
ES6,TS和设计模式
ES6
let和const
let和const。其中,let完全可以取代var,因为两者语义相同,而且let没有副作用。在let和const之间,建议优先使用const,尤其是在全局环境,不应该设置变量,只应设置常量。同时JavaScript 编译器会对const进行优化,所以多使用const,有利于提高程序的运行效率
作用域
作用域定义了变量的可见性或可访问性。大白话来说,就是一个变量能不能被访问或引用,是由它的作用域决定的。
全局作用域(Global Scope)
在代码中任何地方都能访问到的对象拥有全局作用域,一般来说以下几种情形拥有全局作用域:
(1)最外层函数和在最外层函数外面定义的变量拥有全局作用域
(2)所有末定义直接赋值的变量自动声明为拥有全局作用域
(3)所有window对象的属性拥有全局作用域
局部作用域(Local Scope)
函数作⽤域:函数体中的局部变量只在函数执行时生成,函数执行完毕时局部变量即刻销毁
块级作⽤域:ES6引⼊了 let 和 const 关键字,和 var 关键字不同,在⼤括号中使⽤ let 和 const 声明的变量存 在于块级作⽤域中。在⼤括号之外不能访问这些变量
作用域链
当一个变量在当前作用域无法找到时,便会尝试寻找其外层的作用域,如果还找不到,再继续往上寻找
好处
防止命名冲突:你写了一万行的代码文件,如果没有作用域,你要给每个变量取独一无二的名字,屁股想想也知道是种折磨。安全性: 变量不会被外部访问,保证了变量值不会被随意修改。你定义在函数内的变量,如果能在几千行之后不小心被修改,脚趾头想想也知道是种折磨。更高级的语法:封装、面向对象等的实现离不开对变量的隔离,这是依靠作用域所达到的。
var变量和函数提升
词法分析阶段/预解析:在JS代码执行之前,浏览器的解析器在遇到 var 变量名 和function 整个函数 提升到当前作用域的最前面。
变量提升只会提升变量名的声明,而不会提升变量的赋值初始化。
1
2
3console.log(foo); // undefined
var foo = '小花猫';
console.log(foo) // 小花猫函数声明会提升而函数,表达式不会提升
1
2
3
4
5
6
7
8
9console.log(test1()) // 'this is test1'
function test1(){
return 'this is test1';
}
console.log(test2) // undefined
var test2 = function(){
return 'this is test2'
}函数提升的优先级大于变量提升的优先级
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15let foo = 3;
function hoistVariable() {
var foo = foo || 5;
console.log(foo); // 5
}
hoistVariable();
//预编译后
var foo;
function hoistVariable() {
foo = foo || 5; // 此时 等号右侧 foo 为 undefined
console.log(foo); // 5
}
foo = 3
hoistVariable();
不存在变量提升
暂时性死区: 区级作用域中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
1 | function bar(x = y, y = 2) { |
暂时性死区
只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
1 | var tmp = 123; |
上面代码中,存在全局变量tmp,但是块级作用域内let又声明了一个局部变量tmp,导致后者绑定这个块级作用域,所以在let声明变量前,对tmp赋值会报错。
ES6 明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
不允许重复声明
1 | // 报错。let不允许在相同作用域内,重复声明同一个变量 |
块级作用域与函数
为什么需要块级作用域
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var tmp = new Date();
function f() {
console.log(tmp);
if (false) {
var tmp = "hello world";
}
}
f(); // undefined
//2.用来计数的循环变量泄露为全局变量。
var s = 'hello';
for (var i = 0; i < s.length; i++) {
console.log(s[i]);
}
console.log(i); // 5
let实际上为 JavaScript 新增了块级作用域。
1 | function f1() { |
上面的函数有两个代码块,都声明了变量n,运行后输出 5。这表示外层代码块不受内层代码块的影响,即块级作用域也属于作用域链中。如果两次都使用var定义变量n,最后输出的值才是 10。
const命令
const声明一个只读的常量。一旦声明,常量的值就不能改变。
只在声明所在的块级作用域内有效
对于复合类型的变量,变量名不指向数据,而是指向数据所在的地址。const命令只是保证变量名指向的地址不变,并不保证该地址的数据不变
顶层对象的属性
顶层对象,在浏览器环境指的是window对象,在Node指的是global对象。
ES5之中,顶层对象的属性与全局变量是等价的。 这样的设计带来了几个很大的问题,首先是没法在编译时就报出变量未声明的错误,只有运行时才能知道 。 其次,程序员很容易不知不觉地就创建了全局变量 。 顶层对象的属性是到处可以读写的,这非常不利于模块化编程。
ES6为了改变这一点,一方面规定,为了保持兼容性,var命令和function命令声明的全局变量,依旧是顶层对象的属性;另一方面规定,let命令、const命令、class命令声明的全局变量,不属于顶层对象的属性。也就是说,从ES6开始,全局变量将逐步与顶层对象的属性脱钩。
1 | var a = 1; |
变量的解构赋值
数组
如果等号的右边不是数组(或者严格地说,不是可遍历的结构,参见《Iterator》一章),那么将会报错。
1 | 1//“模式匹配” |
对象
1 | //数组的元素是按次序排列的,变量的取值由它的位置决定;对象的属性没有次序,变量必须与属性同名,才能取到正确的值。 |
//注意点
/如果要将一个已经声明的变量用于解构赋值,必须非常小心。
1
2
3
4
5
6//JavaScript 引擎会将{x}理解成一个代码块,从而发生语法错误。只有不将大括号写在行首,避免 JavaScript 将其解释为代码块,才能解决这个问题。
let x;
{x} = {x: 1};// SyntaxError: syntax error
// 正确的写法
let x;
({x} = {x: 1});由于数组本质是特殊的对象,因此可以对数组进行对象属性的解构。
1
2
3
4let arr = [1, 2, 3];
let {0 : first, [arr.length - 1] : last} = arr;
first // 1
last // 3
字符串
1 | const [a, b, c, d, e] = 'hello'; |
函数参数
1 | function add([x, y]){ |
函数参数的默认值
1 | function move({ x = 0, y = 0 } = {}) { |
1 | function foo({ x, y = 5 }) { |
解构赋值的默认值
1 | function move({ x, y } = { x: 0, y: 0 }) { |
上面代码是为函数move的参数指定默认值,而不是为变量x和y指定默认值
为了更容易理解,将上面两个代码合成一个,如下。
1 | function move({x = 0, y = 0} = { x: 1, y: 1 }) { |
变量的解构赋值的作用
(1)交换变量的值
(2)从函数返回多个值
1 | // 返回一个数组 |
(3)函数参数的定义
1 | //有序的参数: |
(4)提取 JSON 数据
1 | let jsonData = { |
(4)函数参数的默认值(数组或者对象的默认值)
1 | function foo({ x, y = 5 }) { |
(5)遍历 Map 结构
1 | var map = new Map(); |
(6)输入模块的指定方法
1 | const {first,second} = require('xxx'); |
数据类型扩展
字符串的扩展
String.fromCodePoint()
ES5 提供String.fromCharCode()方法,用于从 Unicode 码点返回对应字符,但是这个方法不能识别码点大于0xFFFF的字符。
1 | String.fromCharCode(0x20BB7) |
上面代码中,String.fromCharCode()不能识别大于0xFFFF的码点,所以0x20BB7就发生了溢出,最高位2被舍弃了,最后返回码点U+0BB7对应的字符,而不是码点U+20BB7对应的字符。
ES6 提供了String.fromCodePoint()方法,可以识别大于0xFFFF的字符,弥补了String.fromCharCode()方法的不足。在作用上,正好与下面的codePointAt()方法相反。
1 | String.fromCodePoint(0x20BB7) |
上面代码中,如果String.fromCodePoint方法有多个参数,则它们会被合并成一个字符串返回。
注意,fromCodePoint方法定义在String对象上,而codePointAt方法定义在字符串的实例对象上。
String.raw()
ES6 还为原生的 String 对象,提供了一个raw()方法。该方法返回一个斜杠都被转义(即斜杠前面再加一个斜杠)的字符串,往往用于模板字符串的处理方法。
1 | String.raw`Hi\n${2+3}!` |
如果原字符串的斜杠已经转义,那么String.raw()会进行再次转义。
1 | String.raw`Hi\\n` |
String.raw()方法可以作为处理模板字符串的基本方法,它会将所有变量替换,而且对斜杠进行转义,方便下一步作为字符串来使用。
String.raw()本质上是一个正常的函数,只是专用于模板字符串的标签函数。如果写成正常函数的形式,它的第一个参数,应该是一个具有raw属性的对象,且raw属性的值应该是一个数组,对应模板字符串解析后的值。
1 | // `foo${1 + 2}bar` |
上面代码中,String.raw()方法的第一个参数是一个对象,它的raw属性等同于原始的模板字符串解析后得到的数组。
作为函数,String.raw()的代码实现基本如下。
1 | String.raw = function (strings, ...values) { |
codePointAt()
JavaScript 内部,字符以 UTF-16 的格式储存,每个字符固定为2个字节。对于那些需要4个字节储存的字符(Unicode 码点大于0xFFFF的字符),JavaScript 会认为它们是两个字符。
1 | var s = "𠮷"; |
上面代码中,汉字“𠮷”(注意,这个字不是“吉祥”的“吉”)的码点是0x20BB7,UTF-16 编码为0xD842 0xDFB7(十进制为55362 57271),需要4个字节储存。对于这种4个字节的字符,JavaScript 不能正确处理,字符串长度会误判为2,而且charAt()方法无法读取整个字符,charCodeAt()方法只能分别返回前两个字节和后两个字节的值。
ES6 提供了codePointAt()方法,能够正确处理 4 个字节储存的字符,返回一个字符的码点。
1 | let s = '𠮷a'; |
codePointAt()方法的参数,是字符在字符串中的位置(从 0 开始)。上面代码中,JavaScript 将“𠮷a”视为三个字符,codePointAt 方法在第一个字符上,正确地识别了“𠮷”,返回了它的十进制码点 134071(即十六进制的20BB7)。在第二个字符(即“𠮷”的后两个字节)和第三个字符“a”上,codePointAt()方法的结果与charCodeAt()方法相同。
总之,codePointAt()方法会正确返回 32 位的 UTF-16 字符的码点。对于那些两个字节储存的常规字符,它的返回结果与charCodeAt()方法相同。
codePointAt()方法返回的是码点的十进制值,如果想要十六进制的值,可以使用toString()方法转换一下。
1 | let s = '𠮷a'; |
你可能注意到了,codePointAt()方法的参数,仍然是不正确的。比如,上面代码中,字符a在字符串s的正确位置序号应该是 1,但是必须向codePointAt()方法传入 2。解决这个问题的一个办法是使用for...of循环,因为它会正确识别 32 位的 UTF-16 字符。
1 | let s = '𠮷a'; |
另一种方法也可以,使用扩展运算符(...)进行展开运算。
1 | let arr = [...'𠮷a']; // arr.length === 2 |
codePointAt()方法是测试一个字符由两个字节还是由四个字节组成的最简单方法。
1 | function is32Bit(c) { |
normalize()
许多欧洲语言有语调符号和重音符号。为了表示它们,Unicode 提供了两种方法。一种是直接提供带重音符号的字符,比如Ǒ(\u01D1)。另一种是提供合成符号(combining character),即原字符与重音符号的合成,两个字符合成一个字符,比如O(\u004F)和ˇ(\u030C)合成Ǒ(\u004F\u030C)。
这两种表示方法,在视觉和语义上都等价,但是 JavaScript 不能识别。
1 | '\u01D1'==='\u004F\u030C' //false |
上面代码表示,JavaScript 将合成字符视为两个字符,导致两种表示方法不相等。
ES6 提供字符串实例的normalize()方法,用来将字符的不同表示方法统一为同样的形式,这称为 Unicode 正规化。
1 | '\u01D1'.normalize() === '\u004F\u030C'.normalize() |
normalize方法可以接受一个参数来指定normalize的方式,参数的四个可选值如下。
NFC,默认参数,表示“标准等价合成”(Normalization Form Canonical Composition),返回多个简单字符的合成字符。所谓“标准等价”指的是视觉和语义上的等价。NFD,表示“标准等价分解”(Normalization Form Canonical Decomposition),即在标准等价的前提下,返回合成字符分解的多个简单字符。NFKC,表示“兼容等价合成”(Normalization Form Compatibility Composition),返回合成字符。所谓“兼容等价”指的是语义上存在等价,但视觉上不等价,比如“囍”和“喜喜”。(这只是用来举例,normalize方法不能识别中文。)NFKD,表示“兼容等价分解”(Normalization Form Compatibility Decomposition),即在兼容等价的前提下,返回合成字符分解的多个简单字符。
1 | '\u004F\u030C'.normalize('NFC').length // 1 |
上面代码表示,NFC参数返回字符的合成形式,NFD参数返回字符的分解形式。
不过,normalize方法目前不能识别三个或三个以上字符的合成。这种情况下,还是只能使用正则表达式,通过 Unicode 编号区间判断。
includes(), startsWith(), endsWith()
传统上,JavaScript 只有indexOf方法,可以用来确定一个字符串是否包含在另一个字符串中。ES6 又提供了三种新方法。
- **includes()**:返回布尔值,表示是否找到了参数字符串。
- **startsWith()**:返回布尔值,表示参数字符串是否在原字符串的头部。
- **endsWith()**:返回布尔值,表示参数字符串是否在原字符串的尾部。
1 | let s = 'Hello world!'; |
这三个方法都支持第二个参数,表示开始搜索的位置。
1 | let s = 'Hello world!'; |
上面代码表示,使用第二个参数n时,endsWith的行为与其他两个方法有所不同。它针对前n个字符,而其他两个方法针对从第n个位置直到字符串结束。
repeat()
repeat方法返回一个新字符串,表示将原字符串重复n次。
1 | 'x'.repeat(3) // "xxx" |
参数如果是小数,会被取整。
1 | 'na'.repeat(2.9) // "nana" |
如果repeat的参数是负数或者Infinity,会报错。
1 | 'na'.repeat(Infinity) |
但是,如果参数是 0 到-1 之间的小数,则等同于 0,这是因为会先进行取整运算。0 到-1 之间的小数,取整以后等于-0,repeat视同为 0。
1 | 'na'.repeat(-0.9) // "" |
参数NaN等同于 0。
1 | 'na'.repeat(NaN) // "" |
如果repeat的参数是字符串,则会先转换成数字。
1 | 'na'.repeat('na') // "" |
padStart(),padEnd()
ES2017 引入了字符串补全长度的功能。如果某个字符串不够指定长度,会在头部或尾部补全。padStart()用于头部补全,padEnd()用于尾部补全。
1 | 'x'.padStart(5, 'ab') // 'ababx' |
上面代码中,padStart()和padEnd()一共接受两个参数,第一个参数是字符串补全生效的最大长度,第二个参数是用来补全的字符串。
如果原字符串的长度,等于或大于最大长度,则字符串补全不生效,返回原字符串。
1 | 'xxx'.padStart(2, 'ab') // 'xxx' |
如果用来补全的字符串与原字符串,两者的长度之和超过了最大长度,则会截去超出位数的补全字符串。
1 | 'abc'.padStart(10, '0123456789') |
如果省略第二个参数,默认使用空格补全长度。
1 | 'x'.padStart(4) // ' x' |
padStart()的常见用途是为数值补全指定位数。下面代码生成 10 位的数值字符串。
1 | '1'.padStart(10, '0') // "0000000001" |
另一个用途是提示字符串格式。
1 | '12'.padStart(10, 'YYYY-MM-DD') // "YYYY-MM-12" |
trimStart(),trimEnd()
ES2019 对字符串实例新增了trimStart()和trimEnd()这两个方法。它们的行为与trim()一致,trimStart()消除字符串头部的空格,trimEnd()消除尾部的空格。它们返回的都是新字符串,不会修改原始字符串。
1 | const s = ' abc '; |
上面代码中,trimStart()只消除头部的空格,保留尾部的空格。trimEnd()也是类似行为。
除了空格键,这两个方法对字符串头部(或尾部)的 tab 键、换行符等不可见的空白符号也有效。
浏览器还部署了额外的两个方法,trimLeft()是trimStart()的别名,trimRight()是trimEnd()的别名。
matchAll()
matchAll()方法返回一个正则表达式在当前字符串的所有匹配,详见《正则的扩展》的一章。
replaceAll()
历史上,字符串的实例方法replace()只能替换第一个匹配。
1 | 'aabbcc'.replace('b', '_') |
上面例子中,replace()只将第一个b替换成了下划线。
如果要替换所有的匹配,不得不使用正则表达式的g修饰符。
1 | 'aabbcc'.replace(/b/g, '_') |
正则表达式毕竟不是那么方便和直观,ES2021 引入了replaceAll()方法,可以一次性替换所有匹配。
1 | 'aabbcc'.replaceAll('b', '_') |
它的用法与replace()相同,返回一个新字符串,不会改变原字符串。
1 | String.prototype.replaceAll(searchValue, replacement) |
上面代码中,searchValue是搜索模式,可以是一个字符串,也可以是一个全局的正则表达式(带有g修饰符)。
如果searchValue是一个不带有g修饰符的正则表达式,replaceAll()会报错。这一点跟replace()不同。
1 | // 不报错 |
上面例子中,/b/不带有g修饰符,会导致replaceAll()报错。
replaceAll()的第二个参数replacement是一个字符串,表示替换的文本,其中可以使用一些特殊字符串。
$&:匹配的字符串。$`:匹配结果前面的文本。$':匹配结果后面的文本。$n:匹配成功的第n组内容,n是从1开始的自然数。这个参数生效的前提是,第一个参数必须是正则表达式。$$:指代美元符号$。
下面是一些例子。
1 | // $& 表示匹配的字符串,即`b`本身 |
replaceAll()的第二个参数replacement除了为字符串,也可以是一个函数,该函数的返回值将替换掉第一个参数searchValue匹配的文本。
1 | 'aabbcc'.replaceAll('b', () => '_') |
上面例子中,replaceAll()的第二个参数是一个函数,该函数的返回值会替换掉所有b的匹配。
这个替换函数可以接受多个参数。第一个参数是捕捉到的匹配内容,第二个参数捕捉到是组匹配(有多少个组匹配,就有多少个对应的参数)。此外,最后还可以添加两个参数,倒数第二个参数是捕捉到的内容在整个字符串中的位置,最后一个参数是原字符串。
1 | const str = '123abc456'; |
上面例子中,正则表达式有三个组匹配,所以replacer()函数的第一个参数match是捕捉到的匹配内容(即字符串123abc456),后面三个参数p1、p2、p3则依次为三个组匹配。
at()
at()方法接受一个整数作为参数,返回参数指定位置的字符,支持负索引(即倒数的位置)。
1 | const str = 'hello'; |
如果参数位置超出了字符串范围,at()返回undefined。
该方法来自数组添加的at()方法,目前还是一个第三阶段的提案,可以参考《数组》一章的介绍。
正则的扩展
字符串对象共有4个方法,可以使用正则表达式:match()、replace()、search()和split()。
ES6对正则表达式添加了u修饰符,含义为“Unicode模式”,用来正确处理大于\uFFFF的Unicode字符。也就是说,会正确处理四个字节的UTF-16编码。
1 | /^\uD83D/u.test('\uD83D\uDC2A') |
对于码点大于0xFFFF的Unicode字符,点字符不能识别,必须加上u修饰符。
1 | var s = '𠮷'; |
ES6新增了使用大括号表示Unicode字符,这种表示法在正则表达式中必须加上u修饰符,才能识别。 使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符。
除了u修饰符,ES6还为正则表达式添加了y修饰符,叫做“粘连”(sticky)修饰符。
g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始,这也就是“粘连”的涵义。
运算符
指数运算符
ES2016 新增了一个指数运算符(**)。
1 | 2 ** 2 // 4 |
这个运算符的一个特点是右结合,而不是常见的左结合。多个指数运算符连用时,是从最右边开始计算的。
1 | // 相当于 2 ** (3 ** 2) |
上面代码中,首先计算的是第二个指数运算符,而不是第一个。
指数运算符可以与等号结合,形成一个新的赋值运算符(**=)。
1 | let a = 1.5; |
链判断运算符
编程实务中,如果读取对象内部的某个属性,往往需要判断一下,属性的上层对象是否存在。比如,读取message.body.user.firstName这个属性,安全的写法是写成下面这样。
1 | // 错误的写法 |
上面例子中,firstName属性在对象的第四层,所以需要判断四次,每一层是否有值。
三元运算符?:也常用于判断对象是否存在。
1 | const fooInput = myForm.querySelector('input[name=foo]') |
上面例子中,必须先判断fooInput是否存在,才能读取fooInput.value。
这样的层层判断非常麻烦,因此 ES2020 引入了“链判断运算符”(optional chaining operator)?.,简化上面的写法。
1 | const firstName = message?.body?.user?.firstName || 'default'; |
上面代码使用了?.运算符,直接在链式调用的时候判断,左侧的对象是否为null或undefined。如果是的,就不再往下运算,而是返回undefined。
下面是判断对象方法是否存在,如果存在就立即执行的例子。
1 | iterator.return?.() |
上面代码中,iterator.return如果有定义,就会调用该方法,否则iterator.return直接返回undefined,不再执行?.后面的部分。
对于那些可能没有实现的方法,这个运算符尤其有用。
1 | if (myForm.checkValidity?.() === false) { |
上面代码中,老式浏览器的表单对象可能没有checkValidity()这个方法,这时?.运算符就会返回undefined,判断语句就变成了undefined === false,所以就会跳过下面的代码。
链判断运算符?.有三种写法。
obj?.prop// 对象属性是否存在obj?.[expr]// 同上func?.(...args)// 函数或对象方法是否存在
下面是obj?.[expr]用法的一个例子。
1 | let hex = "#C0FFEE".match(/#([A-Z]+)/i)?.[1]; |
上面例子中,字符串的match()方法,如果没有发现匹配会返回null,如果发现匹配会返回一个数组,?.运算符起到了判断作用。
下面是?.运算符常见形式,以及不使用该运算符时的等价形式。
1 | a?.b |
上面代码中,特别注意后两种形式,如果a?.b()和a?.()。如果a?.b()里面的a.b有值,但不是函数,不可调用,那么a?.b()是会报错的。a?.()也是如此,如果a不是null或undefined,但也不是函数,那么a?.()会报错。
使用这个运算符,有几个注意点。
(1)短路机制
本质上,?.运算符相当于一种短路机制,只要不满足条件,就不再往下执行。
1 | a?.[++x] |
上面代码中,如果a是undefined或null,那么x不会进行递增运算。也就是说,链判断运算符一旦为真,右侧的表达式就不再求值。
(2)括号的影响
如果属性链有圆括号,链判断运算符对圆括号外部没有影响,只对圆括号内部有影响。
1 | (a?.b).c |
上面代码中,?.对圆括号外部没有影响,不管a对象是否存在,圆括号后面的.c总是会执行。
一般来说,使用?.运算符的场合,不应该使用圆括号。
(3)报错场合
以下写法是禁止的,会报错。
1 | // 构造函数 |
(4)右侧不得为十进制数值
为了保证兼容以前的代码,允许foo?.3:0被解析成foo ? .3 : 0,因此规定如果?.后面紧跟一个十进制数字,那么?.不再被看成是一个完整的运算符,而会按照三元运算符进行处理,也就是说,那个小数点会归属于后面的十进制数字,形成一个小数。
Null 判断运算符
读取对象属性的时候,如果某个属性的值是null或undefined,有时候需要为它们指定默认值。常见做法是通过||运算符指定默认值。
1 | const headerText = response.settings.headerText || 'Hello, world!'; |
上面的三行代码都通过||运算符指定默认值,但是这样写是错的。开发者的原意是,只要属性的值为null或undefined,默认值就会生效,但是属性的值如果为空字符串或false或0,默认值也会生效。
为了避免这种情况,ES2020 引入了一个新的 Null 判断运算符??。它的行为类似||,但是只有运算符左侧的值为null或undefined时,才会返回右侧的值。
1 | const headerText = response.settings.headerText ?? 'Hello, world!'; |
上面代码中,默认值只有在左侧属性值为null或undefined时,才会生效。
这个运算符的一个目的,就是跟链判断运算符?.配合使用,为null或undefined的值设置默认值。
1 | const animationDuration = response.settings?.animationDuration ?? 300; |
上面代码中,如果response.settings是null或undefined,或者response.settings.animationDuration是null或undefined,就会返回默认值300。也就是说,这一行代码包括了两级属性的判断。
这个运算符很适合判断函数参数是否赋值。
1 | function Component(props) { |
上面代码判断props参数的enabled属性是否赋值,基本等同于下面的写法。
1 | function Component(props) { |
??本质上是逻辑运算,它与其他两个逻辑运算符&&和||有一个优先级问题,它们之间的优先级到底孰高孰低。优先级的不同,往往会导致逻辑运算的结果不同。
现在的规则是,如果多个逻辑运算符一起使用,必须用括号表明优先级,否则会报错。
1 | // 报错 |
上面四个表达式都会报错,必须加入表明优先级的括号。
1 | (lhs && middle) ?? rhs; |
逻辑赋值运算符
ES2021 引入了三个新的逻辑赋值运算符(logical assignment operators),将逻辑运算符与赋值运算符进行结合。
1 | // 或赋值运算符 |
这三个运算符||=、&&=、??=相当于先进行逻辑运算,然后根据运算结果,再视情况进行赋值运算。
它们的一个用途是,为变量或属性设置默认值。
1 | // 老的写法 |
上面示例中,user.id属性如果不存在,则设为1,新的写法比老的写法更紧凑一些。
下面是另一个例子。
1 | function example(opts) { |
上面示例中,参数对象opts如果不存在属性foo和属性baz,则为这两个属性设置默认值。有了“Null 赋值运算符”以后,就可以统一写成下面这样。
1 | function example(opts) { |
#!命令
Unix 的命令行脚本都支持#!命令,又称为 Shebang 或 Hashbang。这个命令放在脚本的第一行,用来指定脚本的执行器。
比如 Bash 脚本的第一行。
1 |
Python 脚本的第一行。
1 | #!/usr/bin/env python |
ES2023 为 JavaScript 脚本引入了#!命令,写在脚本文件或者模块文件的第一行。
1 | // 写在脚本文件第一行 |
有了这一行以后,Unix 命令行就可以直接执行脚本。
1 | # 以前执行脚本的方式 |
对于 JavaScript 引擎来说,会把#!理解成注释,忽略掉这一行。
数值的扩展
二进制和八进制表达方式
ES6提供了二进制和八进制数值的新的写法,分别用前缀0b(或0B)和0o(或0O)表示。
1 | 0b111110111 === 503 // true |
从ES5开始,在严格模式之中,八进制就不再允许使用前缀0表示,ES6进一步明确,要使用前缀0o表示。
1 | // 非严格模式 |
如果要将0b和0o前缀的字符串数值转为十进制,要使用Number方法。
1 | Number('0b111') // 7 |
isFinite和isNaN
Number.isFinite()用来检查一个数值是否为有限的(finite)。
1 | Number.isFinite(15); // true |
Number.isNaN()用来检查一个值是否为NaN。
1 | Number.isNaN(NaN) // true |
它们与传统的全局方法isFinite()和isNaN()的区别在于,传统方法先调用Number()将非数值的值转为数值,再进行判断,而这两个新方法只对数值有效,非数值一律返回false。
parseInt和parseFloat
1 | // ES5的写法 |
isInteger
Number.isInteger()用来判断一个数值是否为整数。需要注意的是,在JavaScript内部,整数和浮点数是同样的储存方法,所以3和3.0被视为同一个值。
1 | Number.isInteger(25) // true |
Math对象的扩展
Math.trunc()
1 | //1. |
Math.sign()
Math.sign方法用来判断一个数到底是正数、负数、还是零。
它会返回五种值。
- 参数为正数,返回+1;
- 参数为负数,返回-1;
- 参数为0,返回0;
- 参数为-0,返回-0;
- 其他值,返回NaN。
1 | Math.sign('') // 0 |
Math.cbrt()
方法用于计算一个数的立方根。对于非数值,Math.cbrt()方法内部也是先使用Number()方法将其转为数值。
Math.logn()
Math.log2(x)返回以 2 为底的x的对数。如果x小于 0,则返回 NaN。
数组的扩展
from
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据结构Set和Map)。
1 | //类似数组的对象 |
实际应用中,常见的类似数组的对象是DOM操作返回的NodeList集合,以及函数内部的arguments对象。Array.from都可以将它们转为真正的数组。
只要是部署了Iterator接口的数据结构,Array.from都能将其转为数组。
1 | // 可遍历(iterable) |
值得提醒的是,扩展运算符(…)也可以将某些数据结构转为数组。
1 | // arguments对象 |
扩展运算符背后调用的是遍历器接口(Symbol.iterator),如果一个对象没有部署这个接口,就无法转换。Array.from方法则是还支持类似数组的对象。所谓类似数组的对象,本质特征只有一点,即必须有length属性。因此,任何有length属性的对象,都可以通过Array.from方法转为数组,而此时扩展运算符就无法转换。
1 | Array.from({ length: 3 }); |
Array.from还可以接受第二个参数,作用类似于数组的map方法,用来对每个元素进行处理,将处理后的值放入返回的数组。
1 | Array.from(arrayLike, x => x * x); |
下面的例子是取出一组DOM节点的文本内容。
1 | let spans = document.querySelectorAll('span.name'); |
Array.of
Array.of方法用于将一组值,转换为数组。
1 | Array.of(3, 11, 8) // [3,11,8] |
这个方法的主要目的,是弥补数组构造函数Array()的不足。因为参数个数的不同,会导致Array()的行为有差异。
1 | Array() // [] |
Array.of基本上可以用来替代Array()或new Array(),并且不存在由于参数不同而导致的重载。它的行为非常统一。
1 | Array.of() // [] |
copyWithin
数组实例的copyWithin方法,在当前数组内部,将指定位置的成员复制到其他位置(会覆盖原有成员),然后返回当前数组。也就是说,使用这个方法,会修改当前数组。
1 | Array.prototype.copyWithin(target, start = 0, end = this.length) |
它接受三个参数。
- target(必需):从该位置开始替换数据。
- start(可选):从该位置开始读取数据,默认为0。如果为负值,表示倒数。
- end(可选):到该位置前停止读取数据,默认等于数组长度。如果为负值,表示倒数。
这三个参数都应该是数值,如果不是,会自动转为数值。
1 | [1, 2, 3, 4, 5].copyWithin(0, 3) |
上面代码表示将从3号位直到数组结束的成员(4和5),复制到从0号位开始的位置,结果覆盖了原来的1和2。
1 | // 将3号位复制到0号位 |
find和findIndex
数组实例的find()方法,用于找出第一个符合条件的数组成员。它的参数是一个回调函数,所有数组成员依次执行该回调函数,直到找出第一个返回值为true的成员,然后返回该成员。如果没有符合条件的成员,则返回undefined。
1 | [1, 4, -5, 10].find((n) => n < 0) |
上面代码找出数组中第一个小于 0 的成员。
1 | [1, 5, 10, 15].find(function(value, index, arr) { |
上面代码中,find()方法的回调函数可以接受三个参数,依次为当前的值、当前的位置和原数组。
数组实例的findIndex()方法的用法与find()方法非常类似,返回第一个符合条件的数组成员的位置,如果所有成员都不符合条件,则返回-1。
1 | [1, 5, 10, 15].findIndex(function(value, index, arr) { |
这两个方法都可以接受第二个参数,用来绑定回调函数的this对象。
1 | function f(v){ |
上面的代码中,find()函数接收了第二个参数person对象,回调函数中的this对象指向person对象。
另外,这两个方法都可以发现NaN,弥补了数组的indexOf()方法的不足。
1 | [NaN].indexOf(NaN) |
上面代码中,indexOf()方法无法识别数组的NaN成员,但是findIndex()方法可以借助Object.is()方法做到。
find()和findIndex()都是从数组的0号位,依次向后检查。ES2022 新增了两个方法findLast()和findLastIndex(),从数组的最后一个成员开始,依次向前检查,其他都保持不变。
1 | const array = [ |
上面示例中,findLast()和findLastIndex()从数组结尾开始,寻找第一个value属性为奇数的成员。结果,该成员是{ value: 3 },位置是2号位。
fill()
fill方法使用给定值,填充一个数组。
1 | ['a', 'b', 'c'].fill(7) |
上面代码表明,fill方法用于空数组的初始化非常方便。
entries和keys和values
ES6提供三个新的方法——entries(),keys()和values()——用于遍历数组。它们都返回一个遍历器对象(详见《Iterator》一章),可以用for...of循环进行遍历,唯一的区别是keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。
1 | for (let index of ['a', 'b'].keys()) { |
如果不使用for...of循环,可以手动调用遍历器对象的next方法,进行遍历。
1 | let letter = ['a', 'b', 'c']; |
includes()
Array.prototype.includes方法返回一个布尔值,表示某个数组是否包含给定的值,与字符串的includes方法类似。该方法属于ES7,但Babel转码器已经支持。
1 | [1, 2, 3].includes(2); // true |
1 | [{a:1},2,3,{b:2}].includes({a:1})//false |
at
1 | const arr = [5, 12, 8, 130, 44]; |
如果参数位置超出了数组范围,at()返回undefined。
1 | const sentence = 'This is a sample sentence'; |
数组的空位
数组的空位指,数组的某一个位置没有任何值。比如,Array构造函数返回的数组都是空位。
1 | Array(3) // [, , ,] |
上面代码中,Array(3)返回一个具有3个空位的数组。
注意,空位不是undefined,一个位置的值等于undefined,依然是有值的。空位是没有任何值,in运算符可以说明这一点。
1 | 0 in [undefined, undefined, undefined] // true |
上面代码说明,第一个数组的0号位置是有值的,第二个数组的0号位置没有值。
ES5对空位的处理,已经很不一致了,大多数情况下会忽略空位。
forEach(),filter(),every()和some()都会跳过空位。map()会跳过空位,但会保留这个值join()和toString()会将空位视为undefined,而undefined和null会被处理成空字符串。
1 | // forEach方法 |
ES6则是明确将空位转为undefined。
Array.from方法会将数组的空位,转为undefined,也就是说,这个方法不会忽略空位。
1 | Array.from(['a',,'b']) |
扩展运算符(...)也会将空位转为undefined。
1 | [...['a',,'b']] |
copyWithin()会连空位一起拷贝。
1 | [,'a','b',,].copyWithin(2,0) // [,"a",,"a"] |
fill()会将空位视为正常的数组位置。
1 | new Array(3).fill('a') // ["a","a","a"] |
for...of循环也会遍历空位。
1 | let arr = [, ,]; |
上面代码中,数组arr有两个空位,for...of并没有忽略它们。如果改成map方法遍历,空位是会跳过的。
entries()、keys()、values()、find()和findIndex()会将空位处理成undefined。
1 | // entries() |
由于空位的处理规则非常不统一,所以建议避免出现空位。
对象的扩展
简洁表示法
属性简写
ES6允许直接写入变量和函数,作为对象的属性和方法。这样的书写更加简洁。
1 | var foo = 'bar'; |
上面代码表明,ES6允许在对象之中,直接写变量。这时,属性名为变量名, 属性值为变量的值。下面是另一个例子。
1 | function f(x, y) { |
方法简写
1 | var o = { |
下面是一个实际的例子。
1 | var birth = '2000/01/01'; |
这种写法用于函数的返回值,将会非常方便。
1 | function getPoint() { |
CommonJS模块输出变量,就非常合适使用简洁写法。
1 | var ms = {}; |
属性的赋值器(setter)和取值器(getter),事实上也是采用这种写法。
1 | var cart = { |
注意,简洁写法的属性名总是字符串,这会导致一些看上去比较奇怪的结果。
1 | var obj = { |
上面代码中,class是字符串,所以不会因为它属于关键字,而导致语法解析报错。
如果某个方法的值是一个Generator函数,前面需要加上星号。
1 | var obj = { |
属性名表达式
JavaScript语言定义对象的属性,有两种方法。
1 | var obj = { |
方法一是直接用标识符作为属性名,方法二是用表达式作为属性名,这时要将表达式放在方括号之内。
ES6 允许字面量定义对象时,用方法二(表达式)作为对象的属性名,即把表达式放在方括号内。
1 | let propKey = 'foo'; |
下面是另一个例子。
1 | var lastWord = 'last word'; |
表达式还可以用于定义方法名。
1 | let obj = { |
注意,属性名表达式与简洁表示法,不能同时使用,会报错。
1 | // 报错 |
注意,属性名表达式如果是一个对象,默认情况下会自动将对象转为字符串[object Object],这一点要特别小心。
1 | const keyA = {a: 1}; |
上面代码中,[keyA]和[keyB]得到的都是[object Object],所以[keyB]会把[keyA]覆盖掉,而myObject最后只有一个[object Object]属性。
方法的name属性
函数的name属性,返回函数名。对象方法也是函数,因此也有name属性。
1 | var person = { |
super 关键字
我们知道,this关键字总是指向函数所在的当前对象,ES6 又新增了另一个类似的关键字super,指向当前对象的原型对象。
1 | const proto = { |
上面代码中,对象obj.find()方法之中,通过super.foo引用了原型对象proto的foo属性。
注意,super关键字表示原型对象时,只能用在对象的方法之中,用在其他地方都会报错。
1 | // 报错 |
上面三种super的用法都会报错,因为对于 JavaScript 引擎来说,这里的super都没有用在对象的方法之中。第一种写法是super用在属性里面,第二种和第三种写法是super用在一个函数里面,然后赋值给foo属性。目前,只有对象方法的简写法可以让 JavaScript 引擎确认,定义的是对象的方法。
JavaScript 引擎内部,super.foo等同于Object.getPrototypeOf(this).foo(属性)或Object.getPrototypeOf(this).foo.call(this)(方法)。
1 | const proto = { |
上面代码中,super.foo指向原型对象proto的foo方法,但是绑定的this却还是当前对象obj,因此输出的就是world。
对象的扩展运算符
目前,ES7有一个提案,将Rest运算符(解构赋值)/扩展运算符(...)引入对象。Babel转码器已经支持这项功能。
解构赋值
对象的解构赋值用于从一个对象取值,相当于将所有可遍历的、但尚未被读取的属性,分配到指定的对象上面。所有的键和它们的值,都会拷贝到新对象上面。
1 | let { x, y, ...z } = { x: 1, y: 2, a: 3, b: 4 }; |
上面代码中,变量z是解构赋值所在的对象。它获取等号右边的所有尚未读取的键(a和b),将它们连同值一起拷贝过来。
由于解构赋值要求等号右边是一个对象,所以如果等号右边是undefined或null,就会报错,因为它们无法转为对象。
1 | let { x, y, ...z } = null; // 运行时错误 |
解构赋值必须是最后一个参数,否则会报错。
1 | let { ...x, y, z } = obj; // 句法错误 |
上面代码中,解构赋值不是最后一个参数,所以会报错。
注意,解构赋值的拷贝是浅拷贝,即如果一个键的值是复合类型的值(数组、对象、函数)、那么解构赋值拷贝的是这个值的引用,而不是这个值的副本。
1 | let obj = { a: { b: 1 } }; |
上面代码中,x是解构赋值所在的对象,拷贝了对象obj的a属性。a属性引用了一个对象,修改这个对象的值,会影响到解构赋值对它的引用。
另外,解构赋值不会拷贝继承自原型对象的属性。
1 | let o1 = { a: 1 }; |
上面代码中,对象o3是o2的拷贝,但是只复制了o2自身的属性,没有复制它的原型对象o1的属性。
下面是另一个例子。
1 | var o = Object.create({ x: 1, y: 2 }); |
上面代码中,变量x是单纯的解构赋值,所以可以读取继承的属性;解构赋值产生的变量y和z,只能读取对象自身的属性,所以只有变量z可以赋值成功。
解构赋值的一个用处,是扩展某个函数的参数,引入其他操作。
1 | function baseFunction({ a, b }) { |
上面代码中,原始函数baseFunction接受a和b作为参数,函数wrapperFunction在baseFunction的基础上进行了扩展,能够接受多余的参数,并且保留原始函数的行为。
扩展运算符
扩展运算符(...)用于取出参数对象的所有可遍历属性,拷贝到当前对象之中。
1 | let z = { a: 3, b: 4 }; |
这等同于使用Object.assign方法。
1 | let aClone = { ...a }; |
扩展运算符可以用于合并两个对象。
1 | let ab = { ...a, ...b }; |
如果用户自定义的属性,放在扩展运算符后面,则扩展运算符内部的同名属性会被覆盖掉。
1 | let aWithOverrides = { ...a, x: 1, y: 2 }; |
上面代码中,a对象的x属性和y属性,拷贝到新对象后会被覆盖掉。
这用来修改现有对象部分的部分属性就很方便了。
1 | let newVersion = { |
上面代码中,newVersion对象自定义了name属性,其他属性全部复制自previousVersion对象。
如果把自定义属性放在扩展运算符前面,就变成了设置新对象的默认属性值。
1 | let aWithDefaults = { x: 1, y: 2, ...a }; |
扩展运算符的参数对象之中,如果有取值函数get,这个函数是会执行的。
1 | // 并不会抛出错误,因为x属性只是被定义,但没执行 |
如果扩展运算符的参数是null或undefined,这个两个值会被忽略,不会报错。
1 | let emptyObject = { ...null, ...undefined }; // 不报错 |
属性描述对象
对象的每个属性都有一个描述对象(Descriptor),用来控制该属性的行为。
Object.getOwnPropertyDescriptor方法可以获取该属性的描述对象。
JavaScript 提供了一个内部数据结构,用来描述对象的属性,控制它的行为,比如该属性是否可写、可遍历等等。这个内部数据结构称为“属性描述对象”(attributes object)。每个属性都有自己对应的属性描述对象,保存该属性的一些元信息。属性描述对象提供6个元属性。
| 属性 | 说明 |
|---|---|
| configurable | 表示新创建的对象是否是可配置的,即对象的属性是否可以被删除或修改,默认false |
| enumerable | 对象属性是否可枚举的,即是否可以枚举,默认false |
| writable | 对象是否可写,是否或以为对象添加新属性,默认false |
| get | 对象getter函数,默认undefined |
| set | 对象setter函数,默认undefined |
value
value是该属性的属性值,默认为undefined。writable
writable是一个布尔值,表示属性值(value)是否可改变(即是否可写),默认为true。enumerableenumerable是一个布尔值,表示该属性是否可遍历,默认为true。如果设为false,会使得某些操作(比如for...in循环、Object.keys())跳过该属性。configurable
configurable是一个布尔值,表示属性的可配置性,默认为true。如果设为false,将阻止某些操作改写属性描述对象,比如无法删除该属性,也不得改变各种元属性(value属性除外)。也就是说,configurable属性控制了属性描述对象的可写性。get
get是一个函数,表示该属性的取值函数(getter),默认为undefined。set
set是一个函数,表示该属性的存值函数(setter),默认为undefined
属性的可枚举性
1 | const obj = { foo: 123 }; |
描述对象的enumerable属性,称为”可枚举性“,如果该属性为false,就表示某些操作会忽略当前属性。
ES5有三个操作会台跳过enumerable为false的属性。
for...in循环:只遍历对象自身的和继承的可枚举的属性Object.keys():返回对象自身的所有可枚举的属性的键名JSON.stringify():只串行化对象自身的可枚举的属性- ES6新增了一个操作
Object.assign(),会忽略enumerable为false的属性,只拷贝对象自身的可枚举的属性。
这四个操作之中,只有for...in会返回继承的属性。实际上,引入enumerable的最初目的,就是让某些属性可以规避掉for...in操作。
比如,对象原型的toString方法,以及数组的length属性,就通过这种手段,不会被for...in遍历到。
1 | Object.getOwnPropertyDescriptor(Object.prototype, 'toString').enumerable |
上面代码中,toString和length属性的enumerable都是false,因此for...in不会遍历到这两个继承自原型的属性。
另外,ES6规定,所有Class的原型的方法都是不可枚举的。
1 | Object.getOwnPropertyDescriptor(class {foo() {}}.prototype, 'foo').enumerable |
总的来说,操作中引入继承的属性会让问题复杂化,大多数时候,我们只关心对象自身的属性。所以,尽量不要用for...in循环,而用Object.keys()代替。
get和set
1 | const person = { |
属性的遍历
1 | const a = { a: 1 }; |
for…in
for...in循环遍历对象自身的和继承的可枚举属性(不含Symbol属性)。
Object.keys()
ES5引入了Object.keys方法,返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键名。
1 | var obj = { foo: "bar", baz: 42 }; |
目前,ES7有一个提案,引入了跟Object.keys配套的Object.values和Object.entries。
1 | let {keys, values, entries} = Object; |
Object.values()
Object.values方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值。
1 | var obj = { foo: "bar", baz: 42 }; |
返回数组的成员顺序,与本章的《属性的遍历》部分介绍的排列规则一致。
1 | var obj = { 100: 'a', 2: 'b', 7: 'c' }; |
上面代码中,属性名为数值的属性,是按照数值大小,从小到大遍历的,因此返回的顺序是b、c、a。
Object.values只返回对象自身的可遍历属性。
1 | var obj = Object.create({}, {p: {value: 42}}); |
上面代码中,Object.create方法的第二个参数添加的对象属性(属性p),如果不显式声明,默认是不可遍历的。Object.values不会返回这个属性。
Object.values会过滤属性名为Symbol值的属性。
1 | Object.values({ [Symbol()]: 123, foo: 'abc' }); |
如果Object.values方法的参数是一个字符串,会返回各个字符组成的一个数组。
1 | Object.values('foo') |
上面代码中,字符串会先转成一个类似数组的对象。字符串的每个字符,就是该对象的一个属性。因此,Object.values返回每个属性的键值,就是各个字符组成的一个数组。
如果参数不是对象,Object.values会先将其转为对象。由于数值和布尔值的包装对象,都不会为实例添加非继承的属性。所以,Object.values会返回空数组。
1 | Object.values(42) // [] |
Object.entries
Object.entries方法返回一个数组,成员是参数对象自身的(不含继承的)所有可遍历(enumerable)属性的键值对数组。
1 | var obj = { foo: 'bar', baz: 42 }; |
除了返回值不一样,该方法的行为与Object.values基本一致。
如果原对象的属性名是一个Symbol值,该属性会被省略。
1 | Object.entries({ [Symbol()]: 123, foo: 'abc' }); |
上面代码中,原对象有两个属性,Object.entries只输出属性名非Symbol值的属性。将来可能会有Reflect.ownEntries()方法,返回对象自身的所有属性。
Object.entries的基本用途是遍历对象的属性。
1 | let obj = { one: 1, two: 2 }; |
Object.entries方法的一个用处是,将对象转为真正的Map结构。
1 | var obj = { foo: 'bar', baz: 42 }; |
自己实现Object.entries方法,非常简单。
1 | // Generator函数的版本 |
方法
属性删除
delete命令用于删除对象的属性,删除成功后返回true。
1 | var obj = {}; |
删除一个不存在的属性,delete不报错,而且返回true。
只有一种情况,delete命令会返回false,那就是该属性存在,且不得删除。
1 | var obj = Object.defineProperty({}, 'p', { |
delete命令只能删除对象本身的属性,无法删除继承的属性
1 | var obj = {}; |
属性是否存在:in
1 | var obj = { p: 1 }; |
in运算符的一个问题是,它不能识别哪些属性是对象自身的,哪些属性是继承的。
可以使用对象的hasOwnProperty方法判断一下,是否为对象自身的属性。
1 | var obj = {}; |
valueOf()
valueOf方法的作用是返回一个对象的“值”,默认情况下返回对象本身。
1 | var obj = new Object({ a: 1 }); |
1 | var obj = new Object(); |
toString()
Object.prototype.toString方法返回对象的类型字符串,因此可以用来判断一个值的类型。
1 | var obj = {}; |
返回一个字符串object Object,其中第二个Object表示该值的构造函数。
由于实例对象可能会自定义toString方法,覆盖掉Object.prototype.toString方法,所以为了得到类型字符串,最好直接使用Object.prototype.toString方法。通过函数的call方法,可以在任意值上调用这个方法,帮助我们判断这个值的类型。
1 | Object.prototype.toString.call(value) |
上面代码表示对value这个值调用Object.prototype.toString方法。
不同数据类型的Object.prototype.toString方法返回值如下。
- 数值:返回
[object Number]。 - 字符串:返回
[object String]。 - 布尔值:返回
[object Boolean]。 - undefined:返回
[object Undefined]。 - null:返回
[object Null]。 - 数组:返回
[object Array]。 - arguments 对象:返回
[object Arguments]。 - 函数:返回
[object Function]。 - Error 对象:返回
[object Error]。 - Date 对象:返回
[object Date]。 - RegExp 对象:返回
[object RegExp]。 - 其他对象:返回
[object Object]。
https://wangdoc.com/javascript/stdlib/attributes.html
Object.is
ES5比较两个值是否相等,只有两个运算符:相等运算符(==)和严格相等运算符(===)。它们都有缺点,前者会自动转换数据类型,后者的NaN不等于自身,以及+0等于-0。JavaScript缺乏一种运算,在所有环境中,只要两个值是一样的,它们就应该相等。
ES6提出“Same-value equality”(同值相等)算法,用来解决这个问题。Object.is就是部署这个算法的新方法。它用来比较两个值是否严格相等,与严格比较运算符(===)的行为基本一致。
1 | Object.is('foo', 'foo') |
不同之处只有两个:一是+0不等于-0,二是NaN等于自身。
1 | +0 === -0 //true |
ES5可以通过下面的代码,部署Object.is。
1 | Object.defineProperty(Object, 'is', { |
Object.create
1 | Object.create(proto,[propertiesObject]) |
proto
新创建对象的原型对象。propertiesObject
为新创建的对象指定属性对象。该属性对象可能包含以下值:
属性 说明 configurable 表示新创建的对象是否是可配置的,即对象的属性是否可以被删除或修改,默认false enumerable 对象属性是否可枚举的,即是否可以枚举,默认false writable 对象是否可写,是否或以为对象添加新属性,默认false get 对象getter函数,默认undefined set 对象setter函数,默认undefined
1 | let obj = Object.create({a:1}, {b:3}) |
Object.assign
https://www.cnblogs.com/xiaoxiaoxun/p/12157591.html
基本用法
Object.assign方法用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target)。
1 | var target = { a: 1 }; |
Object.assign方法的第一个参数是目标对象,后面的参数都是源对象。
注意,如果目标对象与源对象有同名属性,或多个源对象有同名属性,则后面的属性会覆盖前面的属性。
1
2
3
4
5
6
7var target = { a: 1, b: 1 };
var source1 = { b: 2, c: 2 };
var source2 = { c: 3 };
Object.assign(target, source1, source2);
target // {a:1, b:2, c:3}如果只有一个参数,
Object.assign会直接返回该参数。1
2var obj = {a: 1};
Object.assign(obj) === obj // true如果该参数不是对象,则会先转成对象,然后返回。布尔值、数值、字符串分别转成对应的包装对象,可以看到它们的原始值都在包装对象的内部属性
[[PrimitiveValue]]上面,这个属性是不会被Object.assign拷贝的。只有字符串的包装对象,会产生可枚举的实义属性,那些属性则会被拷贝。1
2
3
4
5
6
7Object(true) // {[[PrimitiveValue]]: true}
Object(10) // {[[PrimitiveValue]]: 10}
Object('abc') // {0: "a", 1: "b", 2: "c", length: 3, [[PrimitiveValue]]: "abc"}
//由于`undefined`和`null`无法转成对象,所以如果它们作为参数,就会报错。
Object.assign(undefined) // 报错
Object.assign(null) // 报错
如果非对象参数出现在源对象的位置(即非首参数),那么处理规则有所不同。首先,这些参数都会转成对象,如果无法转成对象,就会跳过。这意味着,如果
undefined和null不在首参数,就不会报错。1
2
3let obj = {a: 1};
Object.assign(obj, undefined) === obj // true
Object.assign(obj, null) === obj // true其他类型的值(即数值、字符串和布尔值)不在首参数,也不会报错。但是,除了字符串会以数组形式,拷贝入目标对象,其他值都不会产生效果。
1
2
3
4
5
6var v1 = 'abc';
var v2 = true;
var v3 = 10;
var obj = Object.assign({}, v1, v2, v3);
console.log(obj); // { "0": "a", "1": "b", "2": "c" }上面代码中,
v1、v2、v3分别是字符串、布尔值和数值,结果只有字符串合入目标对象(以字符数组的形式),数值和布尔值都会被忽略。这是因为只有字符串的包装对象,会产生可枚举属性。
拷贝内容
Object.assign拷贝的属性是有限制的,只拷贝源对象的自身属性(不拷贝继承属性),也不拷贝不可枚举的属性(enumerable: false)。
1 | Object.assign({b: 'c'}, |
上面代码中,Object.assign要拷贝的对象只有一个不可枚举属性invisible,这个属性并没有被拷贝进去。
属性名为Symbol值的属性,也会被Object.assign拷贝。
1 | Object.assign({ a: 'b' }, { [Symbol('c')]: 'd' }) |
注意点
Object.assign方法实行的是浅拷贝,而不是深拷贝。也就是说,如果源对象某个属性的值是对象,那么目标对象拷贝得到的是这个对象的引用。
1 | var obj1 = {a: {b: 1}}; |
上面代码中,源对象obj1的a属性的值是一个对象,Object.assign拷贝得到的是这个对象的引用。这个对象的任何变化,都会反映到目标对象上面。
对于这种嵌套的对象,一旦遇到同名属性,Object.assign的处理方法是替换,而不是添加。
1 | var target = { a: { b: 'c', d: 'e' } } |
上面代码中,target对象的a属性被source对象的a属性整个替换掉了,而不会得到{ a: { b: 'hello', d: 'e' } }的结果。这通常不是开发者想要的,需要特别小心。
有一些函数库提供Object.assign的定制版本(比如Lodash的_.defaultsDeep方法),可以解决浅拷贝的问题,得到深拷贝的合并。
注意,Object.assign可以用来处理数组,但是会把数组视为对象。
1 | Object.assign([1, 2, 3], [4, 5]) |
上面代码中,Object.assign把数组视为属性名为0、1、2的对象,因此目标数组的0号属性4覆盖了原数组的0号属性1。
常见用途
Object.assign方法有很多用处。
(1)为对象添加属性
1 | class Point { |
上面方法通过Object.assign方法,将x属性和y属性添加到Point类的对象实例。
(2)为对象添加方法
1 | Object.assign(SomeClass.prototype, { |
上面代码使用了对象属性的简洁表示法,直接将两个函数放在大括号中,再使用assign方法添加到SomeClass.prototype之中。
(3)克隆对象
1 | function clone(origin) { |
上面代码将原始对象拷贝到一个空对象,就得到了原始对象的克隆。
不过,采用这种方法克隆,只能克隆原始对象自身的值,不能克隆它继承的值。如果想要保持继承链,可以采用下面的代码。
1 | function clone(origin) { |
(4)合并多个对象
将多个对象合并到某个对象。
1 | const merge = |
如果希望合并后返回一个新对象,可以改写上面函数,对一个空对象合并。
1 | const merge = |
(5)为属性指定默认值
1 | const DEFAULTS = { |
上面代码中,DEFAULTS对象是默认值,options对象是用户提供的参数。Object.assign方法将DEFAULTS和options合并成一个新对象,如果两者有同名属性,则option的属性值会覆盖DEFAULTS的属性值。
注意,由于存在深拷贝的问题,DEFAULTS对象和options对象的所有属性的值,都只能是简单类型,而不能指向另一个对象。否则,将导致DEFAULTS对象的该属性不起作用。
Prototype
proto
__proto__属性(前后各两个下划线),用来读取或设置当前对象的prototype对象。目前,所有浏览器(包括IE11)都部署了这个属性。
1 | // es6的写法 |
该属性没有写入ES6的正文,而是写入了附录,原因是__proto__前后的双下划线,说明它本质上是一个内部属性,而不是一个正式的对外的API,只是由于浏览器广泛支持,才被加入了ES6。标准明确规定,只有浏览器必须部署这个属性,其他运行环境不一定需要部署,而且新的代码最好认为这个属性是不存在的。因此,无论从语义的角度,还是从兼容性的角度,都不要使用这个属性
而是使用下面的Object.setPrototypeOf()(写操作)、Object.getPrototypeOf()(读操作)、Object.create()(生成操作)代替。
在实现上,__proto__调用的是Object.prototype.__proto__,具体实现如下。
1 | Object.defineProperty(Object.prototype, '__proto__', { |
如果一个对象本身部署了__proto__属性,则该属性的值就是对象的原型。
1 | Object.getPrototypeOf({ __proto__: null }) |
getPrototypeOf
该方法与setPrototypeOf方法配套,用于读取一个对象的prototype对象。
1 | Object.getPrototypeOf(obj); |
下面是一个例子。
1 | function Rectangle() { |
setPrototypeOf
Object.setPrototypeOf方法的作用与__proto__相同,用来设置一个对象的prototype对象。它是ES6正式推荐的设置原型对象的方法。
1 | // 格式 |
该方法等同于下面的函数。
1 | function (obj, proto) { |
下面是一个例子。
1 | let proto = {}; |
Property
defineProperty
1 | Object.defineProperty(obj, prop, descriptor) |
参数
obj要定义属性的对象。prop要定义或修改的属性的名称或 Symbol 。
descriptor要定义或修改的属性描述符。
对象里目前存在的属性描述符有两种主要形式:*数据描述符和*存取描述符。数据描述符是一个具有值的属性,该值可以是可写的,也可以是不可写的。存取描述符是由 getter 函数和 setter 函数所描述的属性。一个描述符只能是这两者其中之一;不能同时是两者**。
value
与属性关联的值。可以是任何有效的JavaScript值(数字,对象,函数等)。
默认为 undefinedconfigurable 该属性是否可被删除/被改变。默认为 false
enumerable 该属性在循环中是否会被枚举。默认为 false
enumerable定义了对象的属性是否可以在for...in循环和Object.keys()中被枚举。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var o = {};
Object.defineProperty(o, "a", { value : 1, enumerable: true });
Object.defineProperty(o, "b", { value : 2, enumerable: false });
Object.defineProperty(o, "c", { value : 3 }); // enumerable 默认为 false
o.d = 4; // 如果使用直接赋值的方式创建对象的属性,则 enumerable 为 true
Object.defineProperty(o, Symbol.for('e'), {
value: 5,
enumerable: true
});
Object.defineProperty(o, Symbol.for('f'), {
value: 6,
enumerable: false
});
for (var i in o) {
console.log(i);
}
// a,d
Object.keys(o); // ['a', 'd']
writable 该属性是否可写。默认为 false
get 获取属性值时所调用的函数。默认为 undefined
set 该属性的更新操作所调用的函数。默认为 undefined
hasOwnProperty
方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
1 | const object1 = {}; |
即使属性的值是 null 或 undefined,只要属性存在,hasOwnProperty 依旧会返回 true。
1 | o = new Object(); |
自身属性与继承属性
1 | o = new Object(); |
getOwnPropertyDescriptors
ES5有一个Object.getOwnPropertyDescriptor方法,返回某个对象属性的描述对象(descriptor)。
1 | var obj = { p: 'a' }; |
ES7有一个提案,提出了Object.getOwnPropertyDescriptors方法,返回指定对象所有自身属性(非继承属性)的描述对象。
1 | const obj = { |
Object.getOwnPropertyDescriptors方法返回一个对象,所有原对象的属性名都是该对象的属性名,对应的属性值就是该属性的描述对象。
该方法的实现非常容易。
1 | function getOwnPropertyDescriptors(obj) { |
该方法的提出目的,主要是为了解决Object.assign()无法正确拷贝get属性和set属性的问题。
1 | const source = { |
上面代码中,source对象的foo属性的值是一个赋值函数,Object.assign方法将这个属性拷贝给target1对象,结果该属性的值变成了undefined。这是因为Object.assign方法总是拷贝一个属性的值,而不会拷贝它背后的赋值方法或取值方法。
这时,Object.getOwnPropertyDescriptors方法配合Object.defineProperties方法,就可以实现正确拷贝。
1 | const source = { |
上面代码中,将两个对象合并的逻辑提炼出来,就是下面这样。
1 | const shallowMerge = (target, source) => Object.defineProperties( |
Object.getOwnPropertyDescriptors方法的另一个用处,是配合Object.create方法,将对象属性克隆到一个新对象。这属于浅拷贝。
1 | const clone = Object.create(Object.getPrototypeOf(obj), |
上面代码会克隆对象obj。
另外,Object.getOwnPropertyDescriptors方法可以实现,一个对象继承另一个对象。以前,继承另一个对象,常常写成下面这样。
1 | const obj = { |
ES6规定__proto__只有浏览器要部署,其他环境不用部署。如果去除__proto__,上面代码就要改成下面这样。
1 | const obj = Object.create(prot); |
有了Object.getOwnPropertyDescriptors,我们就有了另一种写法。
1 | const obj = Object.create( |
Object.getOwnPropertyDescriptors也可以用来实现Mixin(混入)模式。
1 | let mix = (object) => ({ |
上面代码中,对象a和b被混入了对象c。
出于完整性的考虑,Object.getOwnPropertyDescriptors进入标准以后,还会有Reflect.getOwnPropertyDescriptors方法。
getOwnPropertyNames
该方法返回一个数组,其中包含了当前对象所有属性的名称(字符串),不论它们是否可枚举。当然,也可以用Object.keys()来单独返回可枚举的属性。(不含Symbol属性,但是包括不可枚举属性)
函数的扩展
默认值
函数参数的默认值
在ES6之前,不能直接为函数的参数指定默认值,只能采用变通的方法。
1 | function log(x, y) { |
上面代码检查函数log的参数y有没有赋值,如果没有,则指定默认值为World。这种写法的缺点在于,如果参数y赋值了,但是对应的布尔值为false,则该赋值不起作用。就像上面代码的最后一行,参数y等于空字符,结果被改为默认值。
为了避免这个问题,通常需要先判断一下参数y是否被赋值,如果没有,再等于默认值。
1 | if (typeof y === 'undefined') { |
ES6允许为函数的参数设置默认值,即直接写在参数定义的后面。
1 | function log(x, y = 'World') { |
参数变量是默认声明的,所以不能用let或const再次声明。
1 | function foo(x = 5) { |
解构赋值默认值
参数默认值可以与解构赋值的默认值,结合起来使用。
1 | function foo({x, y = 5}) { |
对比
1 | // 写法一 |
函数的length属性
指定了默认值以后,函数的length属性,将返回没有指定默认值的参数个数。也就是说,指定了默认值后,length属性将失真。
1 | (function (a) {}).length // 1 |
rest参数
ES6引入rest参数(形式为“…变量名”),用于获取函数的多余参数,这样就不需要使用arguments对象了。rest参数搭配的变量是一个数组,该变量将多余的参数放入数组中。
1 | function add(...values) { |
扩展运算符
含义
扩展运算符(spread)是三个点(...)。它好比rest参数的逆运算,将一个数组转为用逗号分隔的参数序列。
1 | console.log(...[1, 2, 3]) |
该运算符主要用于函数调用。
1 | function push(array, ...items) { |
扩展运算符的应用
(1)合并数组
扩展运算符提供了数组合并的新写法。
1 | // ES5 |
(2)与解构赋值结合
扩展运算符可以与解构赋值结合起来,用于生成数组。
1 | const [first, ...rest] = [1, 2, 3, 4, 5]; |
如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错。
1 | const [...butLast, last] = [1, 2, 3, 4, 5]; |
(4)字符串
扩展运算符还可以将字符串转为真正的数组。
1 | [...'hello'] |
(5)实现了Iterator接口的对象
任何Iterator接口的对象,都可以用扩展运算符转为真正的数组。
1 | var nodeList = document.querySelectorAll('div'); |
上面代码中,querySelectorAll方法返回的是一个nodeList对象。它不是数组,而是一个类似数组的对象。这时,扩展运算符可以将其转为真正的数组,原因就在于NodeList对象实现了Iterator接口。
对于那些没有部署Iterator接口的类似数组的对象,扩展运算符就无法将其转为真正的数组。
1 | let arrayLike = { |
上面代码中,arrayLike是一个类似数组的对象,但是没有部署Iterator接口,扩展运算符就会报错。这时,可以改为使用Array.from方法将arrayLike转为真正的数组。
箭头函数
基本用法
ES6允许使用“箭头”(=>)定义函数。
1 | var f = v => v; |
如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回。
1 | var sum = (num1, num2) => { return num1 + num2; } |
由于大括号被解释为代码块,所以如果箭头函数直接返回一个对象,必须在对象外面加上括号。
1 | var getTempItem = id => ({ id: id, name: "Temp" }); |
注意点
函数体内的
this对象,就是定义时所在的对象,而不是使用时所在的对象。箭头函数没有自己的作用域,没有自己的this值,绑定的是父级作用域的上下文
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23var name = 'window'; // 其实是window.name = 'window'
var A = {
name: 'A',
sayHello: function(){
console.log(this.name)
}
}
A.sayHello();// 输出A
var B = {
name: 'B'
}
A.sayHello.call(B);//输出B
A.sayHello.call();//不传参数指向全局window对象,输出window.name也就是window
var name = 'window';
var A = {
name: 'A',
sayHello: () => {
console.log(this.name)
}
}
A.sayHello();// 还是以为输出A ? 错啦,其实输出的是window不可以当作构造函数,也就是说,不可以使用
new命令,否则会抛出一个错误。不可以使用
arguments对象,该对象在函数体内不存在。如果要用,可以用Rest参数代替。不可以使用
yield命令,因此箭头函数不能用作Generator函数。
Iterator循环
概念
JavaScript表示“集合”的数据结构:数组(Array)和对象(Object),Map和Set
若数组的成员是Map,Map的成员是对象 , 这样就需要一种统一的接口机制,来处理所有不同的数据结构。
遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。 任何数据结构只要部署 Iterator 接口,就可以完成遍历操作
Iterator 的遍历过程是这样的。
(1)创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。
(2)第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。
(3)第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。
(4)不断调用指针对象的next方法,直到它指向数据结构的结束位置。
每一次调用next方法,都会返回数据结构的当前成员的信息。具体来说,就是返回一个包含value和done两个属性的对象。其中,value属性是当前成员的值,done属性是一个布尔值,表示遍历是否结束。
模拟next方法返回值的例子。
1 | const it = makeIterator(['a', 'b']); |
数据结构的默认Iterator接口
Iterator接口的目的,就是为所有数据结构,提供了一种统一的访问机制,即for...of循环(详见下文)。当使用for...of循环遍历某种数据结构时,该循环会自动去寻找Iterator接口。
一种数据结构只要部署了Iterator接口,我们就称这种数据结构是”可遍历的“(iterable)。
ES6规定,默认的Iterator接口部署在数据结构的Symbol.iterator属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。
Symbol.iterator属性本身是一个函数,就是当前数据结构默认的遍历器生成函数。执行这个函数,就会返回一个遍历器。至于属性名Symbol.iterator,它是一个表达式,返回Symbol对象的iterator属性,这是一个预定义好的、类型为Symbol的特殊值,所以要放在方括号内
1 | const obj = { |
对象(Object)之所以没有默认部署Iterator接口,是因为对象的哪个属性先遍历,哪个属性后遍历是不确定的,需要开发者手动指定。
一个对象如果要有可被for...of循环调用的Iterator接口,就必须在Symbol.iterator的属性上部署遍历器生成方法(原型链上的对象具有该方法也可)。
1 | class RangeIterator { |
上面代码是一个类部署Iterator接口的写法。Symbol.iterator属性对应一个函数,执行后返回当前对象的遍历器对象。
调用Iterator接口的场合
解构赋值
对数组和 Set 结构进行解构赋值时,会默认调用Symbol.iterator方法。
扩展运算符
扩展运算符(…)也会调用默认的 Iterator 接口。
yield
yield*后面跟的是一个可遍历的结构,它会调用该结构的遍历器接口。
1 | let generator = function* () { |
其他场合
由于数组的遍历会调用遍历器接口,所以任何接受数组作为参数的场合,其实都调用了遍历器接口。下面是一些例子。
- for…of
- Array.from()
- Map(), Set(), WeakMap(), WeakSet()(比如
new Map([['a',1],['b',2]])) - Promise.all()
- Promise.race()
for…of
当使用for...of循环遍历某种数据结构时,该循环会自动去寻找 Iterator 接口。
默认的 Iterator 接口部署在数据结构的Symbol.iterator属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。**Symbol.iterator属性本身是一个函数**,就是当前数据结构默认的遍历器生成函数。 执行这个函数,就会返回一个遍历器对象。
1 | const obj = { |
对象obj是可遍历的(iterable),因为具有Symbol.iterator属性。执行这个属性,会返回一个遍历器对象。
一个对象如果要具备可被for...of循环调用的 Iterator 接口,就必须在Symbol.iterator的属性上部署遍历器生成方法(原型链上的对象具有该方法也可)。 如果Symbol.iterator方法对应的不是遍历器生成函数(即会返回一个遍历器对象),解释引擎将会报错。
原生具备 Iterator 接口的数据结构如下。
- Array
- Map
- Set
- String
- TypedArray
- 函数的 arguments 对象
- NodeList 对象
1 | let arr = ['a', 'b', 'c']; |
变量arr是一个数组,原生就具有遍历器接口,部署在arr的Symbol.iterator属性上面。所以,调用这个属性,就得到遍历器对象。
对于原生部署 Iterator 接口的数据结构,不用自己写遍历器生成函数,for...of循环会自动遍历它们。除此之外,其他数据结构(主要是对象)的 Iterator 接口,都需要自己在Symbol.iterator属性上面部署,这样才会被for...of循环遍历。
与其他遍历语法的比较
最原始的写法就是
for循环。1
2
3for (var index = 0; index < myArray.length; index++) {
console.log(myArray[index]);
}数组提供内置的
forEach方法。1
2
3
4myArray.forEach(function (value) {
console.log(value);
});
//这种写法的问题在于,无法中途跳出forEach循环,break命令或return命令都不能奏效。for...in循环可以遍历数组的键名。1
2
3
4for (var index in myArray) {
console.log(myArray[index]);
}
//for...in循环主要是为遍历对象而设计的,不适用于遍历数组。for...of循环相比上面几种做法,有一些显著的优点。1
2
3
4
5
6for (var n of fibonacci) {
if (n > 1000)
break;
console.log(n);
}
//不同于forEach方法,它可以与break、continue和return配合使用。
Class
传统方法中,JavaScript 通过构造函数实现类的概念,通过原型链实现继承。而在 ES6 中,我们终于迎来了 class。TypeScript 除了实现了所有 ES6 中的类的功能以外,还添加了一些新的用法。
类的概念
虽然 JavaScript 中有类的概念,但是可能大多数 JavaScript 程序员并不是非常熟悉类,这里对类相关的概念做一个简单的介绍。
类(Class):定义了一件事物的抽象特点,包含它的属性和方法
对象(Object):类的实例,通过
new生成面向对象(OOP)的三大特性:封装、继承、多态
- 封装(Encapsulation):将对数据的操作细节隐藏起来,只暴露对外的接口。外界调用端不需要(也不可能)知道细节,就能通过对外提供的接口来访问该对象,同时也保证了外界无法任意更改对象内部的数据
- 继承(Inheritance):子类继承父类,子类除了拥有父类的所有特性外,还有一些更具体的特性
- 多态(Polymorphism):由继承而产生了相关的不同的类,对同一个方法可以有不同的响应。比如
Cat和Dog都继承自Animal,但是分别实现了自己的eat方法。此时针对某一个实例,我们无需了解它是Cat还是Dog,就可以直接调用eat方法,程序会自动判断出来应该如何执行eat
存取器(getter & setter):用以改变属性的读取和赋值行为
修饰符(Modifiers):修饰符是一些关键字,用于限定成员或类型的性质。比如
public表示公有属性或方法抽象类(Abstract Class):抽象类是供其他类继承的基类,抽象类不允许被实例化。抽象类中的抽象方法必须在子类中被实现
接口(Interfaces):不同类之间公有的属性或方法,可以抽象成一个接口。接口可以被类实现(implements)。一个类只能继承自另一个类,但是可以实现多个接口
基本概念和构造函数比较
1 | class Point { |
上面代码定义了一个“类”,可以看到里面有一个constructor方法,这就是构造方法,而this关键字则代表实例对象。也就是说,ES5的构造函数Point,对应ES6的Point类的构造方法。
Point类除了构造方法,还定义了一个toString方法。注意,定义“类”的方法的时候,前面不需要加上function这个关键字,直接把函数定义放进去了就可以了。另外,方法之间不需要逗号分隔,加了会报错。
1 | class Point { |
上面代码表明,类的数据类型就是函数,类本身就指向构造函数。
构造函数的prototype属性,在ES6的“类”上面继续存在。事实上,类的所有方法都定义在类的prototype属性上面。
1 | class Point { |
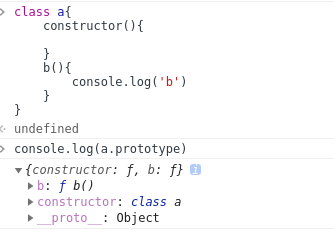
b是B类的实例,它的constructor方法就是B类原型的constructor方法。
1 | class B {} |
Object.assign方法可以很方便地一次向类添加多个方法。
1 | class Point { |
另外,类的内部所有定义的方法,都是不可枚举的(non-enumerable)。
1 | class Point { |
这一点与ES5的行为不一致。
1 | var Point = function (x, y) { |
constructor方法
constructor方法是类的默认方法,通过new命令生成对象实例时,自动调用该方法。一个类必须有constructor方法,如果没有显式定义,一个空的constructor方法会被默认添加。
constructor方法默认返回实例对象(即this),可以指定返回另外一个对象。
1 | class Foo { |
上面代码中,constructor函数返回一个全新的对象,结果导致实例对象不是Foo类的实例。
this的指向
类的方法内部如果含有this,它默认指向类的实例。但是,必须非常小心,一旦单独使用该方法,很可能报错。
1 | class Logger { |
上面代码中,printName方法中的this,默认指向Logger类的实例。但是,如果将这个方法提取出来单独使用,this会指向该方法运行时所在的环境,因为找不到print方法而导致报错。
一个比较简单的解决方法是,在构造方法中绑定this,这样就不会找不到print方法了。
1 | class Logger { |
另一种解决方法是使用箭头函数。
1 | class Logger { |
还有一种解决方法是使用Proxy,获取方法的时候,自动绑定this。
1 | function selfish (target) { |
类的实例对象
类的构造函数,不使用new是没法调用的,会报错。这是它跟普通构造函数的一个主要区别,后者不用new也可以执行。
1 | //定义类 |
上面代码中,x和y都是实例对象point自身的属性(因为定义在this变量上),所以hasOwnProperty方法返回true,而toString是原型对象的属性(因为定义在Point类上),所以hasOwnProperty方法返回false。这些都与ES5的行为保持一致。
与ES5一样,类的所有实例共享一个原型对象。这也意味着,可以通过实例的__proto__属性为Class添加方法。
1 | var p1 = new Point(2,3); |
属性和方法
1 | class Foo { |
类的实例属性
类的实例属性可以用等式,写入类的定义之中。
1 | class MyClass { |
以前,我们定义实例属性,只能写在类的constructor方法里面。上面代码中,myProp就是MyClass的实例属性。在MyClass的实例上,可以读取这个属性。
1 | class ReactCounter extends React.Component { |
上面代码中,构造方法constructor里面,定义了this.state属性。有了新的写法以后,可以不在constructor方法里面定义。
类的静态属性
静态属性指的是Class本身的属性,即Class.myStaticProp,而不是定义在实例对象(this)上的属性。
1 | // 老写法 |
1 | class MyClass { |
类的静态方法
类相当于实例的原型,所有在类中定义的方法,都会被实例继承。如果在一个方法前,加上static关键字,就表示该方法不会被实例继承,而是直接通过类来调用,这就称为“静态方法”。
1 | class Foo { |
上面代码中,Foo类的classMethod方法前有static关键字,表明该方法是一个静态方法,可以直接在Foo类上调用(Foo.classMethod()),而不是在Foo类的实例上调用。如果在实例上调用静态方法,会抛出一个错误,表示不存在该方法。静态属性指的是Class本身的属性,即Class.propname,而不是定义在实例对象(this)上的属性。
父类的静态方法,可以被子类继承。
1 | class Foo { |
上面代码中,父类Foo有一个静态方法,子类Bar可以调用这个方法。
静态方法也是可以从super对象上调用的。
1 | class Foo { |
访问修饰符
访问修饰符(Access Modifiers),分别是 public、private 和 protected。
public修饰的属性或方法是公有的,可以在任何地方被访问到,默认所有的属性和方法都是public的private修饰的属性或方法是私有的,不能在声明它的类的外部访问protected修饰的属性或方法是受保护的,它和private类似,区别是它在子类中也是允许被访问的
下面举一些例子:
1 | class Animal { |
上面的例子中,name 被设置为了 public,所以直接访问实例的 name 属性是允许的。
很多时候,我们希望有的属性是无法直接存取的,这时候就可以用 private 了:
1 | class Animal { |
需要注意的是,TypeScript 编译之后的代码中,并没有限制 private 属性在外部的可访问性。
上面的例子编译后的代码是:
1 | var Animal = (function () { |
使用 private 修饰的属性或方法,在子类中也是不允许访问的:
1 | class Animal { |
而如果是用 protected 修饰,则允许在子类中访问:
1 | class Animal { |
当构造函数修饰为 private 时,该类不允许被继承或者实例化:
1 | class Animal { |
当构造函数修饰为 protected 时,该类只允许被继承:
1 | class Animal { |
readonly
只读属性关键字,只允许出现在属性声明或索引签名或构造函数中。
1 | class Animal { |
注意如果 readonly 和其他访问修饰符同时存在的话,需要写在其后面。
1 | class Animal { |
抽象类
abstract 用于定义抽象类和其中的抽象方法。
什么是抽象类?
首先,抽象类是不允许被实例化的:
1 | abstract class Animal { |
上面的例子中,我们定义了一个抽象类 Animal,并且定义了一个抽象方法 sayHi。在实例化抽象类的时候报错了。
其次,抽象类中的抽象方法必须被子类实现:
1 | abstract class Animal { |
上面的例子中,我们定义了一个类 Cat 继承了抽象类 Animal,但是没有实现抽象方法 sayHi,所以编译报错了。
下面是一个正确使用抽象类的例子:
1 | abstract class Animal { |
上面的例子中,我们实现了抽象方法 sayHi,编译通过了。
需要注意的是,即使是抽象方法,TypeScript 的编译结果中,仍然会存在这个类,上面的代码的编译结果是:
1 | var __extends = |
类的类型
给类加上 TypeScript 的类型很简单,与接口类似:
1 | class Animal { |
属性表达式
1 | let methodName = 'getArea'; |
私有属性
ES2022正式为class添加了私有属性,方法是在属性名之前使用#表示。
1 | class IncreasingCounter { |
上面代码中,#count就是私有属性,只能在类的内部使用(this.#count)。如果在类的外部使用,就会报错。
1 | const counter = new IncreasingCounter(); |
这种写法不仅可以写私有属性,还可以用来写私有方法。
1 | class Foo { |
上面示例中,#sum()就是一个私有方法。
另外,私有属性也可以设置 getter 和 setter 方法。
1 | class Counter { |
get和set
与ES5一样,在Class内部可以使用get和set关键字,对某个属性设置存值函数和取值函数,拦截该属性的存取行为。
1 | class MyClass { |
上面代码中,prop属性有对应的存值函数和取值函数,因此赋值和读取行为都被自定义了。
存值函数和取值函数是设置在属性的descriptor对象上的。
1 | class CustomHTMLElement { |
上面代码中,存值函数和取值函数是定义在html属性的描述对象上面,这与ES5完全一致。
in 运算符
前面说过,直接访问某个类不存在的私有属性会报错,但是访问不存在的公开属性不会报错。这个特性可以用来判断,某个对象是否为类的实例。
1 | class C { |
上面示例中,类C的静态方法isC()就用来判断,某个对象是否为C的实例。它采用的方法就是,访问该对象的私有属性#brand。如果不报错,就会返回true;如果报错,就说明该对象不是当前类的实例,从而catch部分返回false。
因此,try...catch结构可以用来判断某个私有属性是否存在。但是,这样的写法很麻烦,代码可读性很差,ES2022 改进了in运算符,使它也可以用来判断私有属性。
1 | class C { |
上面示例中,in运算符判断某个对象是否有私有属性#brand。它不会报错,而是返回一个布尔值。
这种用法的in,也可以跟this一起配合使用。
1 | class A { |
注意,判断私有属性时,in只能用在类的内部。另外,判断所针对的私有属性,一定要先声明,否则会报错。
1 | class A { |
上面示例中,私有属性#foo没有声明,就直接用于in运算符的判断,导致报错。
子类从父类继承的私有属性,也可以使用in运算符来判断。
1 | class A { |
上面示例中,SubA从父类继承了私有属性#foo,in运算符也有效。
注意,in运算符对于Object.create()、Object.setPrototypeOf形成的继承,是无效的,因为这种继承不会传递私有属性。
1 | class A { |
上面示例中,对于修改原型链形成的继承,子类都取不到父类的私有属性,所以in运算符无效。
new.target属性
new是从构造函数生成实例的命令。
ES6为new命令引入了一个new.target属性,(在构造函数中)返回new命令作用于的那个构造函数。如果构造函数不是通过new命令调用的,new.target会返回undefined,因此这个属性可以用来确定构造函数是怎么调用的。
1 | class A { |
1 | // 另一种写法 |
上面代码确保构造函数只能通过new命令调用。
需要注意的是,子类继承父类时,new.target会返回子类。
1 | class Rectangle { |
利用这个特点,可以写出不能独立使用、必须继承后才能使用的类。
1 | class Shape { |
Class的继承
Class之间可以通过extends关键字实现继承,让子类继承父类的属性和方法。除了私有属性,实例属性,父类的所有属性和方法,都会被子类继承,其中包括静态方法。这比ES5的通过修改原型链实现继承,要清晰和方便很多。
1 | class parent { |
上面代码中,constructor方法和toString方法之中,都出现了super关键字
- constructor表示函数:super它在这里表示调用父类的构造函数
- toString表示父类对象
1 | class A { |
上面代码中,虽然super代表的是父类的构造函数,但它内部的this指向的是当前子类的构造函数
子类必须在constructor方法中调用super方法,否则新建实例时会报错。这是因为子类没有自己的this对象,而是继承父类的this对象,然后对其进行加工。如果不调用super方法,子类就得不到this对象。
ES5 的继承机制,是先创造一个独立的子类的实例对象,然后再将父类的属性和方法添加到这个对象上面
Parent.apply(this),即“实例在前,继承在后”。ES6 的继承机制,调用
super()的作用是形成子类的this对象。super方法先初始化父类,子类实例继承父类,把父类的实例属性和方法放到子类的
this对象上面。子类在调用super()之前,是没有this对象的,任何对this的操作都要放在super()的后面。注意,这意味着新建子类实例时,父类的构造函数必定会先运行一次。
1 | class Animal { |
如果子类没有定义constructor方法,这个方法会被默认添加,代码如下。也就是说,不管有没有显式定义,任何一个子类都有constructor方法。
1 | constructor(...args) { |
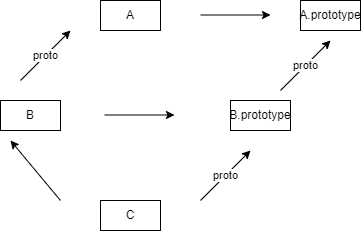
prototype和proto
大多数浏览器的ES5实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。
(1)子类的__proto__属性,表示构造函数的继承,总是指向父类。
(2)子类prototype属性的__proto__属性,表示方法的继承,总是指向父类的prototype属性。
1 | class A { |
getPrototypeOf
Object.getPrototypeOf()方法可以用来从子类上获取父类。
1 | class Point { /*...*/ } |
因此,可以使用这个方法判断,一个类是否继承了另一个类。
Mixin模式的实现
Mixin 指的是多个对象合成一个新的对象,新对象具有各个组成成员的接口。它的最简单实现如下。
1 | const a = { |
上面代码中,c对象是a对象和b对象的合成,具有两者的接口。
下面是一个更完备的实现,将多个类的接口“混入”(mix in)另一个类。
1 | function mix(...mixins) { |
上面代码的mix函数,可以将多个对象合成为一个类。使用的时候,只要继承这个类即可。
1 | class DistributedEdit extends mix(Loggable, Serializable) { |
特性
- 不存在变量提升
- 类的所有实例共享一个原型对象(_proto_)
- 类本身就指向构造函数
- 类的所有方法都定义在类的
prototype属性上面 - 类的内部所有定义的方法,都是不可枚举的
- 类没有自身属性,所有方法都定义在类的
prototype属性上面。而类创造的实例,有自身属性,这是类中constructor赋值给实例的,相当于调用了类中的constructor方法,并返回给实例对象。
修饰器(TS)
类的修饰
修饰器对类的行为的改变,是代码编译时发生的,而不是在运行时。这意味着,修饰器能在编译阶段运行代码。
1 | function testable(target) { |
上面代码中,@testable就是一个修饰器。它修改了MyTestableClass这个类的行为,为它加上了静态属性isTestable
1 | 如果觉得一个参数不够用,可以在修饰器外面再封装一层函数。 |
方法的修饰
修饰器不仅可以修饰类,还可以修饰类的属性。
1 | class Person { |
上面代码中,修饰器readonly用来修饰“类”的name方法。
此时,修饰器函数一共可以接受三个参数,第一个参数是所要修饰的目标对象,第二个参数是所要修饰的属性名,第三个参数是该属性的描述对象。
1 | function readonly(target, name, descriptor){ |
上面代码说明,修饰器(readonly)会修改属性的描述对象(descriptor),然后被修改的描述对象再用来定义属性。
为什么修饰器不能用于函数?
修饰器只能用于类和类的方法,不能用于函数,因为存在函数提升。
1 | var counter = 0; |
上面的代码,意图是执行后counter等于1,但是实际上结果是counter等于0。因为函数提升,使得实际执行的代码是下面这样。
1 | var counter; |
Mixin
在修饰器的基础上,可以实现Mixin模式。所谓Mixin模式,就是对象继承的一种替代方案,中文译为“混入”(mix in),意为在一个对象之中混入另外一个对象的方法。
1 | const Foo = { |
上面代码之中,对象Foo有一个foo方法,通过Object.assign方法,可以将foo方法“混入”MyClass类,导致MyClass的实例obj对象都具有foo方法。这就是“混入”模式的一个简单实现。
下面,我们部署一个通用脚本mixins.js,将mixin写成一个修饰器。
1 | export function mixins(...list) { |
然后,就可以使用上面这个修饰器,为类“混入”各种方法。
1 | import { mixins } from './mixins'; |
通过mixins这个修饰器,实现了在MyClass类上面“混入”Foo对象的foo方法。
第三方模块
core-decorators.js是一个第三方模块,提供了几个常见的修饰器,通过它可以更好地理解修饰器。
Babel转码器的支持
目前,Babel转码器已经支持Decorator。
首先,安装babel-core和babel-plugin-transform-decorators。由于后者包括在babel-preset-stage-0之中,所以改为安装babel-preset-stage-0亦可。
1 | $ npm install babel-core babel-plugin-transform-decorators |
然后,设置配置文件.babelrc。
1 | { |
这时,Babel就可以对Decorator转码了。
脚本中打开的命令如下。
1 | babel.transform("code", {plugins: ["transform-decorators"]}) |
Babel的官方网站提供一个在线转码器,只要勾选Experimental,就能支持Decorator的在线转码。
异步
背景
js语言执行环境是单线程
JavaScript 之所以采用单线程,而不是多线程,跟历史有关系。JavaScript 从诞生起就是单线程,原因是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果,对于一种网页脚本语言来说,这就太复杂了。如果 JavaScript 同时有两个线程,一个线程在网页 DOM 节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
这种模式的好处是实现起来比较简单,执行环境相对单纯;坏处是只要有一个任务耗时很长,后面的任务都必须排队等着,会拖延整个程序的执行。常见的浏览器无响应(假死),往往就是因为某一段 JavaScript 代码长时间运行(比如死循环),导致整个页面卡在这个地方,其他任务无法执行。JavaScript 语言本身并不慢,慢的是读写外部数据,比如等待 Ajax 请求返回结果。这个时候,如果对方服务器迟迟没有响应,或者网络不通畅,就会导致脚本的长时间停滞。
如果排队是因为计算量大,CPU 忙不过来,倒也算了,但是很多时候 CPU 是闲着的,因为 IO 操作(输入输出)很慢(比如 Ajax 操作从网络读取数据),不得不等着结果出来,再往下执行。JavaScript 语言的设计者意识到,这时 CPU 完全可以不管 IO 操作,挂起处于等待中的任务,先运行排在后面的任务。等到 IO 操作返回了结果,再回过头,把挂起的任务继续执行下去。这种机制就是 JavaScript 内部采用的“事件循环”机制(Event Loop)
回调函数
回调函数就是一个参数,将这个函数作为参数传到另一个函数里面,当主函数执行完之后,再执行传进去的这个函数。这个过程就叫做回调。回调,回调,就是回头调用的意思。
1 | function f1(callback){ |
但是回调函数有一个致命的弱点,就是容易写出回调地狱(Callback hell)。假设多个请求存在依赖性,你可能就会写出如下代码:
1 | ajax(url, () => { |
回调函数的优点是简单、容易理解和实现,缺点是不利于代码的阅读和维护,各个部分之间高度耦合,使得程序结构混乱、流程难以追踪(尤其是多个回调函数嵌套的情况),而且每个任务只能指定一个回调函数。此外它不能使用 try catch 捕获错误,不能直接 return。
事件监听
这种方式下,异步任务的执行不取决于代码的顺序,而取决于某个事件是否发生。
监听函数:on,bind,listen,addEventListener
监听方法:onclick…
发布/订阅
事件完全可以理解成“信号”,如果存在一个“信号中心”,某个任务执行完成,就向信号中心“发布”(publish)一个信号,其他任务可以向信号中心“订阅”(subscribe)这个信号,从而知道什么时候自己可以开始执行。这就叫做”发布/订阅模式”(publish-subscribe pattern),又称“观察者模式”(observer pattern)。
首先,f2向信号中心jQuery订阅done信号。
1 | jQuery.subscribe('done', f2); |
然后,f1进行如下改写。
1 | function f1() { |
上面代码中,jQuery.publish('done')的意思是,f1执行完成后,向信号中心jQuery发布done信号,从而引发f2的执行。
f2完成执行后,可以取消订阅(unsubscribe)。
1 | jQuery.unsubscribe('done', f2); |
这种方法的性质与“事件监听”类似,但是明显优于后者。因为可以通过查看“消息中心”,了解存在多少信号、每个信号有多少订阅者,从而监控程序的运行。
promise
概念
状态
一共有三种状态,分别为
pending(进行中)、fulfilled(已成功)和rejected(已失败)。特点
只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态
一旦状态改变,就不会在变。状态改变的过程只可能是:从
pending变为fulfilled和从pending变为rejected。如果状态发生上述变化后,此时状态就不会在改变了,这时就称为
resolved(已定型)为了行文方便,本章后面的
resolved统一只指fulfilled状态,不包含rejected状态。
优点: 可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数
缺点: 无法取消
Promise其次,如果没有使用catch()方法指定错误处理的回调函数,Promise内部抛出的错误,不会反应到外部。 Promise 内部的错误不会影响到 Promise 外部的代码,通俗的说法就是“Promise 会吃掉错误”。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const someAsyncThing = function () {
return new Promise(function (resolve, reject) {
// 下面一行会报错,因为x没有声明
throw new Error("x 必须为正数");
});
};
try {
someAsyncThing()
.then(function () {
console.log("everything is great");
})
.catch((err) => {
console.log(err);
});
} catch (error) {
setTimeout(() => {
console.log(123);
}, 3000);
}
基本用法
Promise对象是一个构造函数,用来生成Promise实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14const promise = new Promise(function(resolve, reject) {
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);//在异步操作失败时调用,并将异步操作报出的错误,作为参数传递出去
}
});
//Promise实例生成以后,可以用then方法分别指定resolved状态和rejected状态的回调函数。第二个函数是可选的,不一定要提供。
promise.then(function(value) {
// success
}, function(error) {
// failure
});Promise对象实现的 Ajax 操作的例子。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26const getJSON = function(url) {
const promise = new Promise(function(resolve, reject){
const handler = function() {
if (this.readyState !== 4) {
return;
}
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
const client = new XMLHttpRequest();
client.open("GET", url);
client.onreadystatechange = handler;
client.responseType = "json";
client.setRequestHeader("Accept", "application/json");
client.send();
});
return promise;
};
getJSON("/posts.json").then(function(json) {
console.log('Contents: ' + json);
}, function(error) {
console.error('出错了', error);
});调用
resolve函数和reject函数时带有参数,参数是另一个Promise对象1
2
3
4
5
6
7
8const p1 = new Promise(function (resolve, reject) {
// ...
});
const p2 = new Promise(function (resolve, reject) {
// ...
resolve(p1);
})注意,这时
p1的状态就会传递给p2,也就是说,p1的状态决定了p2的状态。如果p1的状态是pending,那么p2的回调函数就会等待p1的状态改变;如果p1的状态已经是resolved或者rejected,那么p2的回调函数将会立刻执行。1
2
3
4
5
6
7
8
9
10
11
12const p1 = new Promise(function (resolve, reject) {
setTimeout(() => reject(new Error('fail')), 3000)
})
const p2 = new Promise(function (resolve, reject) {
setTimeout(() => resolve(p1), 1000)
})
p2
.then(result => console.log('result', result))
.catch(error => console.log('error', error))
// error [Error: fail]上面代码中,
p1是一个 Promise,3 秒之后变为rejected。p2的状态在 1 秒之后改变,resolve方法返回的是p1。由于p2返回的是另一个 Promise,导致p2自己的状态无效了,由p1的状态决定p2的状态。所以,后面的then语句都变成针对后者(p1)。又过了 2 秒,p1变为rejected,导致触发catch方法指定的回调函数。调用
resolve或reject并不会终结 Promise 的参数函数的执行。1
2
3
4
5
6
7
8new Promise((resolve, reject) => {
resolve(1);
console.log(2);
}).then(r => {
console.log(r);
});
// 2
// 1上面代码中,调用
resolve(1)以后,后面的console.log(2)还是会执行,并且会首先打印出来。这是因为立即 resolved 的 Promise 是在本轮事件循环的末尾执行,总是晚于本轮循环的同步任务。一般来说,调用
resolve或reject以后,Promise 的使命就完成了,后继操作应该放到then方法里面,而不应该直接写在resolve或reject的后面。所以,最好在它们前面加上return语句,这样就不会有意外。
API
then
它的作用是为 Promise 实例添加状态改变时的回调函数。
Promise.prototype.then()方法返回的是一个新的Promise实例(注意,不是原来那个Promise实例)。因此可以采用链式写法,即then方法后面再调用另一个then方法。
1 | new Promise((resolved) => { |
上面代码中,第一个then方法指定的回调函数,返回的是另一个Promise对象。这时,第二个then方法指定的回调函数,就会等待这个新的Promise对象状态发生变化。如果变为resolved,就调用第一个回调函数,如果状态变为rejected,就调用第二个回调函数。
catch
Promise.prototype.catch方法是.then(null, rejection)的别名,用于指定发生错误时的回调函数。
1 | getJSON('/posts.json').then(function(posts) { |
getJSON()方法返回一个 Promise 对象,如果该对象状态变为resolved,则会调用then()方法指定的回调函数;如果异步操作抛出错误,状态就会变为rejected,就会调用catch()方法指定的回调函数,处理这个错误。另外,**then()方法指定的回调函数**,如果运行中抛出错误,也会被catch()方法捕获。
1 | var promise = new Promise(function(resolve, reject) { |
如果Promise状态已经变成Resolved,再抛出错误是无效的。
1 | var promise = new Promise(function(resolve, reject) { |
一般来说,不要在then方法里面定义Reject状态的回调函数(即then的第二个参数),总是使用catch方法。理由是catch可以捕获前面then方法执行中的错误,也更接近同步的写法(try/catch)。因此,建议总是使用catch方法,而不使用then方法的第二个参数。
1 | // bad |
catch()方法返回的还是一个 Promise 对象,因此后面还可以接着调用then()方法。
1 | const someAsyncThing = function() { |
all
Promise.prototype.all()方法用于将多个 Promise 实例,包装成一个新的 Promise 实例。
1 | const p = Promise.all([p1, p2, p3]); |
Promise.all()方法接受一个数组作为参数,p1、p2、p3都是 Promise 实例,如果不是,就会先调用下面讲到的Promise.resolve方法,将参数转为 Promise 实例,再进一步处理。另外,Promise.all()方法的参数可以不是数组,但必须具有 Iterator 接口,且返回的每个成员都是 Promise 实例。
p的状态由p1、p2、p3决定,分成两种情况。
(1)只有p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。
(2)只要p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
1 | const p1 = new Promise((resolve, reject) => { |
上面代码中,p1会resolved,p2首先会rejected,但是p2有自己的catch方法,该方法返回的是一个新的 Promise 实例,p2指向的实际上是这个实例。该实例执行完catch方法后,也会变成resolved,导致Promise.all()方法参数里面的两个实例都会resolved,因此会调用then方法指定的回调函数,而不会调用catch方法指定的回调函数。
如果p2没有自己的catch方法,就会调用Promise.all(
race/any
Promise.race方法同样是将多个Promise实例,包装成一个新的Promise实例。
1 | var p = Promise.race([p1, p2, p3]); |
上面代码中,只要p1、p2、p3之中有一个实例率先改变状态,p的状态就跟着改变。那个率先改变的 Promise 实例的返回值,就传递给p的回调函数。
Promise.race方法的参数与Promise.all方法一样,如果不是 Promise 实例,就会先调用下面讲到的Promise.resolve方法,将参数转为 Promise 实例,再进一步处理。
下面是一个例子,如果指定时间内没有获得结果,就将Promise的状态变为reject,否则变为resolve。
1 | var p = Promise.race([ |
上面代码中,如果5秒之内fetch方法无法返回结果,变量p的状态就会变为rejected,从而触发catch方法指定的回调函数。
any参数实例只要有一个变成fulfilled状态,包装实例就会变成fulfilled状态;如果所有参数实例都变成rejected状态,包装实例就会变成rejected状态。
Promise.any()跟Promise.race()方法很像,只有一点不同,就是Promise.any()不会因为某个 Promise 变成rejected状态而结束,必须等到所有参数 Promise 变成rejected状态才会结束。
finally
finally()方法用于指定不管 Promise 对象最后状态如何,都会执行的操作。 finally方法的回调函数不接受任何参数,这意味着没有办法知道,前面的 Promise 状态到底是fulfilled还是rejected。
1 | promise |
在执行完then或catch指定的回调函数以后,都会执行finally方法指定的回调函数。
resolve
有时需要将现有对象转为Promise对象,Promise.resolve方法就起到这个作用。
(1)参数是一个Promise实例
如果参数是Promise实例,那么Promise.resolve将不做任何修改、原封不动地返回这个实例。
(3)参数不是一个Promise实例
如果参数是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为Resolved。
1 | var p = Promise.resolve('Hello'); |
(4)不带有任何参数
Promise.resolve方法允许调用时不带参数,直接返回一个Resolved状态的Promise对象。
所以,如果希望得到一个Promise对象,比较方便的方法就是直接调用Promise.resolve方法。
1 | var p = Promise.resolve(); |
上面代码的变量p就是一个Promise对象。
需要注意的是,立即resolve的Promise对象,是在本轮“事件循环”(event loop)的结束时,而不是在下一轮“事件循环”的开始时。
1 | setTimeout(function () { |
1 | Promise.resolve(() => { |
reject
Promise.reject(reason)方法也会返回一个新的Promise实例,该实例的状态为rejected。它的参数用法与Promise.resolve方法完全一致。
1 | var p = Promise.reject('出错了'); |
上面代码生成一个Promise对象的实例p,状态为rejected,回调函数会立即执行。
Promise.reject()方法的参数,会原封不动地作为reject的理由,变成后续方法的参数。
1 | Promise.reject('出错了') |
上面代码中,Promise.reject()方法的参数是一个字符串,后面catch()方法的参数e就是这个字符串。
源码
https://zhuanlan.zhihu.com/p/76811638
代码
1 | const a = new Promise((resolve, reject) => { |
- 返回新的promise,那么下一级.then()会在新的promise状态改变之后执行
- 没有return,相当于return Promise.resolve(undefined);
- return非Promise的数据data,相当于return Promise.resolve(data);
1 | let a = new Promise((resolve, reject) => { |
1 | new Promise((resolved,reject)=>{ |
1 | new Promise((resolved, reject) => { |
async
Generator
async含义
定义:使异步函数以同步函数的形式书写(Generator函数语法糖)
原理:将Generator函数和自动执行器spawn包装在一个函数里
形式:将Generator函数的*替换成async,将yield替换成await
1 | const fs = require('fs'); |
上面代码的函数gen可以写成async函数,就是下面这样。
1 | const asyncReadFile = async function () { |
一比较就会发现,async函数就是将 Generator 函数的星号(*)替换成async,将yield替换成await,仅此而已。
async函数对 Generator 函数的改进,体现在以下四点。
(1)内置执行器
Generator 函数的执行必须靠执行器,所以才有了co模块,而async函数自带执行器。也就是说,async函数的执行,与普通函数一模一样,只要一行。 不像 Generator 函数,需要调用next方法,或者用co模块,才能真正执行
(2)更好的语义
async和await,比起星号和yield,语义更清楚了。
(3)更广的适用性。
co模块约定,yield命令后面只能是 Thunk 函数或 Promise 对象,而async函数的await命令后面,可以是 Promise 对象和原始类型的值(数值、字符串和布尔值,但这时会自动转成立即 resolved 的 Promise 对象)。
(4)返回值是 Promise
async函数的返回值是 Promise 对象,这比 Generator 函数的返回值是 Iterator 对象方便多了。你可以用then方法指定下一步的操作。 async函数内部return语句返回的值,会成为then方法回调函数的参数。
async语法
声明
- 函数:
async function Func() {} - 函数表达式:
const func = async function() {} - 箭头函数:
const func = async() => {} - 对象方法:
const obj = { async func() {} } - 类方法:
class Cla { async Func() {} }
例子
没有显式return,相当于return Promise.resolve(undefined);
1
2
3
4
5
6
7
8
9async function f() {
let a = 1
//没有return,就类似于resolved(undefined)
}
f().then(
v => console.log(v),//undefined
e => console.log(e)
)return非Promise的数据data,相当于return Promise.resolve(data);
async函数内部return语句返回的值,会成为then方法回调函数的参数。如果在函数中return一个直接量,async 会把这个直接量通过Promise.resolve()封装成 Promise 对象。1
2
3
4
5
6async function f() {
return 'hello world';
}
f().then(v => console.log(v))
// "hello world"async函数返回一个Promise对象。return Promise, 会得到Promise对象本身。
async函数返回的Promise对象,必须等到内部所有await命令的Promise对象执行完,才会发生状态改变。也就是说,只有async函数内部的异步操作执行完,才会执行then方法指定的回调函数。返回rejected
async函数内部抛出错误,会导致返回的Promise对象变为reject状态。抛出的错误对象会被catch方法回调函数接收到。只要一个await语句后面的Promise变为reject,那么整个async函数都会中断执行。1
2
3
4
5
6
7
8
9
10
11async function f() {
throw new Error('出错了');
//await Promise.reject('出错了');
await Promise.resolve('hello world'); // 不会执行
}
f().then(
v => console.log(v),
e => console.log(e)
)
// Error: 出错了为了避免这个问题,可以将第一个
await放在try...catch结构里面,这样第二个await就会执行。
错误处理
如果await后面的异步操作出错,那么等同于async函数返回的 Promise 对象被reject。且下面的代码不会被执行
1 | async function f() { |
为了防止状态变为rejected,中断后面的异步操作,将报错代码放在try...catch代码块之中。
1 | async function f() { |
另一种方法是await后面的Promise对象再跟一个catch方面,处理前面可能出现的错误。
1 | async function f() { |
优化
多个
await命令后面的异步操作,如果不存在继发关系,最好让它们同时触发。1
2let foo = await getFoo();
let bar = await getBar();上面代码中,
getFoo和getBar是两个独立的异步操作(即互不依赖),被写成继发关系。这样比较耗时,因为只有getFoo完成以后,才会执行getBar,完全可以让它们同时触发。1
2
3
4
5
6
7
8// 写法一
let [foo, bar] = await Promise.all([getFoo(), getBar()]);
// 写法二
let fooPromise = getFoo();
let barPromise = getBar();
let foo = await fooPromise;
let bar = await barPromise;
代码
1 | const fn = async () => { |
symbol
JavaScript 的 Symbol 类型是一种原始数据类型,可以用来表示独一无二的值。
Symbol 类型的主要用途是创建对象的唯一属性名,因此可以用来防止属性名冲突,保证属性名的独特性。例如:
1 | const id = Symbol(); |
还可以用来做为私有属性,因为 Symbol 类型的值是不能被枚举的(即不能被 Object.keys()、Object.getOwnPropertyNames() 和 for
set和map
https://juejin.cn/post/70800667426422784
Set
简介
Set是ES6新增的数据结构,类似于数组,但它的一大特性就是所有元素都是唯一的,没有重复的值,我们一般称为集合。Set是一个构造函数,用来生成set的数据结构。
set打印出来的数据结构,是一个对象
1 | var set=new Set([1,2,3]) |
常用语法
要创建一个Set,需要提供一个Array作为输入,或者直接创建一个空Set
1 | //初始化一个Set ,需要一个Array数组,要么空Set |
用途
最常用来数组去重,去重方法有很多但是都没有它运行的快
1 | var arr = [2, 3, 5, 3, 5, 2]; |
字符串去重
1 | var str = "2234332244"; |
实现并集、交集、差集
1 | let a = new Set([1, 2, 3]), |
遍历方法
Set结构的实例有四个遍历方法,可用于遍历成员。
keys(), values(), entries()返回的都是遍历器对象。
Set结构没有键名,只有键值,所以keys()和values()方法的行为完全一致
keys():返回键名的遍历器
values():返回键值的遍历器
entries():返回键值对的遍历器
forEach():使用回调函数遍历每个成员
1 | var list = new Set(["a", 1, 2, 3]); |
Map
简介
JS的对象有个小问题,就是键必须是字符串。但实际上Number或者其他数据类型作为键也是非常合理的。为了解决这个问题,最新的ES6规范引入了新的数据类型Map。
Map类似于对象,数据结构是一个键值对的结构,但是“键”的范围不限制于字符串,各种类型的值(包含对象)都可以当作键。
Map 也可以接受一个数组作为参数,数组的成员是一个个表示键值对的数组。注意Map里面也不可以放重复的项。
常用语法
一个key只能对应一个value,多次对一个key放入value,后面的值会把前面的值覆盖掉;
初始化Map需要一个二维数组,或者直接初始化一个空Map
1 | //初始化`Map`需要一个二维数组(请看 Map 数据结构),或者直接初始化一个空`Map` |
区别
map和set一样是关联式容器,它们的底层容器都是红黑树
两种方法具有极快的查找速度
Map 和 Set 都不允许键重复
初始化需要值不一样,Map需要的是一个二维数组,而Set 需要的是一维 Array 数组
Map 是键值对的存在,键和值是分开的;Set 没有 value 只有 key,value 就是 key;
Proxy 和 Reflect
https://mp.weixin.qq.com/s/Ez2Cf6w4SwX1HOjnE1wl6g
defineProperty&Proxy区别
https://blog.csdn.net/qq_38290251/article/details/135280017
Vue3摒弃了传统的Object.defineProperty,转而使用Proxy来代替响应式,使用前者来完成劫持对象的属性时,不仅需要对每个涉及响应式的对象(以及该对象中的每个属性进行遍历,且如果属性值是对象,还需要深度遍历),而如果是对数组进行响应式,那这就又是另外一个头疼的话题了,但这一切的一切都可以使用“天生不凡”的 Proxy 来避免
一、Object.defineProperty()
文档:Object.defineProperty() - JavaScript | MDN
作用:对一个对象进行操作的方法。可以为一个对象增加一个属性,同时也可以对一个属性进行修改和删除。
它是在 ES5 中引入的,使用了 getter 和 setter 方法来实现 Vue2 的响应式。
1、劣势
Object.defineProperty() 的问题主要有三个:
不能监听数组的变化
无法监控到数组下标的变化,导致通过数组下标添加元素,不能实时响应
必须遍历对象的每个属性
只能劫持对象的属性,从而需要对每个对象,每个属性进行遍历。
如果属性值是对象,还需要深度遍历。Proxy 可以劫持整个对象,并返回一个新的对象
必须深层遍历嵌套的对象
2、优势
兼容性好,支持 IE9
而 Proxy 的存在浏览器兼容性问题,而且无法用 polyfill 磨平
3、代码
Object.defineProperty(obj, prop, descriptor);
// obj 要定义属性的对象
// prop 要定义或修改的属性的名称
// descriptor 要定义或修改的属性描述符
Object.defineProperty(obj, "name", {
value: "小草莓", // 初始值
writable: true, // 该属性是否可写入
enumerable: true, // 该属性是否可被遍历得到(for...in, Object.keys等)
configurable: true, // 定该属性是否可被删除,且除writable外的其他描述符是否可被修改
get: function () {},
set: function (newVal) {},
});
二、proxy
1、对 Proxy 的理解
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。
Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
ES6 入门教程
var obj = new Proxy({}, {
get: function (target, propKey, receiver) {
console.log(getting ${propKey}!);
return Reflect.get(target, propKey, receiver);
},
set: function (target, propKey, value, receiver) {
console.log(setting ${propKey}!);
return Reflect.set(target, propKey, value, receiver);
}
});
obj.count = 1
// setting count!
++obj.count
// getting count!
// setting count!
// 2
上面代码对一个空对象架设了一层拦截,重定义了属性的读取(get)和设置(set)行为。
2、语法
ES6 原生提供 Proxy 构造函数,用来生成 Proxy 实例
var proxy = new Proxy(target, handler);
第一个参数:target参数表示所要拦截的目标对象
第二个参数:handler参数也是一个对象,用来定制拦截行为。 它是一个配置对象,对于每一个被代理的操作,需要提供一个对应的处理函数,该函数将拦截对应的操作。
Proxy 对象可以拦截目标对象的任意属性,这使得它很合适用来写 Web 服务的客户端。
3、Proxy的优势
针对对象
针对整个对象,而不是对象的某个属性 ,所以也就不需要对 keys 进行遍历
支持数组
Proxy 不需要对数组的方法进行重载,省去了众多 hack,减少代码量等于减少了维护成本,而且标准的就是最好的
Proxy的第二个参数可以有 13 种拦截方法
不限于apply、ownKeys、deleteProperty、has等等,是Object.defineProperty不具备的
Proxy返回的是一个新对象
我们可以只操作新的对象达到目的。而Object.defineProperty只能遍历对象属性直接修改
Proxy作为新标准将受到浏览器厂商重点持续的性能优化
也就是传说中的新标准的性能红利
4、使用 proxy 创建一个响应式对象
import { isObject } from “./util”; // 工具方法
// 创建一个响应式对象
export function reactive(target) {
// 根据不同参数创建不同响应式对象
return createReactiveObject(target, mutableHandlers);
}
// 根据不同参数创建不同响应式对象
function createReactiveObject(target, baseHandler) {
if (!isObject(target)) {
return target;
}
const observed = new Proxy(target, baseHandler);
return observed;
}
const get = createGetter();
const set = createSetter();
function createGetter() {
return function get(target, key, receiver) {
// 对获取的值进行放射
const res = Reflect.get(target, key, receiver);
console.log("属性获取", key);
if (isObject(res)) {
// 如果获取的值是对象类型,则返回当前对象的代理对象
return reactive(res);
}
return res;
};
}
function createSetter() {
return function set(target, key, value, receiver) {
const oldValue = target[key];
const hadKey = hasOwn(target, key);
const result = Reflect.set(target, key, value, receiver);
if (!hadKey) {
console.log("属性新增", key, value);
} else if (hasChanged(value, oldValue)) {
console.log("属性值被修改", key, value);
}
return result;
};
}
export const mutableHandlers = {
get, // 当获取属性时调用此方法
set // 当修改属性时调用此方法
};
三、问题
1、Proxy只会代理对象的第一层,那么 Vue3 又是怎样处理这个问题的呢?
判断当前 Reflect.get 的返回值是否为 Object ,如果是则再通过 reactive 方法做代理, 这样就实现了深度观测。
2、监测数组的时候可能触发多次get/set,那么如何防止触发多次呢?
我们可以判断 key 是否为当前被代理对象 target 自身属性,也可以判断旧值与新值是否相等,只有满足以上两个条件之一时,才有可能执行 trigger
四、Vue3.0 里为什么要用 Proxy 替代 defineProperty ?
主要是从性能方面考量
defineProperty:该 API 存在一些局限性,比如对于数组的拦截有问题,为此 Vue 需要专门为数组响应式做一套实现。另外不能拦截那些新增、删除属性。最后 defineProperty 方案在初始化时需要深度递归遍历待处理的对象才能对它进行完全拦截,明显增加了初始化的时间。
以上两点在 Proxy 出现之后迎刃而解。
Proxy:不仅可以对数组实现拦截,还能对 Map、Set 实现拦截。另外 Proxy 的拦截也是懒处理行为。如果用户没有访问嵌套对象,那么也不会实施拦截,这就让初始化的速度和内存占用都改善了。
Vue的代理也是最开始只代理最外层的对象,在访问的时候去判断是否为一个 object,然后再去用 proxy 包裹
当然 Proxy 是有兼容性问题的,IE 完全不支持,所以如果需要 IE 兼容就不合适
五、底层拦截原理
六、Proxy 和 Object.defineProperty 的区别?
Vue2 和 Vue3 响应式上有什么区别? / 使用 Object.defineProperty() 来进行数据劫持有什么缺点?_vue 2响应式和vue 3响应式区别-CSDN博客
都可以用来实现 JavaScript 对象的响应式,但是它们有一些区别:
① 实现方式
Proxy 是 ES6 新增的一种特性,使用了一种代理机制来实现响应式。
Object.defineProperty 是在 ES5 中引入的,使用了 getter 和 setter 方法来实现。
② 作用对象
Proxy 可以代理整个对象,包括对象的所有属性、数组的所有元素以及类似数组对象的所有元素。
Object.defineProperty 只能代理对象上定义的属性。
③ 监听属性
Proxy 可以监听到新增属性和删除属性的操作
Object.defineProperty 只能监听到已经定义的属性的变化。
④ 性能
由于 Proxy 是 ES6 新增特性,其内部实现采用了更加高效的算法,相对于 Object.defineProperty来说在性能方面有一定的优势。
综上所述,虽然 Object.defineProperty 在 Vue.js 2.x 中用来实现响应式,但是在 Vue.js 3.0 中已经采用了 Proxy 来替代。
这是因为 Proxy 相对于 Object.defineProperty 拥有更优异的性能和更强大的能力。
概念
Proxy代理,它内置了一系列”陷阱“用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等)
Reflect反射,它提供拦截 JavaScript 操作的方法。
将
Object对象的一些明显属于语言内部的方法(比如Object.defineProperty),放到Reflect对象上修改某些
Object方法的返回结果,让其变得更合理。比如,Object.defineProperty(obj, name, desc)在无法定义属性时,会抛出一个错误,而Reflect.defineProperty(obj, name, desc)则会返回false。1
2
3
4
5
6
7
8
9
10
11
12
13
14// 老写法
try {
Object.defineProperty(target, property, attributes);
// success
} catch (e) {
// failure
}
// 新写法
if (Reflect.defineProperty(target, property, attributes)) {
// success
} else {
// failure
}让
Object操作都变成函数行为。某些Object操作是命令式,比如name in obj和delete obj[name],而Reflect.has(obj, name)和Reflect.deleteProperty(obj, name)让它们变成了函数行为Reflect对象的方法与Proxy对象的方法一一对应,只要是Proxy对象的方法,就能在Reflect对象上找到对应的方法。这就让Proxy对象可以方便地调用对应的Reflect方法,完成默认行为,作为修改行为的基础。Proxy可以捕获13种不同的基本操作,这些操作有各自不同的Reflect API方法。
1
2
3
4
5
6
7
8
9Proxy(target, {
set: function(target, name, value, receiver) {
var success = Reflect.set(target,name, value, receiver);
if (success) {
log('property ' + name + ' on ' + target + ' set to ' + value);
}
return success;
}
});上面代码中,
Proxy方法拦截target对象的属性赋值行为。它采用Reflect.set方法将值赋值给对象的属性,然后再部署额外的功能。
简单来说,我们可以通过 Proxy 创建对于原始对象的代理对象,从而在代理对象中使用 Reflect 达到对于 JavaScript 原始操作的拦截。
Proxy代理
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程” (meta programming),即对编程语言进行编程。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。Proxy 这个词的原意是代理,用在这里表示由它来“代理”某些操作,可以译为“代理器”。
ES6 原生提供 Proxy 构造函数,用来生成 Proxy 实例。new Proxy()表示生成一个Proxy实例,target参数表示所要拦截的目标对象,handler参数也是一个对象,用来定制拦截行为。
1 | var proxy = new Proxy(target, handler); |
下面代码对一个空对象架设了一层拦截,重定义了属性的读取(get)和设置(set)行为。对设置了拦截行为的对象obj,去读写它的属性,就会得到下面的结果。
1 | var obj = new Proxy({}, { |
下面是另一个拦截读取属性行为的例子。
1 | var proxy = new Proxy({}, { |
如果handler没有设置任何拦截,那就等同于直接通向原对象。
1 | var target = {}; |
Proxy 实例也可以作为其他对象的原型对象。
1 | var proxy = new Proxy({}, { |
上面代码中,proxy对象是obj对象的原型,obj对象本身并没有time属性,所以根据原型链,会在proxy对象上读取该属性,导致被拦截。
Reflect映射对象
Reflect对象与Proxy对象一样,也是ES6为了操作对象而提供的新API。
Proxy 中的 target
代理对象
1
2
3
4
5
6
7
8
9
10
11
12const obj = {
name: 'wang.haoyu',
};
const proxy = new Proxy(obj, {
get(target, key, receiver) {
console.log(target === obj);//true
return target[key];
},
});
proxy.name;继承代理对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25const parent = {
get value() {
return '19Qingfeng';
},
};
const proxy = new Proxy(parent, {
// get陷阱中target表示原对象 key表示访问的属性名
get(target, key, receiver) {
console.log(target === parent) // log:true
console.log(target === proxy) // log:false
console.log(target === obj) // log:false
return target[key];
},
});
const obj = {
name: 'wang.haoyu',
};
// 设置obj继承与parent的代理对象proxy
Object.setPrototypeOf(obj, proxy);
obj.value
Proxy 中的 receiver
receiver指向调用者
代理对象
1
2
3
4
5
6
7
8
9
10
11
12const obj = {
name: 'wang.haoyu',
};
const proxy = new Proxy(obj, {
get(target, key, receiver) {
console.log(receiver === proxy);//true
return target[key];
},
});
proxy.name;继承代理对象
receiver传递正确的调用者指向
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23const parent = {
get value() {
return '19Qingfeng';
},
};
const proxy = new Proxy(parent, {
get(target, key, receiver) {
- console.log(receiver === proxy) // log:false
+ console.log(receiver === obj) // log:true
return target[key];
},
});
const obj = {
name: 'wang.haoyu',
};
// 设置obj继承与parent的代理对象proxy
Object.setPrototypeOf(obj, proxy);
obj.value
receiver 不仅仅代表的是 Proxy 代理对象本身,同时也许他会代表继承 Proxy 的那个对象。其实本质上来说它还是为了确保陷阱函数中调用者的正确的上下文访问,谁调用就指向的谁
receiver可以修改属性访问中的 this 指向为传入的 receiver 对象。
1 | const parent = { |
1 | const parent = { |
为什么Proxy一定要配合Reflect使用?要保证正确的 this 上下文指向。
get 陷阱中第三个参数传递了 Proxy 中的 receiver 也就是 obj 作为形参,它会作为修改调用时的 this 指向
你可以简单的将 Reflect.get(target, key, receiver) 理解成为 target[key].call(receiver),不过这是一段伪代码,但是这样你可能更好理解。
this指向
虽然 Proxy 可以代理针对目标对象的访问,但它不是目标对象的透明代理,即不做任何拦截的情况下,也无法保证与目标对象的行为一致。主要原因就是在Proxy 代理的情况下,目标对象内部的this关键字会指向 Proxy 代理。
1 | const target = { |
上面代码中,一旦proxy代理target.m,后者内部的this就是指向proxy,而不是target。
下面是一个例子,由于this指向的变化,导致 Proxy 无法代理目标对象。
1 | const _name = new WeakMap(); |
上面代码中,目标对象jane的name属性,实际保存在外部WeakMap对象_name上面,通过this键区分。由于通过proxy.name访问时,this指向proxy,导致无法取到值,所以返回undefined。
此外,有些原生对象的内部属性,只有通过正确的this才能拿到,所以 Proxy 也无法代理这些原生对象的属性。
1 | const target = new Date(); |
上面代码中,getDate方法只能在Date对象实例上面拿到,如果this不是Date对象实例就会报错。这时,**this绑定原始对象,就可以解决这个问题。**
1 | const target = new Date('2015-01-01'); |
defineProperty
如果Reflect传入receiver,那么会触发Proxy.defineProperty捕获器。
1 | const obj = { |
监听案例
在ES5中使用Object.defineProperty(对象属性描述符)对对象的监听,将一个对象进行遍历,并设定getter、setter方法进行监听和拦截。
1 | // 定义一个Object对象 |
Object.defineProperty的设计初衷并不是为了去监听拦截一个对象中的属性,且他也实现不了更加丰富的操作,例如添加、删除属性等操作。
我们将上面通过Object.defineProperty实现对象监听的方法修改成Proxy方案。在Vue3框架中的响应式原理也是用到了Proxy对象进行对属性的监听操作。
1 | const obj = { |
方法
Reflect对象的方法与Proxy对象的方法一一对应,只要是Proxy对象的方法,就能在Reflect对象上找到对应的方法。
下面是 Proxy 支持的拦截操作一览,一共 13 种。
- **get(target, propKey, receiver)**:拦截对象属性的读取,比如
proxy.foo和proxy['foo']。 - **set(target, propKey, value, receiver)**:拦截对象属性的设置,比如
proxy.foo = v或proxy['foo'] = v,返回一个布尔值。 - **has(target, propKey)**:拦截
propKey in proxy的操作,返回一个布尔值。 - **deleteProperty(target, propKey)**:拦截
delete proxy[propKey]的操作,返回一个布尔值。 - **ownKeys(target)**:拦截
Object.getOwnPropertyNames(proxy)、Object.getOwnPropertySymbols(proxy)、Object.keys(proxy)、for...in循环,返回一个数组。该方法返回目标对象所有自身的属性的属性名,而Object.keys()的返回结果仅包括目标对象自身的可遍历属性。 - **getOwnPropertyDescriptor(target, propKey)**:拦截
Object.getOwnPropertyDescriptor(proxy, propKey),返回属性的描述对象。 - **defineProperty(target, propKey, propDesc)**:拦截
Object.defineProperty(proxy, propKey, propDesc)、Object.defineProperties(proxy, propDescs),返回一个布尔值。 - **preventExtensions(target)**:拦截
Object.preventExtensions(proxy),返回一个布尔值。 - **getPrototypeOf(target)**:拦截
Object.getPrototypeOf(proxy),返回一个对象。 - **isExtensible(target)**:拦截
Object.isExtensible(proxy),返回一个布尔值。 - **setPrototypeOf(target, proto)**:拦截
Object.setPrototypeOf(proxy, proto),返回一个布尔值。如果目标对象是函数,那么还有两种额外操作可以拦截。 - **apply(target, object, args)**:拦截 Proxy 实例作为函数调用的操作,比如
proxy(...args)、proxy.call(object, ...args)、proxy.apply(...)。 - **construct(target, args)**:拦截 Proxy 实例作为构造函数调用的操作,比如
new proxy(...args)。
| 对象中的方法 | 说明 |
|---|---|
| Reflect.apply() | 对一个函数进行apply调用 |
| Reflect.construct() | 对构造函数进行new操作 |
| Reflect.defineProperty() | 定义一个属性 |
| Reflect.deleteProperty(target, propKey) | 删除一个属性 |
| Reflect.get(target, propKey, receiver) | 获取一个属性 |
| Reflect.getOwnPropertyDescriptor() | 获取一个属性描述符 |
| Reflect.getPrototypeOf() | 获取一个对象的原型 |
| Reflect.has(target, propKey) | 判断一个属性是否在对象中 |
| Reflect.isExtensible() | 判断可以扩展 |
| Reflect.ownKeys() | 获取一个对象中的key集合 |
| Reflect.preventExtensions() | 使一个对象不可扩展 |
| Reflect.set(target, propKey, value, receiver) | 设置一个属性 |
| Reflect.setPrototypeOf() | 设置一个对象的原型 |
TS
TypeScript 是一门基于 JavaScript 拓展的语言,它是 JavaScript 的超集,并且给 JavaScript 添加了静态类型检查系统。TypeScript 能让我们在开发时发现程序中类型定义不一致的地方,及时消除隐藏的风险,大大增强了代码的可读性以及可维护性。
TS和JS
编译
具体可在中查看常识文档
类型绑定
JavaScript
JavaScript 是一门解释型语言,没有编译阶段,所以它是动态类型。JavaScript动态绑定类型,只有运行程序才能知道类型,在程序运行之前JavaScript对类型一无所知
TypeScript
TypeScript是在程序运行前(也就是编译时)就会知道当前是什么类型。当然如果该变量没有定义类型,那么TypeScript会自动类型推导出来。
类型转换
JavaScript弱类型语言
比如在JavaScript中1 + true这样一个代码片段,JavaScript存在隐式转换,这时true会变成number类型number(true)和1相加。
TypeScript强类型语言
在TypeScript中,1+true这样的代码会在TypeScript中报错,提示number类型不能和boolean类型进行运算。
何时检查类型
JavaScript
在JavaScript中只有在程序运行时才能检查类型。类型也会存在隐式转换,很坑。
TypeScript
在TypeScript中,在编译时就会检查类型,如果和预期的类型不符合直接会在编辑器里报错、爆红
TS特殊符号
https://blog.csdn.net/qiwoo_weekly/article/details/108557466
?. 运算符
可选链(Optional Chaining)运算符是一种先检查属性是否存在,再尝试访问该属性的运算符
1 | a?.b; |
?:
在 TypeScript 中使用 interface 关键字就可以声明一个接口:
1 | interface Person { |
在以上代码中,我们声明了 Person 接口,它包含了两个必填的属性 name 和 age。在初始化 Person 类型变量时,如果缺少某个属性,TypeScript 编译器就会提示相应的错误信息,比如:
1 | // Property 'age' is missing in type '{ name: string; }' but required in type 'Person'.(2741) |
为了解决上述的问题,我们可以把某个属性声明为可选的:
1 | interface Person { |
!:
| 分隔符
在 TypeScript 中联合类型(Union Types)表示取值可以为多种类型中的一种,联合类型使用 | 分隔每个类型。联合类型通常与 null 或 undefined 一起使用:
1 | const sayHello = (name: string | undefined) => { /* ... */ }; |
以上示例中 name 的类型是 string | undefined 意味着可以将 string 或 undefined 的值传递给 sayHello 函数。
type
定义类型由两种方式:接口(interface)和类型别名(type alias)
interface只能定义对象类型,type声明的方式可以定义组合类型,交叉类型和原始类型
基础类型
布尔值
最基本的数据类型就是简单的true/false值,在JavaScript和TypeScript里叫做boolean(其它语言中也一样)。
1 | let isDone: boolean = false; |
数字
和JavaScript一样,TypeScript里的所有数字都是浮点数。 这些浮点数的类型是 number。 除了支持十进制和十六进制字面量,TypeScript还支持ECMAScript 2015中引入的二进制和八进制字面量。
1 | let decLiteral: number = 6;// 十进制 |
字符串
1 | let name: string = "bob"; |
你还可以使用模版字符串,它可以定义多行文本和内嵌表达式。 这种字符串是被反引号包围( ```),并且以${ expr }这种形式嵌入表达式
1 | let name: string = `Gene`; |
这与下面定义sentence的方式效果相同:
1 | let sentence: string = "Hello, my name is " + name + ".\n\n" +"I'll be " + (age + 1) + " years old next month."; |
Null 和 Undefined
null
null是一个只有一个值的特殊类型。表示一个空对象引用。在 JavaScript 中 null 表示 “什么都没有”。用 typeof 检测 null 返回是 object。
undefined
在 JavaScript 中, undefined 是一个没有设置值的变量。typeof 一个没有值的变量会返回 undefined。
与 void 的区别是,undefined 和 null 是所有类型的子类型。也就是说 undefined 类型的变量,可以赋值给 number 类型的变量:
1 | // 这样不会报错 |
而 void 类型的变量不能赋值给 number 类型的变量:
1 | let u: void; |
数组
TypeScript像JavaScript一样可以操作数组元素。 有两种方式可以定义数组。 第一种,可以在元素类型后面接上 [],表示由此类型元素组成的一个数组:
1 | let list: number[] = [1, 2, 3]; |
第二种方式是使用数组泛型,Array<元素类型>:
1 | let list: Array<number> = [1, 2, 3]; |
元组 Tuple
元组类型允许表示一个已知元素数量和类型的数组,各元素的类型不必相同。 比如,你可以定义一对值分别为 string和number类型的元组。
1 | // Declare a tuple type |
当访问一个已知索引的元素,会得到正确的类型:
1 | console.log(x[0].substr(1)); // OK |
当访问一个越界的元素,会使用联合类型替代:
1 | x[3] = 'world'; // OK, 字符串可以赋值给(string | number)类型 |
Object
object表示非原始类型,也就是除number,string,boolean,symbol,null或undefined之外的类型。
使用object类型,就可以更好的表示像Object.create这样的API。例如:
1 | declare function create(o: object | null): void; |
Any
有时候,我们会想要为那些在编程阶段还不清楚类型的变量指定一个类型。 这些值可能来自于动态的内容,比如来自用户输入或第三方代码库。 这种情况下,我们不希望类型检查器对这些值进行检查而是直接让它们通过编译阶段的检查。 那么我们可以使用 any类型来标记这些变量:
1 | let notSure: any = 4; |
在对现有代码进行改写的时候,any类型是十分有用的,它允许你在编译时可选择地包含或移除类型检查。
1 | let notSure: any = 4; |
当你只知道一部分数据的类型时,any类型也是有用的。 比如,你有一个数组,它包含了不同的类型的数据:
1 | let list: any[] = [1, true, "free"]; |
变量如果在声明的时候,未指定其类型,那么它会被识别为任意值类型:
1 | let something; |
等价于
1 | let something: any; |
Void空值
某种程度上来说,void类型像是与any类型相反,它表示没有任何类型。 当一个函数没有返回值时,你通常会见到其返回值类型是 void:
1 | function warnUser(): void { |
声明一个void类型的变量没有什么大用,因为你只能为它赋予undefined和null:
1 | let unusable: void = undefined; |
Never
never 是其它类型(包括 null 和 undefined)的子类型,代表那些永不存在的值的类型。这意味着声明为 never 类型的变量只能被 never 类型所赋值。 例如, never类型是那些总是会抛出异常或根本就不会有返回值的函数表达式或箭头函数表达式的返回值类型;
1 | let x: never; |
类型断言
类型断言(Type Assertion)可以用来手动指定一个值的类型。
通过类型断言这种方式可以告诉编译器,“相信我,我知道自己在干什么”。 它没有运行时的影响,只是在编译阶段起作用。 类型断言会假设程序员,已经进行了必须的检查,让TypeScript跳过类型检测。
1 | 语法:<类型>值 或 值 as 类型 |
类型断言有两种形式。 其一是“尖括号”语法:
1 | let someValue: any = "this is a string"; |
另一个为as语法:
1 | let someValue: any = "this is a string"; |
例子一
1
2
3
4
5
6
7function func(val: string | number): number {
if (val.length) {
return val.length
} else {
return val.toString().length
}
}函数的参数 val 是一个联合类型,在这里的意思是说 val 可以是字符串类型也可以是数值类型。代码中要返回参数的长度,但是 length 是字符串的属性,而数值是没有这个属性的,所以当 val 是数值时,就先用 toSting() 来将数字转换为字符串再取长度。这样的逻辑本身没问题,但是在编译阶段一访问 val.length 时就报错了,因为 访问联合类型值的属性时,这个属性必须是所有可能类型的共有属性,而length不是共有属性,val 的类型此时也没确定,所以编译不通过。为了通过编译,此时就可以使用类型断言了
1
2
3
4
5
6
7function func(val: string | number): number {
if ((<string>val).length) {
return (<string>val).length
} else {
return val.toString().length
}
}例子二
1
2
3
4
5
6
7
8
9
10
11const foo = {};
foo.bar = 123; // Error: 'bar' 属性不存在于 ‘{}’
foo.bas = 'hello'; // Error: 'bas' 属性不存在于 '{}'
interface Foo {
bar: number;
bas: string;
}
const foo = {} as Foo;
foo.bar = 123;
foo.bas = 'hello';
const 断言
TypeScript 3.4 引入了一种新的字面量构造方式,也称为 const 断言。当我们使用 const 断言构造新的字面量表达式时,我们可以向编程语言发出以下信号
- 表达式中的任何字面量类型都不应该被扩展;
- 对象字面量的属性,将使用
readonly修饰; - 数组字面量将变成
readonly元组。
下面我们来举一个 const 断言的例子:
1 | let x = "hello" as const; |
类型断言的用途
- 将一个联合类型断言为其中一个类型
- 将一个父类断言为更加具体的子类
- 将任何一个类型断言为
any - 将
any断言为一个具体的类型
类型推论
如果没有明确的指定类型,那么 TypeScript 会依照类型推论(Type Inference)的规则推断出一个类型。
以下代码虽然没有指定类型,但是会在编译的时候报错:
1 | let myFavoriteNumber = 'seven'; |
事实上,它等价于:
1 | let myFavoriteNumber: string = 'seven'; |
TypeScript 会在没有明确的指定类型的时候推测出一个类型,这就是类型推论。
如果定义的时候没有赋值,不管之后有没有赋值,都会被推断成 any 类型而完全不被类型检查:
1 | let myFavoriteNumber; |
枚举
是什么
枚举是一个被命名的整型常数的集合,用于声明一组命名的常数,当一个变量有几种可能的取值时,可以将它定义为枚举类型。通俗来说,枚举就是一个对象的所有可能取值的集合。
在日常生活中也很常见,例如表示星期的SUNDAY、MONDAY、TUESDAY、WEDNESDAY、THURSDAY、FRIDAY、SATURDAY就可以看成是一个枚举。
枚举的说明与结构和联合相似,其形式为:
1 | enum 枚举名{ |
使用
枚举的使用是通过enum关键字进行定义,形式如下:
1 | enum xxx { ... } |
声明关键字为枚举类型的方式如下:
1 | // 声明d为枚举类型Direction |
类型可以分成:
- 数字枚举
- 字符串枚举
- 异构枚举
数字枚举
当我们声明一个枚举类型是,虽然没有给它们赋值,但是它们的值其实是默认的数字类型,而且默认从0开始依次累加:
1 | enum Direction { |
如果我们将第一个值进行赋值后,后面的值也会根据前一个值进行累加1:
1 | enum Direction { |
字符串枚举
1 | 枚举类型的值其实也可以是字符串类型: |
如果设定了一个变量为字符串之后,后续的字段也需要赋值字符串,否则报错:
1 | enum Direction { |
异构枚举
即将数字枚举和字符串枚举结合起来混合起来使用,如下:
1 | enum BooleanLikeHeterogeneousEnum { |
通常情况下我们很少会使用异构枚举
本质
现在一个枚举的案例如下:
1 | enum Direction { |
通过编译后,javascript如下:
1 | var Direction; |
上述代码可以看到, Direction[Direction["Up"] = 0] = "Up"可以分成
- Direction[“Up”] = 0
- Direction[0] = “Up”
所以定义枚举类型后,可以通过正反映射拿到对应的值,如下:
1 | enum Direction { |
并且多处定义的枚举是可以进行合并操作,如下:
1 | enum Direction { |
编译后,js代码如下:
1 | var Direction; |
可以看到,Direction对象属性回叠加
1 | { |
应用场景
就拿回生活的例子,后端返回的字段使用 0 - 6 标记对应的日期,这时候就可以使用枚举可提高代码可读性,如下:
1 | enum Days {Sun, Mon, Tue, Wed, Thu, Fri, Sat}; |
包括后端日常返回0、1 等等状态的时候,我们都可以通过枚举去定义,这样可以提高代码的可读性,便于后续的维护
1 | /** |
TypeScript 命名空间
命名空间一个最明确的目的就是解决重名问题。
假设这样一种情况,当一个班上有两个名叫小明的学生时,为了明确区分它们,我们在使用名字之外,不得不使用一些额外的信息,比如他们的姓(王小明,李小明),或者他们父母的名字等等。
命名空间定义了标识符的可见范围,一个标识符可在多个命名空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的命名空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其他命名空间中。
TypeScript 中命名空间使用 namespace 来定义,语法格式如下:
1 | namespace SomeNameSpaceName { |
以上定义了一个命名空间 SomeNameSpaceName,如果我们需要在外部可以调用 SomeNameSpaceName 中的类和接口,则需要在类和接口添加 export 关键字。
要在另外一个命名空间调用语法格式为:
1 | SomeNameSpaceName.SomeClassName; |
如果一个命名空间在一个单独的 TypeScript 文件中,则应使用三斜杠 /// 引用它,语法格式如下:
1 | /// <reference path = "SomeFileName.ts" /> |
以下实例演示了命名空间的使用,定义在不同文件中:
1 | IShape.ts 文件代码: |
接口
作用:
- 对“对象”进行约束描述
- 对“类”的一部分行为进行抽象
特点:
接口与值的结构必须相同
1
2
3
4
5
6
7
8
9
10
11
12
13interface LabelledValue {
size: number;
label: string;
}
function printLabel(labelledObj: LabelledValue) {
console.log(labelledObj.label);
}
let myObj1 = { label: "Size 10 Object" };
let myObj2 = { label: "Size 10 Object", other:1 };
//少了
printLabel(myObj1);
//多了
printLabel(myObj2);可以捕获引用了不存在的属性时的错误
1
2
3
4
5
6
7
8
9interface LabelledValue {
size: number;
label: string;
}
function printLabel(labelledObj: LabelledValue) {
console.log(labelledObj.labell);
}
let myObj = { size:10, label: "Size 10 Object" };
printLabel(myObj);
可选属性
接口里的属性不全都是必需的。 有些是只在某些条件下存在,或者根本不存在。 可选属性在应用“option bags”模式时很常用,即给函数传入的参数对象中只有部分属性赋值了。
下面是应用了“option bags”的例子:
1 | interface SquareConfig { |
带有可选属性的接口与普通的接口定义差不多,只是在可选属性名字定义的后面加一个?符号。
只读属性
一些对象属性只能在对象刚刚创建的时候修改其值。 你可以在属性名前用 readonly来指定只读属性:
1 | interface Point { |
你可以通过赋值一个对象字面量来构造一个Point。 赋值后, x和y再也不能被改变了。
1 | let p1: Point = { x: 10, y: 20 }; |
TypeScript具有ReadonlyArray<T>类型,它与Array<T>相似,只是把所有可变方法去掉了,因此可以确保数组创建后再也不能被修改:
1 | let a: number[] = [1, 2, 3, 4]; |
上面代码的最后一行,可以看到就算把整个ReadonlyArray赋值到一个普通数组也是不可以的。 但是你可以用类型断言重写:
1 | a = ro as number[]; |
readonly vs const
最简单判断该用readonly还是const的方法是看要把它做为变量使用还是做为一个属性。 做为变量使用的话用 const,若做为属性则使用readonly。
额外的属性检查
1 | interface SquareConfig { |
注意传入createSquare的参数拼写为*colour*而不是color。 在JavaScript里,这会默默地失败。 编译器能够捕获引用了未声明属性的错误
1 | // error: 'colour' not expected in type 'SquareConfig' |
解决
- 最简便的方法是使用类型断言:
1 | let mySquare = createSquare({ width: 100, opacity: 0.5 } as SquareConfig); |
- 加上额外属性声明,允许对象引用除可选属性以外的其他属性
1 | interface SquareConfig { |
可索引的类型
与使用接口描述函数类型差不多,我们也可以描述那些能够“通过索引得到”的类型,比如a[10]或ageMap["daniel"]。 可索引类型具有一个 索引签名,它描述了对象索引的类型,还有相应的索引返回值类型。
1 | // 数字索引——约束数组 |
字符串索引签名能够很好的描述dictionary模式,并且它们也会确保所有属性与其返回值类型相匹配。 因为字符串索引声明了 obj.property和obj["property"]两种形式都可以。 下面的例子里, name的类型与字符串索引类型不匹配,所以类型检查器给出一个错误提示:
1 | interface NumberDictionary { |
最后,你可以将索引签名设置为只读,这样就防止了给索引赋值:
1 | interface ReadonlyStringArray { |
你不能设置myArray[2],因为索引签名是只读的。
Element implicitly has an ‘any‘ type because expression of type ‘string‘ can‘t be used to index type
英文报错:Element implicitly has an ‘any’ type because expression of type ‘string’ can’t be used to index type
中文报错:元素隐式具有 “any” 类型,因为类型为 “string” 的表达式不能用于索引类型 “UserInfo”。
1 | interface UserInfo { |
1 | let userInfo: UserInfo = { |
函数类型
为了使用接口表示函数类型,我们需要给接口定义一个调用签名。 具体的格式是一个只有参数列表和返回值类型的函数定义。参数列表里的每个参数都需要名字和类型。
1 | interface Func { |
这样定义后,我们可以像使用其它接口一样使用这个函数类型的接口。 下例展示了如何创建一个函数类型的变量,并将一个同类型的函数赋值给这个变量。
1 | const myFunc: Func = function(param1, param2){ |
对于函数类型的类型检查来说,函数的参数名不需要与接口里定义的名字相匹配。 比如,我们使用下面的代码重写上面的例子:
1 | interface Func { |
继承接口
和类一样,接口也可以相互继承。 这让我们能够从一个接口里复制成员到另一个接口里,可以更灵活地将接口分割到可重用的模块里。
1 | interface Shape { |
一个接口可以继承多个接口,创建出多个接口的合成接口。
1 | interface Shape { |
类类型
接口描述了类的公共部分,而不是公共和私有两部分。 它不会帮你检查类是否具有某些私有成员。
implements实现类接口
类可以实现(implement)接口。通过接口,你可以强制地指明类遵守某个契约。你可以在接口中声明一个方法,然后要求类去具体实现它。一个类只能继承自另一个类,有时候不同类之间可以有一些共有的特性,这时候就可以把特性提取成接口(interfaces),用
implements关键字来实现
举例来说,门是一个类,防盗门是门的子类。如果防盗门有一个报警器的功能,我们可以简单的给防盗门添加一个报警方法。这时候如果有另一个类,车,也有报警器的功能,就可以考虑把报警器提取出来,作为一个接口,防盗门和车都去实现它:
1 | //定义类 |
一个类可以实现多个接口,下例中,Car 实现了 Alarm 和 Light 接口,既能报警,也能开关车灯:
1 | //定义类 |
extends继承类接口
接口可以继承接口,下例中,我们使用 extends 使 LightableAlarm 继承 Alarm:
1 | interface Alarm { |
接口继承类
接口也可以继承类:
1 | class Point { |
为什么 TypeScript 会支持接口继承类呢?
实际上,当我们在声明 class Point 时,除了会创建一个名为 Point 的类之外,同时也创建了一个名为 Point 的类型(实例的类型)。
所以我们既可以将 Point 当做一个类来用(使用 new Point 创建它的实例),也可以将 Point 当做一个类型来用(使用 : Point 表示参数的类型)
函数
函数类型
为函数定义类型
1 | // 函数声明 |
书写完整函数类型
现在我们已经为函数指定了类型,下面让我们写出函数的完整类型。
1 | let myAdd: (x: number, y: number) => number = function(x: number, y: number): number { return x + y; }; |
函数类型包含两部分:参数类型和返回值类型。 当写出完整函数类型的时候,这两部分都是需要的
1 | let myAdd: (baseValue: number, increment: number) => number = |
只要参数类型是匹配的,那么就认为它是有效的函数类型,而不在乎参数名是否正确。
推断类型
如果你在赋值语句的一边指定了类型但是另一边没有类型的话,TypeScript编译器会自动识别出类型:
1 | // myAdd has the full function type |
这叫做“按上下文归类”,是类型推论的一种。
可选参数
前面提到,输入多余的(或者少于要求的)参数,是不允许的。那么如何定义可选的参数呢?
与接口中的可选属性类似,我们用 ? 表示可选的参数:
1 | function buildName(firstName: string, lastName?: string) { |
需要注意的是,可选参数必须接在必需参数后面。换句话说,可选参数后面不允许再出现必需参数了:
1 | function buildName(firstName?: string, lastName: string) { |
默认参数
在 ES6 中,我们允许给函数的参数添加默认值,TypeScript 会将添加了默认值的参数识别为可选参数:
1 | function buildName(firstName: string, lastName: string = 'Cat') { |
此时就不受「可选参数必须接在必需参数后面」的限制了:
1 | function buildName(firstName: string = 'Tom', lastName: string) { |
剩余参数
ES6 中,可以使用 ...rest 的方式获取函数中的剩余参数(rest 参数):
1 | function push(array, ...items) { |
事实上,items 是一个数组。所以我们可以用数组的类型来定义它:
1 | function push(array: any[], ...items: any[]) { |
注意,rest 参数只能是最后一个参数,关于 rest 参数,可以参考 ES6 中的 rest 参数。
this
学习如何在JavaScript里正确使用this就好比一场成年礼。 由于TypeScript是JavaScript的超集,TypeScript程序员也需要弄清 this工作机制并且当有bug的时候能够找出错误所在。 幸运的是,TypeScript能通知你错误地使用了 this的地方。 如果你想了解JavaScript里的 this是如何工作的,那么首先阅读Yehuda Katz写的Understanding JavaScript Function Invocation and “this”。 Yehuda的文章详细的阐述了 this的内部工作原理,因此我们这里只做简单介绍。
this和箭头函数
JavaScript里,this的值在函数被调用的时候才会指定。 这是个既强大又灵活的特点,但是你需要花点时间弄清楚函数调用的上下文是什么。 但众所周知,这不是一件很简单的事,尤其是在返回一个函数或将函数当做参数传递的时候。
下面看一个例子:
1 | let deck = { |
可以看到createCardPicker是个函数,并且它又返回了一个函数。 如果我们尝试运行这个程序,会发现它并没有弹出对话框而是报错了。 因为 createCardPicker返回的函数里的this被设置成了window而不是deck对象。 因为我们只是独立的调用了 cardPicker()。 顶级的非方法式调用会将 this视为window。 (注意:在严格模式下, this为undefined而不是window)。
为了解决这个问题,我们可以在函数被返回时就绑好正确的this。 这样的话,无论之后怎么使用它,都会引用绑定的‘deck’对象。 我们需要改变函数表达式来使用ECMAScript 6箭头语法。 箭头函数能保存函数创建时的 this值,而不是调用时的值:
1 | let deck = { |
更好事情是,TypeScript会警告你犯了一个错误,如果你给编译器设置了--noImplicitThis标记。 它会指出 this.suits[pickedSuit]里的this的类型为any。
this参数
不幸的是,this.suits[pickedSuit]的类型依旧为any。 这是因为 this来自对象字面量里的函数表达式。 修改的方法是,提供一个显式的 this参数。 this参数是个假的参数,它出现在参数列表的最前面:
1 | function f(this: void) { |
让我们往例子里添加一些接口,Card 和 Deck,让类型重用能够变得清晰简单些:
1 | interface Card { |
现在TypeScript知道createCardPicker期望在某个Deck对象上调用。 也就是说 this是Deck类型的,而非any,因此--noImplicitThis不会报错了。
this参数在回调函数里
你可以也看到过在回调函数里的this报错,当你将一个函数传递到某个库函数里稍后会被调用时。 因为当回调被调用的时候,它们会被当成一个普通函数调用, this将为undefined。 稍做改动,你就可以通过 this参数来避免错误。 首先,库函数的作者要指定 this的类型:
1 | interface UIElement { |
this: void means that addClickListener expects onclick to be a function that does not require a this type. Second, annotate your calling code with this:
1 | class Handler { |
指定了this类型后,你显式声明onClickBad必须在Handler的实例上调用。 然后TypeScript会检测到 addClickListener要求函数带有this: void。 改变 this类型来修复这个错误:
1 | class Handler { |
因为onClickGood指定了this类型为void,因此传递addClickListener是合法的。 当然了,这也意味着不能使用 this.info. 如果你两者都想要,你不得不使用箭头函数了:
1 | class Handler { |
这是可行的因为箭头函数不会捕获this,所以你总是可以把它们传给期望this: void的函数。 缺点是每个 Handler对象都会创建一个箭头函数。 另一方面,方法只会被创建一次,添加到 Handler的原型链上。 它们在不同 Handler对象间是共享的。
重载
重载允许一个函数接受不同数量或类型的参数时,作出不同的处理。
比如,我们需要实现一个函数 reverse,输入数字 123 的时候,输出反转的数字 321,输入字符串 'hello' 的时候,输出反转的字符串 'olleh'。
利用联合类型,我们可以这么实现:
1 | function reverse(x: number | string): number | string { |
然而这样有一个缺点,就是不能够精确的表达,输入为数字的时候,输出也应该为数字,输入为字符串的时候,输出也应该为字符串。
这时,我们可以使用重载定义多个 reverse 的函数类型:为同一个函数提供多个函数类型定义来进行函数重载。 编译器会根据这个列表去处理函数的调用
1 | function reverse(x: number): number; |
泛型
介绍
考虑可重用性。 组件不仅能够支持当前的数据类型,同时也能支持未来的数据类型
泛型(Generics)是指在定义函数、接口或类的时候,不预先指定具体的类型,而在使用的时候再指定类型的一种特性。
当我们需要写一个传入什么类型就得到什么类型的函数
```ts
function one(a: any) : any{
return a;
}1
2
3
4
5
6
7
8
9
10
- ```ts
function one(a: any) : any{
if(typeof a === 'number') {
let ret = (a as number)
return ret ;
}
return a;
}
//每一种类型都写一个方法```ts
function one(a: T) : T{ return a;}
let a1 = one(1)
let a2 = one(520)
//描述T是什么类型的时候,可以在描述它是一个number类型,
//也可以类型推论1
2
3
4
5
6
7
8
9
10
### 使用泛型变量
如果我们想同时打印出`arg`的长度。 我们很可能会这样做:
```ts
function loggingIdentity<T>(arg: T): T {
console.log(arg.length); // Error: T doesn't have .length
return arg;
}
如果这么做,编译器会报错说我们使用了arg的.length属性,但是没有地方指明arg具有这个属性。 记住,这些类型变量代表的是任意类型,所以使用这个函数的人可能传入的是个数字,而数字是没有 .length属性的。
现在假设我们想操作是T类型的数组而不直接是T。由于我们操作的是数组,所以.length属性是应该存在的。 我们可以像创建其它数组一样创建这个数组:
1 | function loggingIdentity<T>(arg: T[]): T[] { |
泛型类型
泛型函数的类型与非泛型函数的类型没什么不同,只是有一个类型参数在最前面,像函数声明一样:
1 | function identity<T>(arg: T): T { |
我们也可以使用不同的泛型参数名,只要在数量上和使用方式上能对应上就可以。
1 | function identity<T>(arg: T): T { |
我们还可以使用带有调用签名的对象字面量来定义泛型函数:
1 | function identity<T>(arg: T): T { |
这引导我们去写第一个泛型接口了。 我们把上面例子里的对象字面量拿出来做为一个接口:
1 | interface GenericIdentityFn { |
一个相似的例子,我们可以把泛型参数当作整个接口的一个参数。 这样我们就能清楚的知道使用的具体是哪个泛型类型(比如: Dictionary<string>而不只是Dictionary)。 这样接口里的其它成员也能知道这个参数的类型了。
1 | interface GenericIdentityFn<T> { |
泛型类
泛型类看上去与泛型接口差不多。 泛型类使用( <>)括起泛型类型,跟在类名后面。
1 | class GenericNumber<T> { |
类有两部分:静态部分和实例部分。 泛型类指的是实例部分的类型,所以类的静态属性不能使用这个泛型类型。
泛型约束extends
你应该会记得之前的一个例子,我们有时候想操作某类型的一组值,并且我们知道这组值具有什么样的属性。 在 loggingIdentity例子中,我们想访问arg的length属性,但是编译器并不能证明每种类型都有length属性,所以就报错了。
1 | function loggingIdentity<T>(arg: T): T { |
相比于操作any所有类型,我们想要限制函数去处理任意带有.length属性的所有类型。 只要传入的类型有这个属性,我们就允许,就是说至少包含这一属性。 为此,我们需要列出对于T的约束要求。
为此,我们定义一个接口来描述约束条件。 创建一个包含 .length属性的接口,使用这个接口和extends关键字来实现约束:
1 | interface Lengthwise { |
现在这个泛型函数被定义了约束,因此它不再是适用于任意类型:
1 | loggingIdentity(3); // Error, 类型“number”的参数不能赋给类型“Lengthwise”的参数。 |
我们需要传入符合约束类型的值,必须包含必须的属性:
1 | loggingIdentity({length: 10, value: 3}); |
案例
Promise的泛型T(Promise
)的含义 interface AxiosInstance { <T = any>(value: T): Promise
} Promise的泛型T代表promise变成成功态之后resolve的值,resolve(value)
高级类型
交叉类型
交叉类型是将多个类型合并为一个类型。 这让我们可以把现有的多种类型叠加到一起成为一种类型,它包含了所需的所有类型的特性。 例如,type是type1和type2接口的交集。 就是说这个类型的对象同时拥有了这二种类型的成员。
1 | interface type1{ |
1 | interface type1{ |
联合类型
联合类型(Union Types)表示取值可以为多种类型中的一种。
简单的例子
1 | let myFavoriteNumber: string | number; |
联合类型使用 | 分隔每个类型。
这里的 let myFavoriteNumber: string | number 的含义是,允许 myFavoriteNumber 的类型是 string 或者 number,但是不能是其他类型。
访问联合类型的属性或方法
当 TypeScript 不确定一个联合类型的变量到底是哪个类型的时候,我们只能访问此联合类型的所有类型里共有的属性或方法:
1 | function getLength(something: string | number): number { |
上例中,length 不是 string 和 number 的共有属性,所以会报错。
访问 string 和 number 的共有属性是没问题的:
1 | function getString(something: string | number): string { |
联合类型的变量在被赋值的时候,会根据类型推论的规则推断出一个类型:
1 | let myFavoriteNumber: string | number; |
上例中,第二行的 myFavoriteNumber 被推断成了 string,访问它的 length 属性不会报错。
而第四行的 myFavoriteNumber 被推断成了 number,访问它的 length 属性时就报错了。
typeof类型保护
instanceof类型保护
instanceof类型保护是通过构造函数来细化类型的一种方式。 比如,我们借鉴一下之前字符串填充的例子:
1 | interface Padder { |
instanceof的右侧要求是一个构造函数,TypeScript将细化为:
- 此构造函数的
prototype属性的类型,如果它的类型不为any的话 - 构造签名所返回的类型的联合
以此顺序。
类型别名type
type关键字
说明:字面意思,用来给一个类型起个新名字。生成一个接口
1 | type str1 = string; |
类型别名会给一个类型起个新名字。 类型别名有时和接口很像,但是可以作用于原始值,联合类型,元组以及其它任何你需要手写的类型。
1 | type Name = string; |
起别名不会新建一个类型 - 它创建了一个新 名字来引用那个类型。 给原始类型起别名通常没什么用,尽管可以做为文档的一种形式使用。
同接口一样,类型别名也可以是泛型 - 我们可以添加类型参数并且在别名声明的右侧传入:
1 | type Container<T> = { value: T }; |
我们也可以使用类型别名来在属性里引用自己:
1 | type Tree<T> = { |
与交叉类型一起使用,我们可以创建出一些十分稀奇古怪的类型。
1 | type LinkedList<T> = T & { next: LinkedList<T> }; |
然而,类型别名不能出现在声明右侧的任何地方。
1 | type Yikes = Array<Yikes>; // error |
type 与 interface 的区别
相同点:
- 都可以描述一个对象或者函数
- 都允许拓展(extends和交叉类型)
不同点:
- type 可以声明基本类型别名,联合类型,元组等类型
- type 语句中还可以使用 typeof 获取实例的类型进行赋值
- interface 能够声明合并
相似的
type 用于定义数据的类型别名。interface 用于定义数据的类型别名。
1 | type User = { |
不相似的
type 与 interface 都可以实现继承,但是他们的表现形式不同。
1 | //interface extends interface |
因为 type 作为类型的别名,因此可以轻易的实现声明基本类型别名,联合类型,元组等类型,而 interface 则不行。
1 | // 基本类型别名 |
interface 能够声明合并,而 type 不行(会报重复声明错误)。
1 | interface User { |
编程题
代码合集收藏
https://mp.weixin.qq.com/s/w9iLd56H4xyXSlRwiKs04g
异步
async
1 | //在async中将异步的代码同步执行 |
1 | 1 at quokka.js:2:2 |
1 | async function f1(){ |
1 | 1 at quokka.js:9:1 |
promise
1 | let a = new Promise((resolve, reject) => { |
1 | 1 at quokka.js:2:3 |
1 | new Promise((resolved,reject)=>{ |
1 | 1 at quokka.js:2:3 |
1 | new Promise((resolved, reject) => { |
1 | [Error: x 必须为正数] at res quokka.js:6:3 |
时间空间复杂度
log:https://blog.csdn.net/weixin_39888180/article/details/111268391
时间复杂度
其实就是一个函数,用大 O 表示, 比如 O(1)、 O(n)…
它的作用就是用来定义描述算法的运行时间
- O(1)
1 | let i = 0 |
- O(n): 如果是 O(1) + O(n) 则还是 O(n)
1 | for (let i = 0; i < n; i += 1) { |
- O(n^2): O(n) * O(n), 也就是双层循环,自此类推:O(n^3)…
1 | for (let i = 0; i < n; i += 1) { |
- O(logn): 就是求 log 以 2 为底的多少次方等于 n
1 | // 这个例子就是求2的多少次方会大于i,然后就会结束循环。 这就是一个典型的 O(logn) |
空间复杂度
和时间复杂度一样,空间复杂度也是用大 O 表示,比如 O(1)、 O(n)…
它用来定义描述算法运行过程中临时占用的存储空间大小
占用越少 代码写的就越好
- O(1): 单个变量,所以占用永远是 O(1)
1 | let i = 0 |
- O(n): 声明一个数组, 添加 n 个值, 相当于占用了 n 个空间单元
1 | const arr = [] |
- O(n^2): 类似一个矩阵的概念,就是二维数组的意思
1 | const arr = [] |
查找
二分法
二分法查找是一种速度非常快的算法,但是它有固定的应用范围。仅当列表是有序的时候,二分查找才管用。
采用二分法,取出中间数,数组每次和中间数比较,小的放到左边,大的放到右边
排序
快速排序
- (1)在数据集之中,找一个基准点
- (2)建立两个数组,分别存储左边和右边的数组
- (3)利用递归进行下次比较
1 | var arr = [3, 1, 4, 6, 5, 7, 2]; |
深拷贝与浅拷贝
https://mp.weixin.qq.com/s/BQ3_RJQcCZiXphMoyMRaTg
基本数据类型的特点:直接存储在栈(stack)中的数据
引用数据类型的特点:存储的是该对象在栈中引用地址,真实的数据存放在堆内存里。引用数据类型在栈中存储了指针,指针指向堆中该实体的起始地址
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
实现浅拷贝
浅拷贝只拷贝基本数据的内容,引用数据虽然栈不同但会共用一个堆
Object.assign()
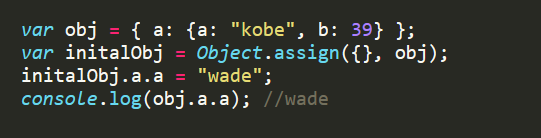
注意:当object只有一层的时候,是深拷贝
展开运算符…
1 | let obj1 = { name: 'Kobe', address:{x:100,y:100}} |
concat()
1 | let arr = [1, 3, { |
slice()
1 | let arr =[1,{username:'kobe'}] |
实现深拷贝

1 | function checkedType(e) { |
1 | function deepClone(obj, newObj) { |
1 | function deepClone(source) { |
1 | JSON.parse(JSON.stringify(xxx)) |
递归
阶乘
1 | const factorial = function(n) { |
f(6) = n * f(5),所以 f(6) 需要拆解成 f(5) 子问题进行求解,以此类推 f(5) = n * f(4) ,也需要进一步拆分 … 直到 f(1),「这是递的过程。」 f(1) 解决后,依次可以解决f(2)…. f(n)最后也被解决,「这是归的过程。」
归无非就是把问题拆解成具有相同解决思路的子问题,直到最后被拆解的子问题不能够拆分,这个过程是“递”。当解决了最小粒度可求解的子问题后,在“归”的过程中顺其自然的解决了最开始的问题。
复杂度分析
- 空间复杂度为 O(n)
- 时间复杂度 O(2^n)
1 | 总时间 = 子问题个数 * 解决一个子问题需要的时间 |
- 子问题个数即递归树中的节点总数 2^n
- 解决一个子问题需要的时间,因为只有一个加法操作
fib(n-1) + fib(n-2),所以解决一个子问题的时间为O(1)
二者相乘,得出算法的时间复杂度为 O(2^n)
实现深拷贝
1 | function deepClone(obj, newObj) { |
1 | function deepClone(source) { |
1 | JSON.parse(JSON.stringify(xxx)) |
树形结构
1 | const input = [ |
获取树的叶子节点并赋值到树结构中
1 | const input = [ |
根据id,拿到id数组
1 | // (tree为目标树,targetId为目标节点id) |
案例
使用递归实现
getElementsByClassName1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16let arr = [];
function byClass(node, className, arr){
//得到传入节点的所有子节点
var lists = node.childNodes;
for(var i = 0;i< lists.length;i++){
//判断是否有相同className元素
if(arr[i],className == className){
arr.push(arr[i]);
}
//判断子节点是否还有子节点
if(arr[i].childNodes.length > 0){
byClass(arr[i],className,arr);
}
}
}
复制代码有一堆桃子,每天吃掉一半,挑出一个坏的扔掉,第6天的时候发现还剩1个桃子,问原来有多少个桃子。
1 | function fn(n) { |
