标志 | 说明 |
|---|---|
| i | 忽略大小写 |
| g | 全局匹配 |
| gi | 全局匹配+忽略大小写 |
正则匹配
1 | // 匹配日期 |
正则提取
1 | // 1. 提取工资 |
正则替换
1 | // 1. 替换所有空白 |
案例
1 | 整数或者小数:^[0-9]+.{0,1}[0-9]{0,2}$ |
正则表达式 获取括号内的内容
https://blog.csdn.net/genius_yym/article/details/79670035
JS 正则表达式 获取小括号 中括号 花括号内的内容
1 | var str="123{xxxx}456[我的]789123[你的]456(1389090)789"; |
限制el-input只能输入两位小数
1 | this.ruleForm[name] = ('' + value) // 第一步:转成字符串 |
利用正则表达式获取括号里面的内容 或者 包括括号与内容
1 | //1.获取括号的内容,包换括号 |
