
前端原理和源码
webpack
webpack执⾏流程
简略流程

图示流程理解分析:
读取⼊⼝⽂件;
基于 AST(抽象语法树) 分析⼊⼝⽂件,并产出依赖列表;
AST (Abstract Syntax Tree)抽象语法树 在计算机科学中,或简称语法树(Syntax tree),是源代码语法结构的⼀种抽象表示。它以树状的形式表现编程语⾔的语法结构,树上的每个节点都表示源代码中的⼀种结构。
使⽤ Babel 将相关模块编译到 ES5;
webpack有⼀个智能解析器(各种babel),⼏乎可以处理任何第三⽅库。⽆论它们的模块形式是CommonJS、AMD还是普通的JS⽂件;甚⾄在加载依赖的时候,允许使⽤动态表require(“、/templates/“+name+”、jade”)。以下这些⼯具底层依赖了不同的解析器⽣成AST,⽐如eslint使⽤了espree、babel使⽤了acorn
对每个依赖模块产出⼀个唯⼀的 ID,⽅便后续读取模块相关内容;
将每个依赖以及经过 Babel 编译过后的内容,存储在⼀个对象中进⾏维护;
遍历上⼀步中的对象,构建出⼀个依赖图(Dependency Graph);
将各模块内容 bundle 产出
详细流程
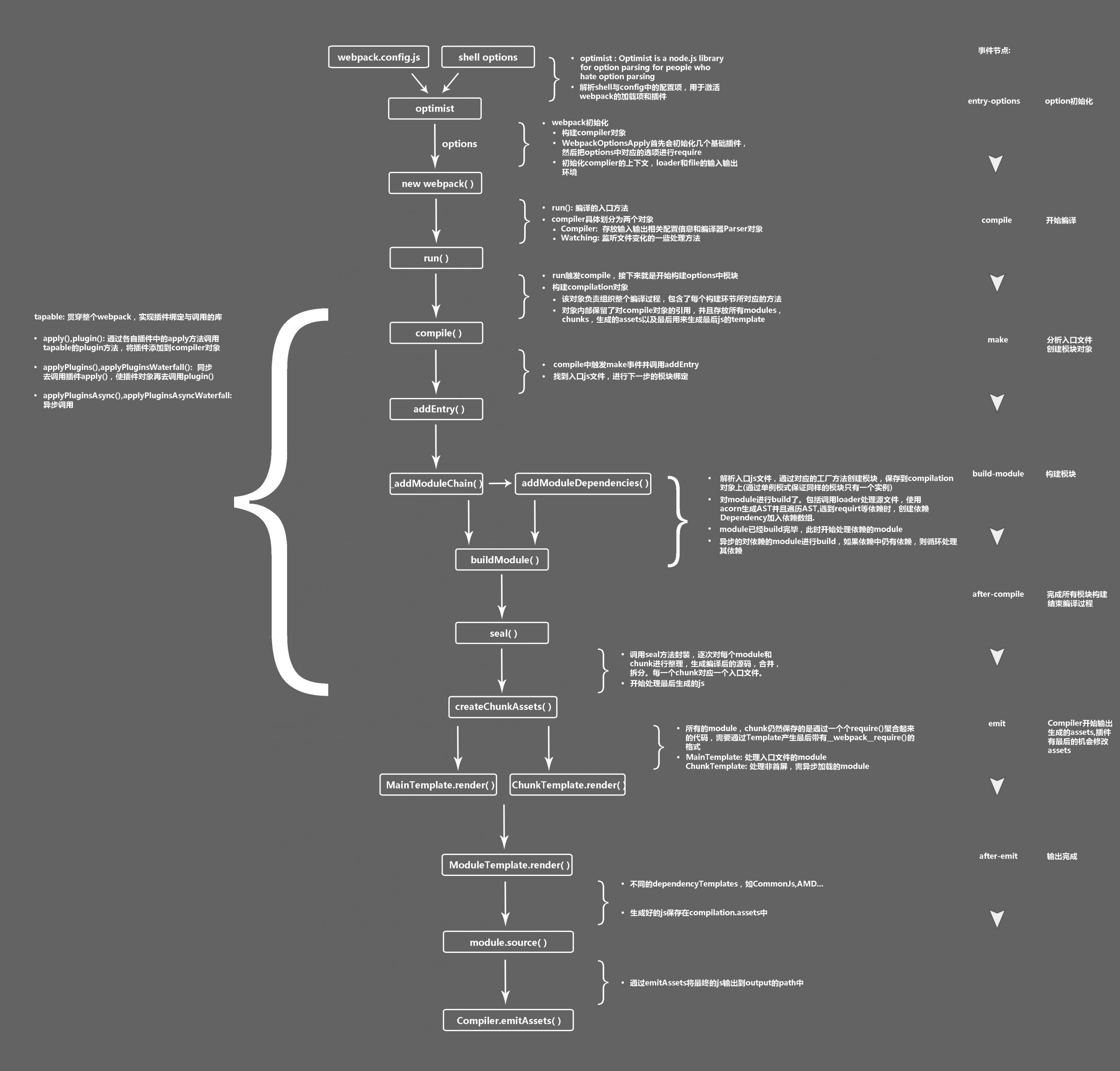
流程:
- 通过命令行和
webpack.config.js来获取参数 - 创建
compiler对象,初始化plugins - 开始编译阶段,
addEntry添加入口资源 addModule创建模块runLoaders执行loader- 依赖收集,js 通过
acorn解析为AST,然后查找依赖,并重复 4 步 - 构建完依赖树后,进入生成阶段,调用
compilation.seal - 经过一系列的
optimize优化依赖,生成chunks,写入文件
打包原理
⼿写webpack原理 https://juejin.cn/post/6854573217336541192
webpack打包原理 https://blog.csdn.net/weixin_41319237/article/details/116194091
主要流程
- 需要读到入口文件里面的内容
- 分析入口文件,递归的去读取模块所依赖的文件内容,生成AST语法树。
- 根据AST语法树,生成浏览器能够运行的代码
具体细节
- 获取主模块内容
- 分析模块
- 安装@babel/parser包(生成AST)
- 对模块内容进行处理
- 安装@babel/traverse包(遍历AST收集依赖)
- 安装@babel/core和@babel/preset-env包 (es6转ES5)
- 递归所有模块
- 执行require和exports。生成最终代码
基本准备工作
先建一个项目
我们创建了add.js文件和minus.js文件,然后 在index.js中引入,再将index.js文件引入index.html。
代码如下:
add.js
1 | export default (a,b)=>{ |
minus.js
1 | export const minus = (a,b)=>{ |
index.js
1 | import add from "./add.js" |
index.html
1 |
|
现在我们打开index.html。你猜会发生什么???显然会报错,因为浏览器还不能识别import等ES6语法
获取主模块内容
bundle.js文件
1 | // 获取主入口文件 |
执行一下bundle.js:node bundle.js
分析模块babel/parser
分析模块的主要任务是 将获取到的主模块内容 解析成AST语法树,这个需要用到一个依赖包@babel/parser
1 | npm install @babel/parser |
ok,安装完成我们将@babel/parser引入bundle.js,
1 | // 获取主入口文件 |
收集依赖babel/traverse
现在我们需要 遍历AST,将用到的依赖收集起来。什么意思呢?其实就是将用import语句引入的文件路径收集起来。我们将收集起来的路径放到deps里。
前面我们提到过,遍历AST要用到@babel/traverse依赖包
1 | npm install @babel/traverse |
现在,我们引入。
1 | const fs = require('fs') |
ES6的AST转化成ES5
1 | npm install @babel/core @babel/preset-env |
我们现在将依赖引入并使用
1 | const fs = require('fs') |
递归获取所有依赖
经过上面的过程,现在我们知道getModuleInfo是用来获取一个模块的内容,不过我们还没把获取的内容return出来,因此,更改下getModuleInfo方法
1 | const getModuleInfo = (file)=>{ |
我们返回了一个对象 ,这个对象包括主模块的路径(file),主模块的依赖(deps),主模块转化成es5的代码
该方法只能获取一个模块的的信息,但是我们要怎么获取一个模块里面的依赖模块的信息呢?递归。
1 | //递归获取依赖 |
讲解下parseModules方法:
- 我们首先传入主模块路径
- 将获得的模块信息放到temp数组里。
- 外面的循坏遍历temp数组,此时的temp数组只有主模块
- 循环里面再获得主模块的依赖deps
- 遍历deps,通过调用getModuleInfo将获得的依赖模块信息push到temp数组里。
按照目前我们的项目来说执行完,应当是temp 应当是存放了index.js,add.js,minus.js三个模块。 ,执行看看。
不过现在的temp数组里的对象格式不利于后面的操作,我们希望是以文件的路径为key,{code,deps}为值的形式存储。因此,我们创建一个新的对象depsGraph。
1 | const parseModules = (file) =>{ |
导入导出
我们现在的目的就是要生成一个bundle.js文件,也就是打包后的一个文件。其实思路很简单,就是把index.js的内容和它的依赖模块整合起来。然后把代码写到一个新建的js文件。
1 | // index.js |
1 | // add.js |
但是我们现在是不能执行index.js这段代码的,因为浏览器不会识别执行require和exports。
不能识别是为什么?因为没有定义这require函数,和exports对象。那我们可以自己定义。
1 | const bundle = (file) => { |
把保存下来的depsGraph,传入一个立即执行函数。
将主模块路径传入require函数执行
reuire函数中立即执行函数
require:absRequire,因为code代码中require路径不是绝对路径,需要转化成绝对路径,因此写一个函数absRequire来转化
exports:exports
增添了一个空对象 exports,执行add.js代码的时候,会往这个空对象上增加一些属性
1
2
3
4
5
6
7
8
9
10
11// add.js
;
Object.defineProperty(exports, "__esModule", { value: true});
exports["default"] = void 0;
var _default = function _default(a, b) { return a + b;};
exports["default"] = _default;
//执行完这段代码后
exports = {
__esModule:{ value: true},
default:function _default(a, b) { return a + b;}
}然后我们把exports对象return出去。
1
var _add = _interopRequireDefault(require("./add.js"));
return出去的值,被_interopRequireDefault接收,_interopRequireDefault再返回default这个属性给_add,因此
_add = function _default(a, b) { return a + b;}
code:graph[file].code
- 执行eval(code),也就是执行模块的code这段代码
- 执行eval(code)过程会执行到require函数,这时会调用这个require,也就是我们传入的absRequire,而执行absRequire就执行了
return require(graph[file].deps[relPath])这段代码,也就是执行了外面这个require。而执行require(”./src/add.js”)之后,又会执行eval,也就是执行add.js文件的代码。
- 执行eval(code)过程会执行到require函数,这时会调用这个require,也就是我们传入的absRequire,而执行absRequire就执行了
- 执行eval(code),也就是执行模块的code这段代码
单应用框架
软件架构模式
https://www.pianshen.com/article/3716256399/
MVC,MVP和MVVM都是常见的软件架构设计模式(Architectural Pattern),它通过分离关注点来改进代码的组织方式。它们目标都是解耦,解耦好处一个是关注点分离,提升代码可维护和可读性,并且提升代码复用性。
MVC
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的软件设计规范。
Model(模型) :数据层。将js的ajax当做Model,也就是数据层,通过ajax从服务器获取数据。
View(视图) :视图层。
Controller(控制器):交互层。用户对View的操作交给了Controller处理,在Controller中响应View的事件调用Model的接口对数据进行操作,一旦Model发生变化便通知相关视图进行更新

1.View传送指令到Controller。
2.Controller完成业务逻辑后改变Model状态。
3.Model将新的数据发送至View,用户得到反馈。
缺点
1.m层和v层直接打交道,导致这两层耦合度高
2.因为所有逻辑都写在c层,导致c层特别臃肿
控制div是否显示:
1 | <body> |
用数据驱动模型模型来写:
1 | <body> |
看起来好像多了几行代码,但是对于第二种代码来说,简单抽象封装了 render 函数,我们只需要修改 is_shown 的 bool 值,而无需在意 render 函数内部的执行,就可以实现通过数据修改来驱动视图的更新。
MVVM
mvc中Controller演变成mvvm中的viewModel。 mvvm主要解决了mvc中大量DOM操作使页面首次渲染性能降低,加载速度变慢的问题 。
Model-View-ViewModel即模型-视图-视图模型。
模型:数据层。后端传递的数据。
视图:视图层。
视图模型:mvvm模式的核心,它是连接view和model的桥梁。
总结:在MVVM的框架下视图和模型是不能直接通信的。它们通过ViewModel来通信,ViewModel通常要实现一个observer观察者,当数据发生变化,ViewModel能够监听到数据的这种变化,然后通知到对应的视图做自动更新,而当用户操作视图,ViewModel也能监听到视图的变化,然后通知数据做改动,这实际上就实现了数据的双向绑定。
区别
dom操作方式
- MVC来讲,MVC操作的是真实dom,对于数据的更新需要找到对应抽象类来直接操作真实dom
- 对于MVVM来讲,它操作的是虚拟dom、在数据的更新后,该框架重新生成一个虚拟dom树,与旧虚拟dom树进行比对,然后替换修改的地方,所以可以将渲染视图抽象成一个函数类
视图更新
- MVVM完全不需要考虑视图更新对dom树的操作,框架会自动响应绑定对视图的更新
性能
- 页面首次渲染,MVVM框架可能会比MVC框架快一些,因为MVVM只会进行一次对真实dom的操作,而MVC可能会进行多次真实dom的操作
- 在首屏渲染完毕后,用户开始对页面进行直接操作时,MVVM的性能肯定会输MVC的
- 对于MVC构建的页面来说,用户修改数据,该框架会根据绑定的dom元素直接进行修改
- 而对于MVVM构建的页面来说,用户修改数据,该框架会重新生成虚拟dom树与原树进行比对,再修改
- 虽然可以进行diff(新旧虚拟dom树比对算法)优化,但是一个是直接操作,一个需要最少O(n)算法比对在进行真实dom操作
框架
- 常见的MVC框架有:Angular.js
框架对比
https://juejin.cn/post/6844903974437388295
https://zhuanlan.zhihu.com/p/100228073
渐进式
我们可以通过添加组件系统(components)、客户端路由(vue-router)、大规模状态管理(vuex)来构建一个完整的框架,这都是可选的
开发团队
- React是由FaceBook前端官方团队进行维护和更新的;因此,React的维护开发团队,技术实力比较雄厚;
- Vue:第一版,主要是有作者 尤雨溪 专门进行维护的,当 Vue更新到 2.x 版本后,也有了一个小团队进行相关的维护和开发;
编写语法
vue
vue推荐的做法是webpack+vue-loader的单文件组件格式,vue保留了html、css、js分离的写法,使得现有的前端开发者在开发的时候能保持原有的习惯,更接近常用的web开发方式,模板就是普通的html,数据绑定使用mustache风格,样式直接使用css。其中
